Každé vydání PostgreSQL přichází s několika hlavními vylepšeními funkcí, ale stejně zajímavé je, že každé vydání také vylepšuje své minulé funkce.
Jelikož je brzy naplánováno vydání PostgreSQL 13, je čas zkontrolovat, jaké funkce a vylepšení nám komunita přináší. Jedním z takových zlepšení bez šumu je „Vylepšení logické replikace pro dělení.“
Pojďme pochopit toto vylepšení funkce na běžícím příkladu.
Terminologie
Dva pojmy, které jsou důležité pro pochopení této funkce, jsou:
- Tabulky oddílů
- Logická replikace
Tabulky oddílů
Způsob, jak rozdělit velký stůl na více fyzických částí, abyste dosáhli výhod, jako jsou:
- Vylepšený výkon dotazů
- Rychlejší aktualizace
- Rychlejší hromadné načítání a mazání
- Uspořádání zřídka používaných dat na pomalých discích
Některých z těchto výhod je dosaženo prořezáváním diskových oddílů (tj. plánovač dotazů používajících definici oddílu k rozhodnutí, zda oddíl skenovat či nikoli) a skutečností, že oddíl se spíše snáze vejde do omezené paměti ve srovnání s velkým stolem.
Tabulka je rozdělena na základě:
- Seznam
- Hash
- Rozsah

Logická replikace
Jak název napovídá, jedná se o metodu replikace, ve které jsou data replikována přírůstkově na základě jejich identity (např. klíče). Není to podobné metodám WAL nebo fyzické replikace, kde jsou data odesílána bajt po bajtu.
Na základě vzoru Vydavatel-Odběratel musí zdroj dat definovat vydavatele, zatímco cíl musí být registrován jako odběratel. Zajímavé případy použití jsou:
- Selektivní replikace (pouze některá část databáze)
- Simultánní zápisy do dvou instancí databáze, kde se replikují data
- Replikace mezi různými operačními systémy (např. Linux a Windows)
- Jemné zabezpečení replikace dat
- Spustí spuštění, jakmile data dorazí na stranu příjemce
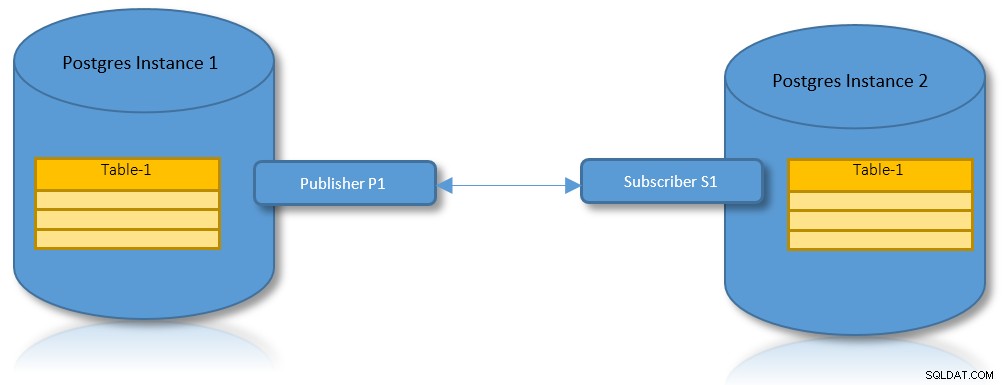
Logická replikace pro oddíly
S výhodami jak logické replikace, tak dělení na oddíly, je praktickým případem použití scénář, kdy je třeba replikovat rozdělenou tabulku přes dvě instance PostgreSQL.
Následují kroky k vytvoření a zdůraznění vylepšení, která jsou v tomto kontextu prováděna v PostgreSQL 13.
Nastavení
Zvažte nastavení dvou uzlů pro spuštění dvou různých instancí obsahujících rozdělenou tabulku:
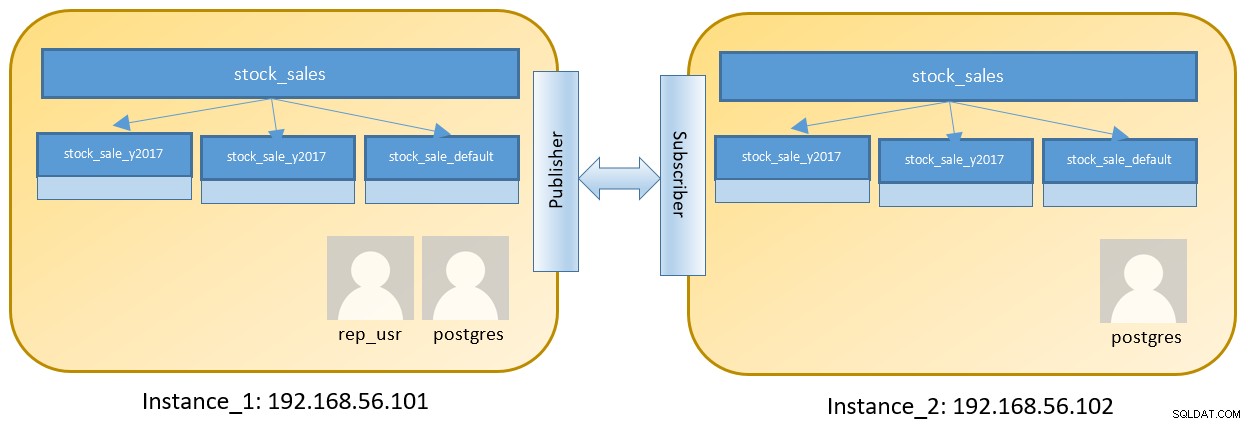
Kroky na Instance_1 jsou jako níže po přihlášení na 192.168.56.101 jako uživatel Postgres :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile startNastavení ‚wal_level‘ je specificky nastaveno na ‚logické‘, což znamená, že k replikaci dat z této instance bude použita logická replikace. Konfigurační soubor ‚pg_hba.conf‘ byl také upraven tak, aby umožňoval připojení z 192.168.56.102.
