Většina úloh OLTP zahrnuje náhodné použití I/O disku. Databázové systémy s vědomím, že disky (včetně SSD) jsou výkonově pomalejší než používání RAM, používají ke zvýšení výkonu ukládání do mezipaměti. Ukládání do mezipaměti je o ukládání dat do paměti (RAM) pro rychlejší přístup v pozdějším okamžiku.
PostgreSQL také využívá ukládání svých dat do mezipaměti v prostoru zvaném shared_buffers. V tomto blogu prozkoumáme tuto funkci, abychom vám pomohli zvýšit výkon.
Základy ukládání do mezipaměti PostgreSQL
Než se hlouběji ponoříme do konceptu ukládání do mezipaměti, pojďme si trochu oprášit základy.
V PostgreSQL jsou data organizována ve formě stránek o velikosti 8KB a každá taková stránka může obsahovat více n-tic (v závislosti na velikosti n-tic). Zjednodušená reprezentace by mohla vypadat následovně:
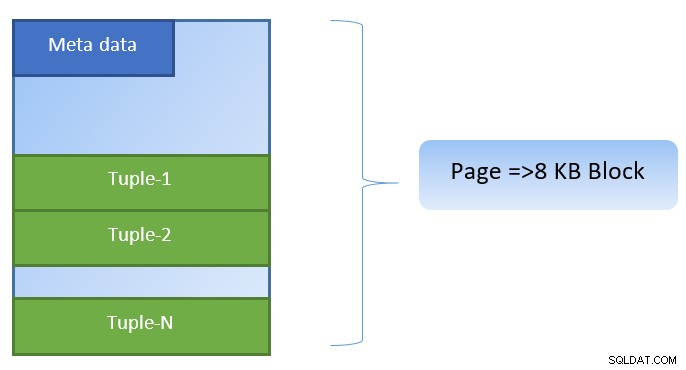
PostgreSQL ukládá do mezipaměti následující údaje pro urychlení přístupu k datům:
- Data v tabulkách
- Indexy
- Plány provádění dotazů
Zatímco se cachování plánu provádění dotazů zaměřuje na ukládání cyklů CPU; ukládání do mezipaměti pro data tabulky a data indexu je zaměřeno na úsporu nákladných diskových I/O operací.
PostgreSQL umožňuje uživatelům definovat, kolik paměti by chtěli vyhradit pro uchování takové mezipaměti pro data. Relevantní nastavení je shared_buffers v konfiguračním souboru postgresql.conf. Konečná hodnota shared_buffers definuje, kolik stránek lze v kterémkoli okamžiku uložit do mezipaměti.
Jakmile se provádí dotaz, PostgreSQL hledá stránku na disku, která obsahuje příslušnou n-tici, a vkládá ji do mezipaměti shared_buffers pro laterální přístup. Až bude příště potřeba přistupovat ke stejné n-tice (nebo jakékoli n-tice na stejné stránce), PostgreSQL může uložit IO disku tím, že jej přečte v paměti.
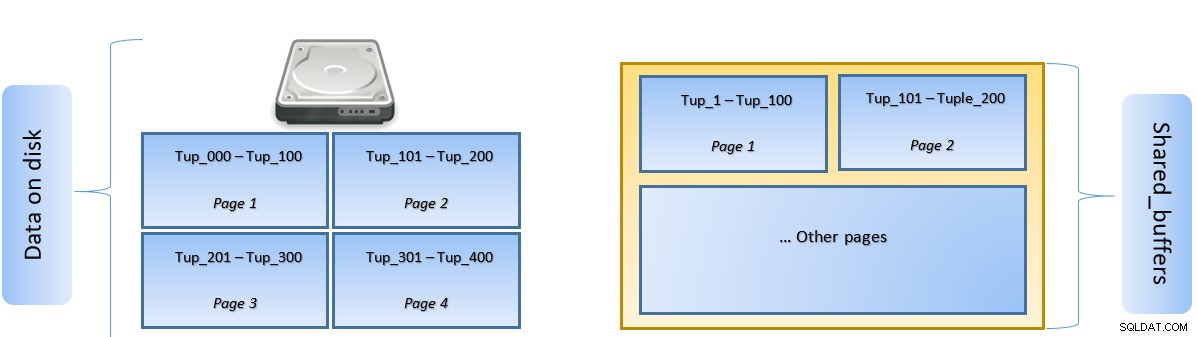
Na výše uvedeném obrázku jsou stránky 1 a 2 určitého tabulka byla uložena do mezipaměti. V případě, že uživatelský dotaz potřebuje získat přístup k n-ticím mezi Tuple-1 až Tuple-200, PostgreSQL je může načíst ze samotné RAM.
