Jedním z klíčových aspektů vysoké dostupnosti je schopnost rychle reagovat na poruchy. Není neobvyklé ručně spravovat databáze a mít monitorovací software, který dohlíží na stav databáze. V případě poruchy odešle monitorovací software upozornění na zavolanou obsluhu. To znamená, že se někdo možná bude muset probudit, dostat se k počítači a přihlásit se do systémů a podívat se na protokoly – to znamená, že před zahájením nápravy zbývá poměrně dost času. V ideálním případě by měl být celý proces automatizován.
V tomto blogu se podíváme na to, jak nasadit plně automatizovaný systém, který zjistí selhání primární databáze a zahájí procedury převzetí služeb při selhání podporou sekundární databáze. K automatickému převzetí služeb při selhání databáze Moodle PostgreSQL použijeme ClusterControl.
Výhoda automatického převzetí služeb při selhání
- Méně času na obnovu databázové služby
- Vyšší doba provozu systému
- Menší závislost na DBA nebo správci, kteří nastavili vysokou dostupnost databáze
Architektura
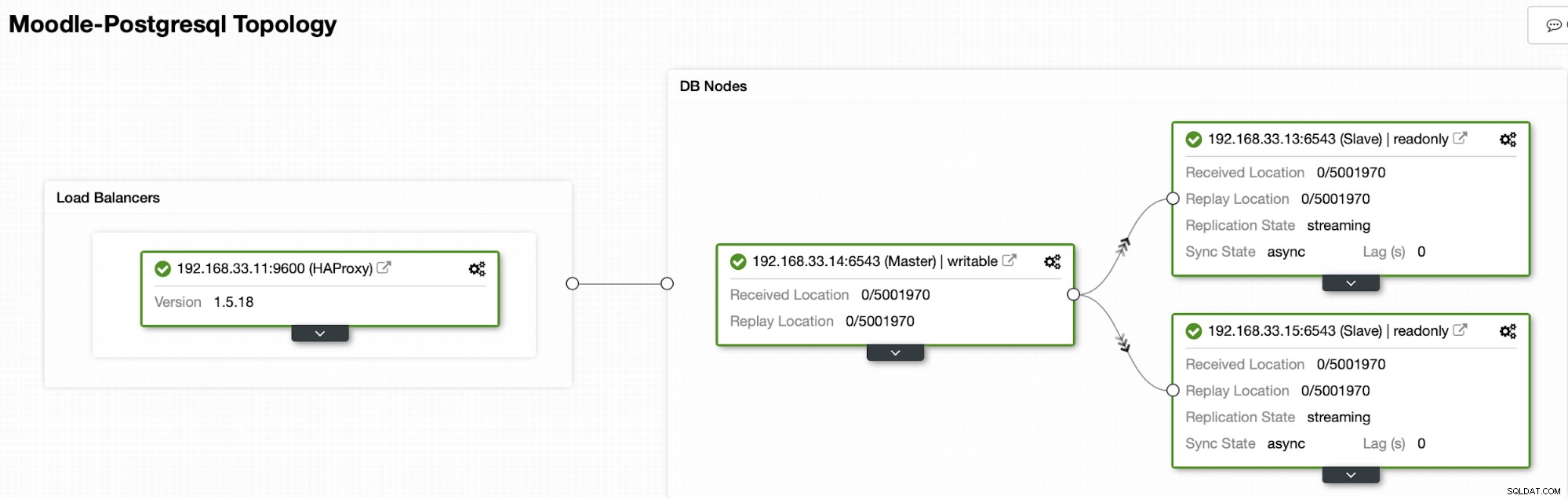
V současné době máme jeden primární server Postgres a dva sekundární servery pod HAProxy load balancerem který odesílá provoz Moodle do primárního uzlu PostgreSQL. Obnova clusteru a automatická obnova uzlů v ClusterControl jsou důležitá nastavení pro provedení procesu automatického převzetí služeb při selhání.

Řízení, na který server se má přepnout při selhání
ClusterControl nabízí whitelisting a blacklisting sady serverů, které se chcete zúčastnit převzetí služeb při selhání nebo vyloučit jako kandidáta.
V konfiguraci cmon můžete nastavit dvě proměnné,
- replication_failover_whitelist :obsahuje seznam IP adres nebo názvů hostitelů sekundárních serverů, které by měly být použity jako potenciální primární kandidáti. Pokud je tato proměnná nastavena, budou uvažováni pouze tito hostitelé.
