PostgreSQL Streaming Replication je skvělý způsob škálování klastrů PostgreSQL a přidává jim vysokou dostupnost. Jako u každé replikace je myšlenkou, že slave je kopií mastera a že slave je neustále aktualizován o změny, ke kterým došlo na masteru, pomocí nějakého replikačního mechanismu.
Může se stát, že se slave z nějakého důvodu nesynchronizuje s masterem. Jak jej mohu vrátit zpět do replikačního řetězce? Jak mohu zajistit, aby byla podřízená jednotka opět synchronizována s hlavní jednotkou? Podívejme se na tento krátký blogový příspěvek.
Co je velmi užitečné, neexistuje způsob, jak zapisovat na slave zařízení, pokud je v režimu obnovy. Můžete to otestovat takto:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionStejně se může stát, že se slave přestane synchronizovat s masterem. Poškození dat – hardware ani software nejsou bez chyb a problémů. Některé problémy s diskovou jednotkou mohou způsobit poškození dat na podřízeném zařízení. Některé problémy s „vakuovým“ procesem mohou vést ke změně dat. Jak se z tohoto stavu zotavit?
Přestavba Slave pomocí pg_basebackup
Hlavním krokem je zřízení slave pomocí dat z mastera. Vzhledem k tomu, že budeme používat replikaci streamování, nemůžeme použít logické zálohování. Naštěstí existuje připravený nástroj, který lze použít k nastavení:pg_basebackup. Podívejme se, jaké kroky musíme podniknout, abychom zřídili podřízený server. Aby bylo jasno, pro účely tohoto blogového příspěvku používáme PostgreSQL 12.
Počáteční stav je jednoduchý. Náš otrok se nereplikuje od svého pána. Data, která obsahuje, jsou poškozená a nelze je použít ani jim důvěřovat. Proto prvním krokem, který uděláme, bude zastavit PostgreSQL na našem slave a odstranit data, která obsahuje:
example@sqldat.com:~# systemctl stop postgresqlNebo dokonce:
example@sqldat.com:~# killall -9 postgresNyní se podíváme na obsah souboru postgresql.auto.conf, později můžeme použít přihlašovací údaje k replikaci uložené v tomto souboru pro pg_basebackup:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Zajímá nás uživatel a heslo použité pro nastavení replikace.
Konečně můžeme data odstranit:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*Jakmile budou data odstraněna, musíme použít pg_basebackup k získání dat z hlavního serveru:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointPříznaky, které jsme použili, mají následující význam:
- -Xs: Chtěli bychom streamovat WAL během vytváření zálohy. To pomáhá vyhnout se problémům s odstraňováním souborů WAL, když máte velkou datovou sadu.
- -P: chtěli bychom vidět průběh zálohování.
- -R: chceme, aby pg_basebackup vytvořil soubor standby.signal a připravil soubor postgresql.auto.conf s nastavením připojení.
pg_basebackup počká na kontrolní bod před zahájením zálohování. Pokud to trvá příliš dlouho, můžete použít dvě možnosti. Nejprve je možné nastavit režim kontrolního bodu na rychlý v pg_basebackup pomocí volby „-c fast“. Případně můžete vynutit kontrolní bod spuštěním:
postgres=# CHECKPOINT;
CHECKPOINTTak či onak se pg_basebackup spustí. Pomocí parametru -P můžeme sledovat průběh:
416906/1588478 kB (26%), 0/1 tablespaceceaceJakmile je záloha připravena, vše, co musíme udělat, je ujistit se, že obsah datového adresáře má přiřazeného správného uživatele a skupinu - spustili jsme pg_basebackup jako 'root', proto jej chceme změnit na 'postgres ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/To je vše, můžeme spustit slave a ten by se měl začít replikovat z mastera.
example@sqldat.com:~# systemctl start postgresqlPostup replikace můžete znovu zkontrolovat provedením následujícího dotazu na hlavním serveru:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Jak vidíte, oba otroci se správně replikují.
Přestavba Slave pomocí ClusterControl
Pokud jste uživatelem ClusterControl, můžete snadno dosáhnout přesně stejného pouhým výběrem možnosti z uživatelského rozhraní.