Pokud však dotaz potřebuje přístup k n-tice 250 až 350, bude muset provést diskový vstup/výstup pro stránku 3 a stránku 4. Jakýkoli další přístup pro n-tice 201 až 400 bude načten z mezipaměti a diskový vstup/výstup nebude potřeba – tím bude dotaz rychlejší.
Na vysoké úrovni se PostgreSQL řídí algoritmem LRU (nejméně nedávno používaný) identifikovat stránky, které je třeba z mezipaměti odstranit. Jinými slovy, stránka, na kterou se vstoupí pouze jednou, má vyšší šanci na vystěhování (ve srovnání se stránkou, která je navštívena vícekrát), v případě, že je potřeba novou stránku načíst PostgreSQL do mezipaměti.
Ukládání do mezipaměti PostgreSQL v akci
Uvedeme příklad a uvidíme vliv mezipaměti na výkon.
Spustit PostgreSQL s nastavením sdílené vyrovnávací paměti na výchozí 128 MB
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startPřipojte se k serveru a vytvořte fiktivní tabulku tblDummy a index na c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Naplňte fiktivní data 200 000 n-ticemi, takže existuje 10 000 jedinečných p_id a na každé p_id připadá 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Restartujte server a vymažte mezipaměť. Nyní proveďte dotaz a zkontrolujte, jak dlouho trvá jeho provedení
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msPotom zkontrolujte bloky načtené z disku
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0Ve výše uvedeném příkladu bylo z disku načteno 1 000 bloků, aby se našly početní n-tice, kde c_id =1. Načtení těchto záznamů z disku trvalo 160 ms, protože se disk I/O účastnil.
Provedení je rychlejší, pokud je stejný dotaz znovu spuštěn, protože všechny bloky jsou v této fázi stále v mezipaměti serveru PostgreSQL
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msa blokuje čtení z disku vs z mezipaměti
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Z výše uvedeného je patrné, že jelikož byly všechny bloky načteny z mezipaměti a nebyl vyžadován žádný diskový vstup/výstup. Díky tomu byly výsledky také rychlejší.
Nastavení velikosti mezipaměti PostgreSQL
Velikost mezipaměti je třeba vyladit v produkčním prostředí v souladu s množstvím dostupné paměti RAM a také s požadovanými dotazy ke spuštění.
Jako příklad – sdílený_buffer o velikosti 128 MB nemusí stačit k mezipaměti všech dat, pokud měl dotaz načíst více n-tic:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Změňte sdílený_buffer na 1024 MB, abyste zvýšili heap_blks_hit.
Ve skutečnosti, vezmeme-li v úvahu dotazy (na základě c_id), v případě reorganizace dat lze dosáhnout lepšího poměru zásahů do mezipaměti také s menší sdílenou vyrovnávací pamětí.
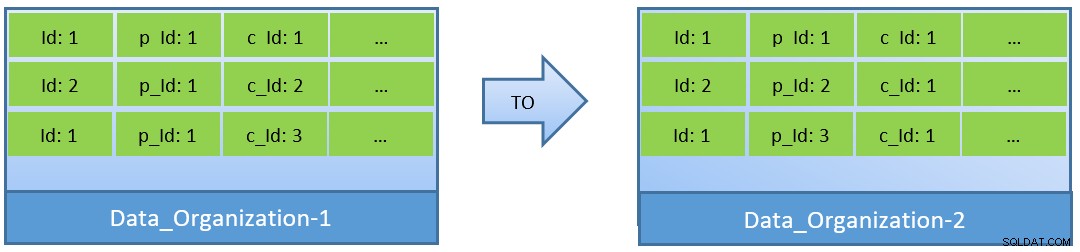
V Data_Organization-1 bude PostgreSQL potřebovat 1000 čtení bloků (a spotřebu mezipaměti ) pro nalezení c_id=1. Na druhou stranu pro Data_Organisation-2 bude pro stejný dotaz PostgreSQL potřebovat pouze 104 bloků.
Méně bloků požadovaných pro stejný dotaz nakonec spotřebuje méně mezipaměti a také optimalizuje dobu provádění dotazu.
Závěr
Zatímco shared_buffer je udržován na úrovni procesu PostgreSQL, cache na úrovni jádra je také brána v úvahu pro identifikaci optimalizovaných plánů provádění dotazů. Tomuto tématu se budu věnovat v pozdější sérii blogů.