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;I když je postgresová role vytvořena ve výchozím nastavení v databázi Instance_1, měl by být vytvořen i samostatný uživatel, který má omezený přístup – což omezuje rozsah pouze pro danou tabulku.
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;Téměř podobné nastavení je vyžadováno na Instance_2
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startJe třeba poznamenat, že protože Instance_2 nebude zdrojem dat pro žádný jiný uzel, nastavení wal_level ani soubor pg_hba.conf nevyžadují žádná další nastavení. Netřeba dodávat, že pg_hba.conf může vyžadovat aktualizaci podle potřeb produkce.
Logical Replication nepodporuje DDL, musíme vytvořit strukturu tabulky také na Instance_2. Vytvořte rozdělenou tabulku pomocí výše uvedeného vytvoření oddílu a vytvořte stejnou strukturu tabulky také na Instance_2.
Nastavení logické replikace
Nastavení logické replikace je s PostgreSQL 13 mnohem jednodušší. Až do PostgreSQL 12 byla struktura podobná níže:
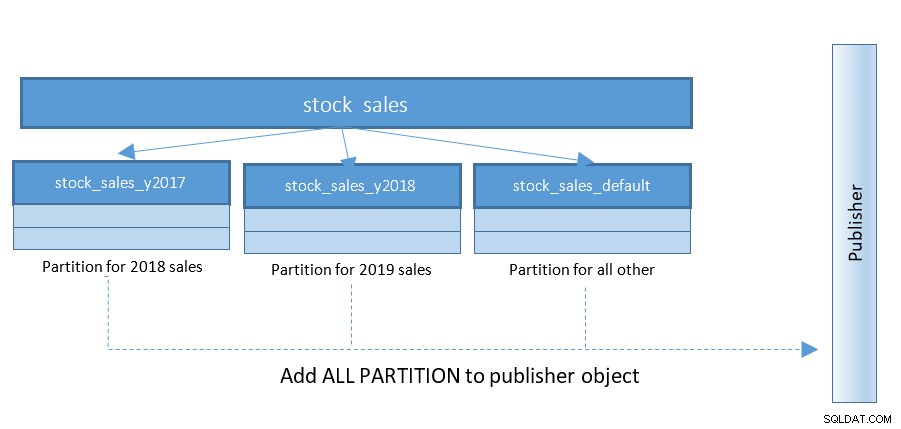
S PostgreSQL 13 je publikování oddílů mnohem jednodušší. Podívejte se na níže uvedený diagram a porovnejte jej s předchozím diagramem:
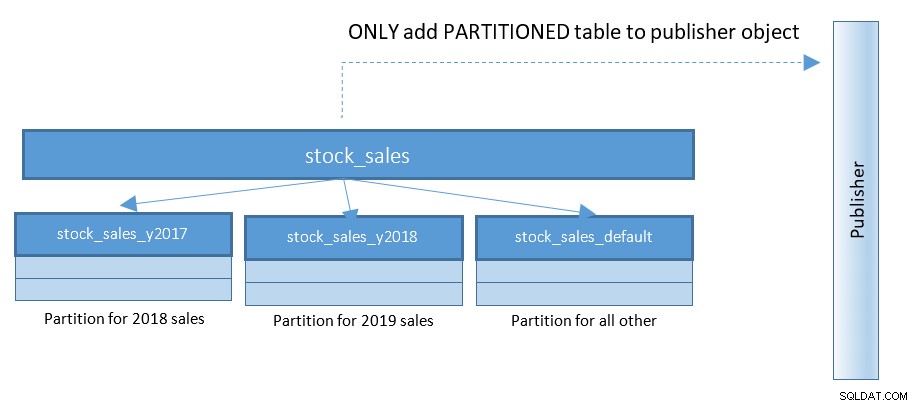
Se stovkami a tisíci dělených tabulek – tato malá změna zjednodušuje věci do značné míry.
V PostgreSQL 13 budou příkazy k vytvoření takové publikace:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);Konfigurační parametr publish_via_partition_root je nový v PostgreSQL 13, což umožňuje, aby přijímající uzel měl mírně odlišnou hierarchii listů. Pouhé vytvoření publikace na dělených tabulkách v PostgreSQL 12 vrátí chybová hlášení jako níže:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.Ignorujeme-li omezení PostgreSQL 12 a pokračujeme v používání této funkce na PostgreSQL 13, musíme vytvořit předplatitele na Instance_2 s následujícími prohlášeními:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;Kontrola, zda to opravdu funguje
S celým nastavením jsme téměř hotovi, ale pojďme provést několik testů, abychom zjistili, zda věci fungují.
V Instance_1 vložte více řádků a zajistěte, aby se vytvořily do více oddílů:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Zkontrolujte data na Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721Nyní zkontrolujeme, zda logická replikace funguje, i když koncové uzly nejsou na straně příjemce stejné.
Přidejte další oddíl na Instance_1 a vložte záznam:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Zkontrolujte data na Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174Další funkce dělení v PostgreSQL 13
V PostgreSQL 13 jsou také další vylepšení, která souvisejí s dělením, konkrétně:
- Vylepšení ve spojení mezi rozdělenými tabulkami
- Dělené tabulky nyní podporují spouštěče PŘED spouštěči na úrovni řádků
Závěr
Určitě zkontroluji výše uvedené dvě nadcházející funkce v mé další sadě blogů. Do té doby námětem k zamyšlení – díky kombinované síle dělení a logické replikace se PostgreSQL přibližuje k nastavení master-master?