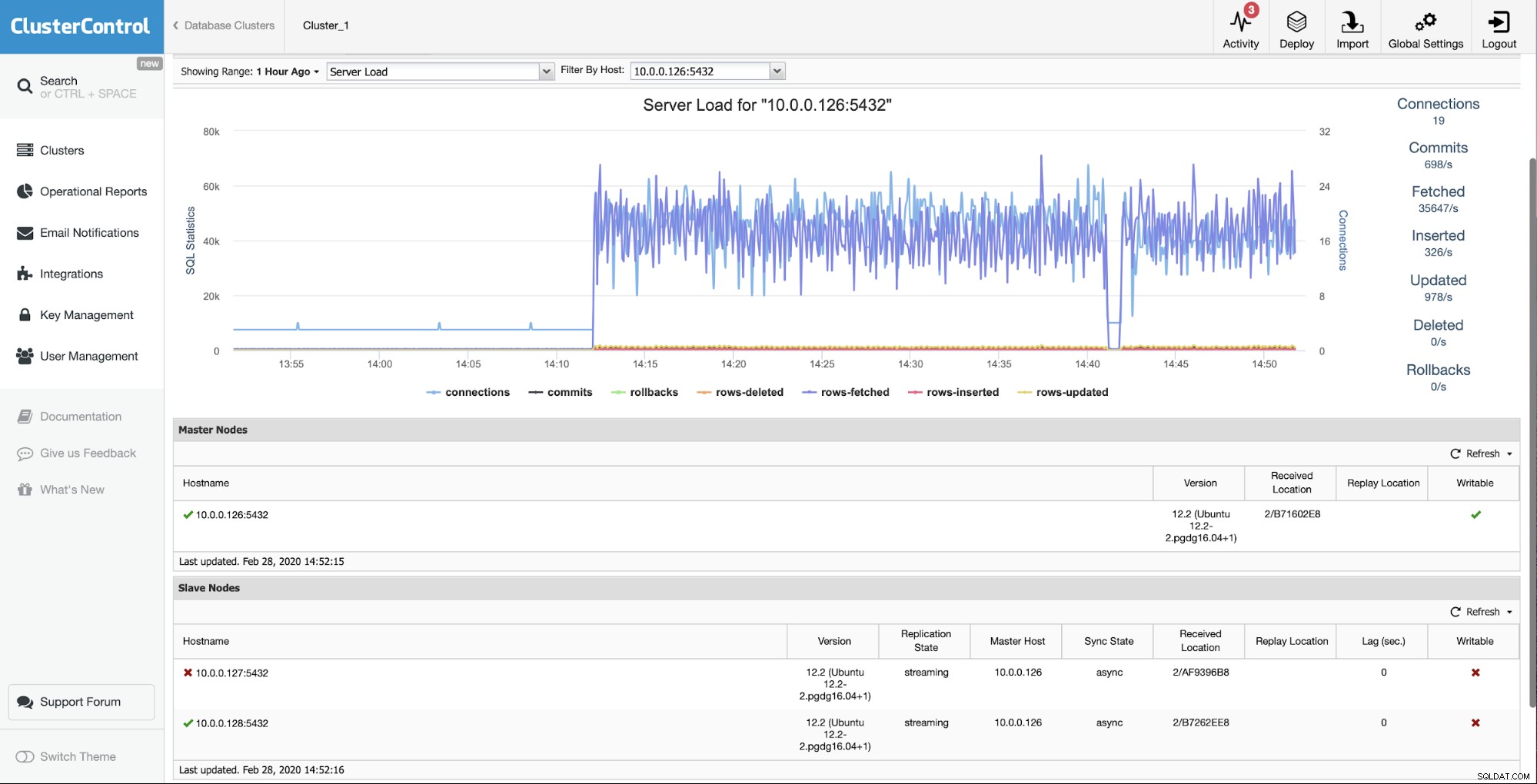
Výchozí situace je, že jeden z otroků (10.0.0.127) je nefunguje a nereplikuje se. Usoudili jsme, že přestavba je pro nás tou nejlepší možností.
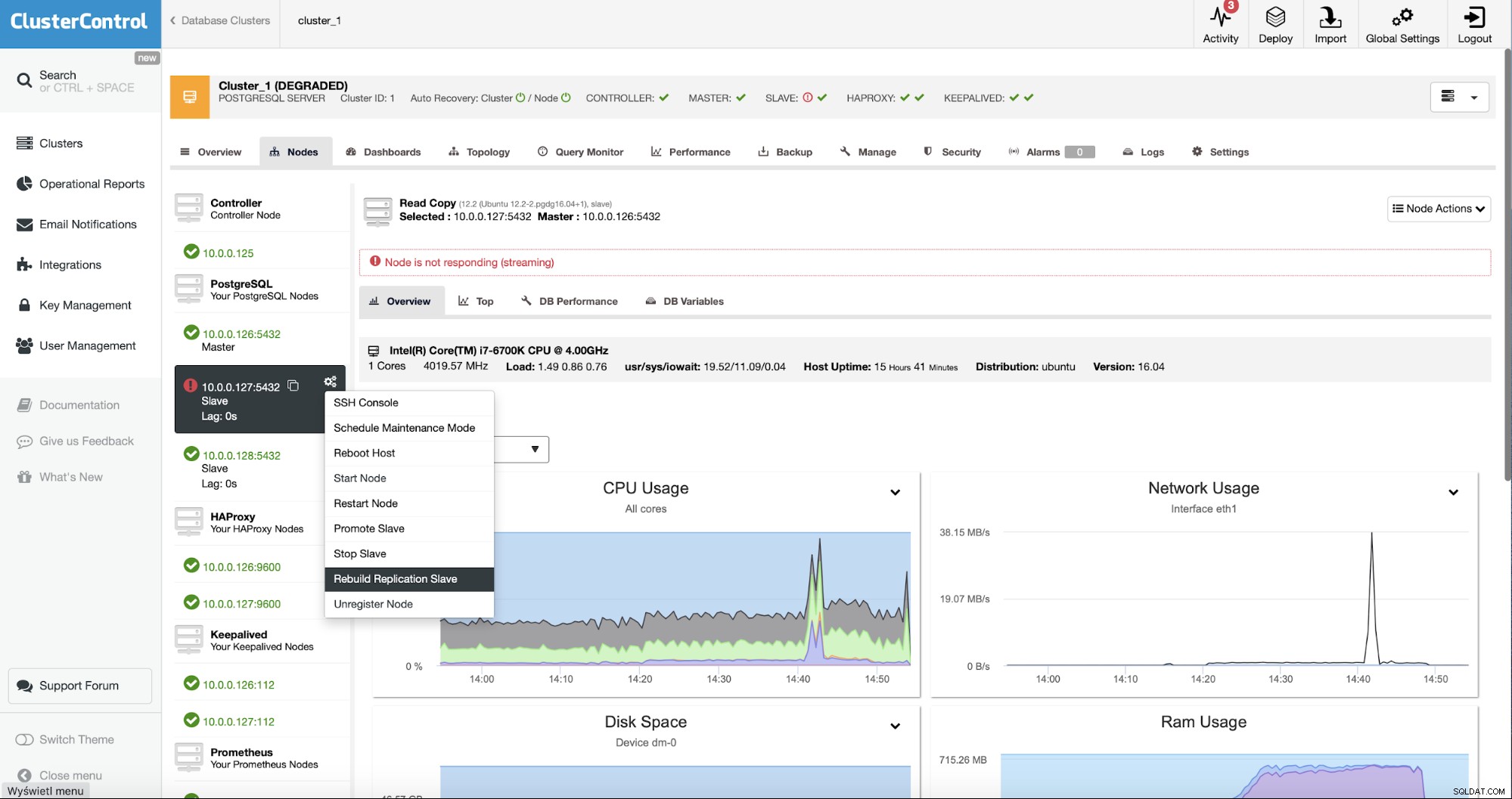
Jako uživatelé ClusterControl vše, co musíme udělat, je přejít na „Nodes “ a spusťte úlohu „Rebuild Replication Slave“.
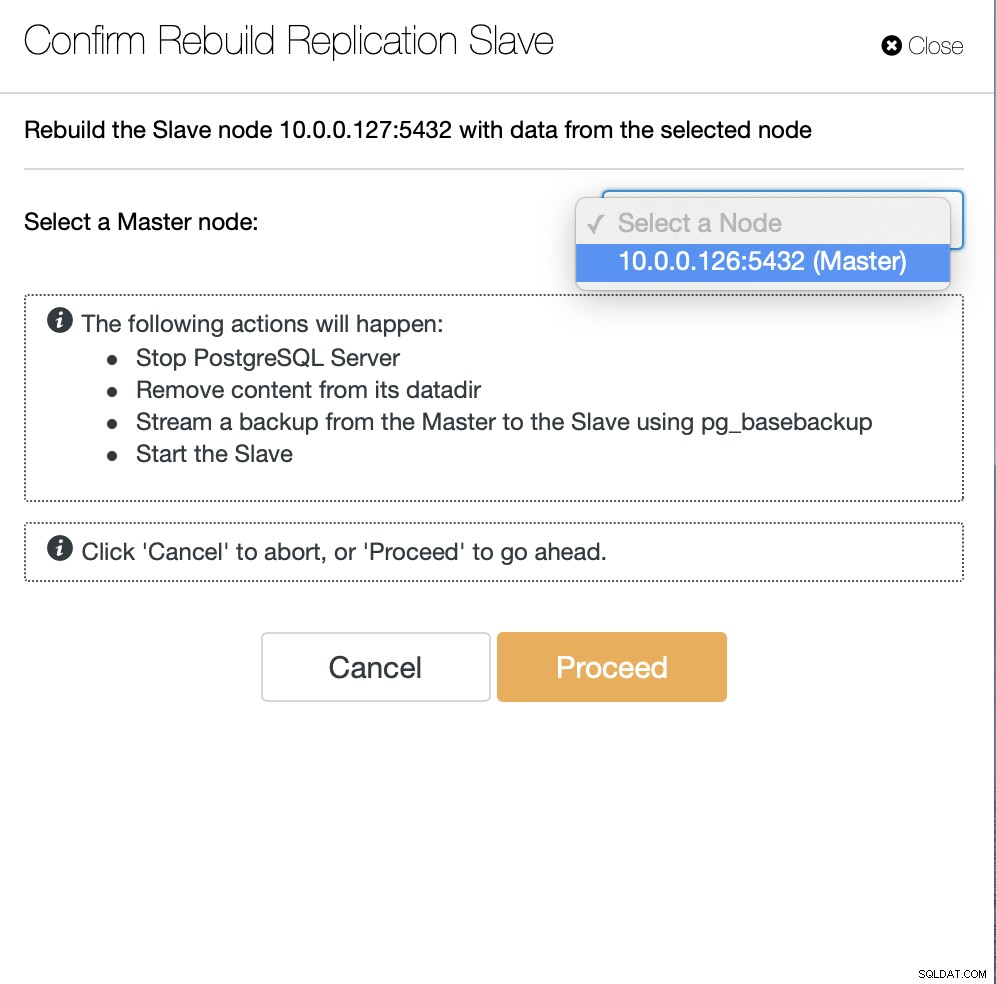
Dále musíme vybrat uzel, ze kterého se má znovu sestavit slave, a to je Všechno. ClusterControl použije pg_basebackup k nastavení slave replikace a konfiguraci replikace, jakmile budou data přenesena.
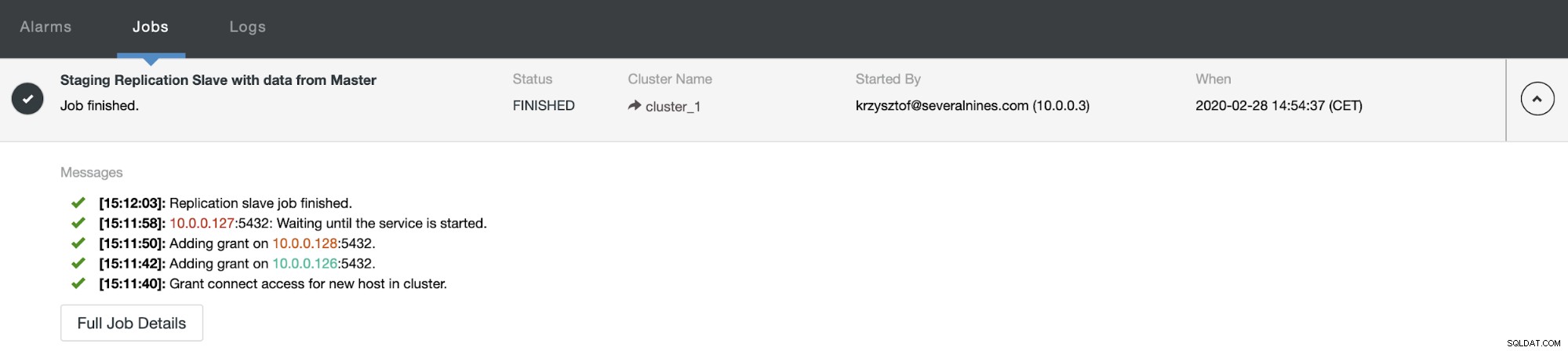
Po nějaké době se úloha dokončí a slave je zpět v replikačním řetězci:
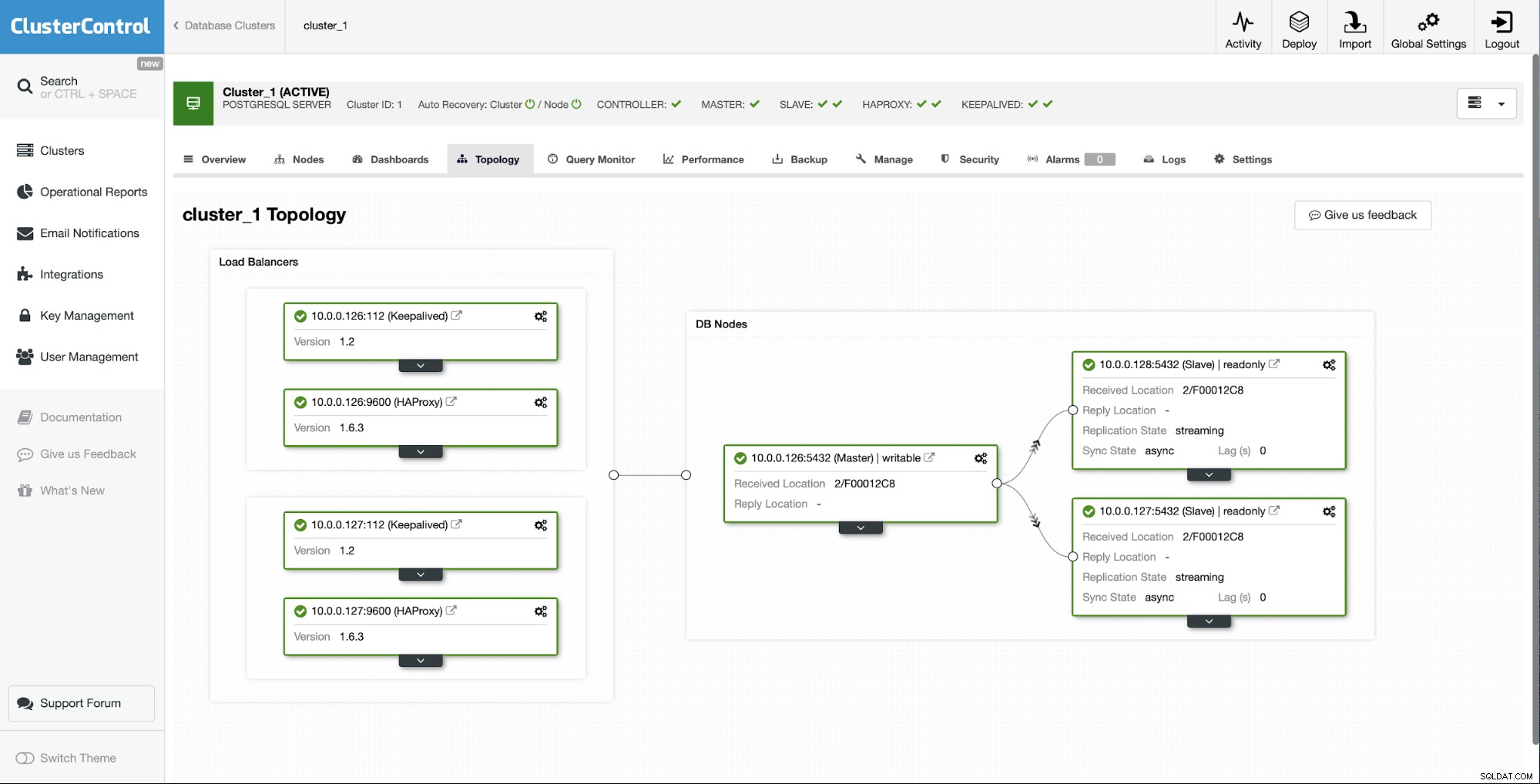
Jak můžete vidět, pomocí několika kliknutí se nám díky ClusterControl podařilo přestavět našeho neúspěšného otroka a vrátit ho zpět do clusteru.