- replication_failover_blacklist :obsahuje seznam hostitelů, kteří nebudou nikdy považováni za primárního kandidáta. Můžete jej použít k vypsání sekundárních serverů, které se používají pro zálohování nebo analytické dotazy. Pokud se hardware mezi sekundárními servery liší, můžete sem umístit servery, které používají pomalejší hardware.
Automatický proces převzetí služeb při selhání
Krok 1
Spustili jsme načítání dat na primární server (192.168.33.14) pomocí nástroje sysbench.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Krok 2
Chystáme se zastavit primární server Postgres (192.168.33.14). V ClusterControl je parametr (enable_cluster_autorecovery) povolen, takže bude podporovat další vhodné primární.
# service postgresql-12 stopKrok 3
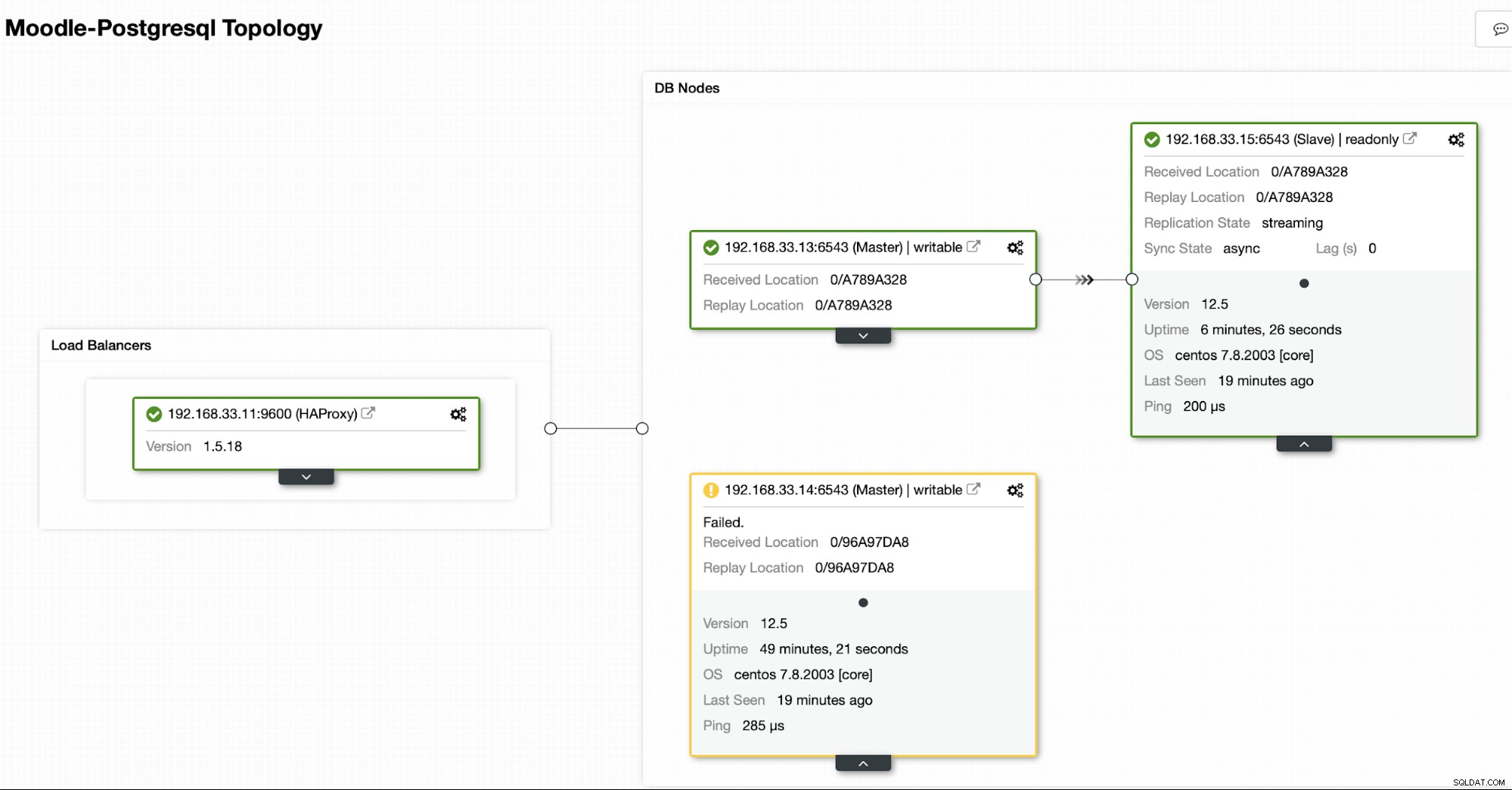
ClusterControl detekuje selhání v primární části a propaguje sekundární s nejaktuálnějšími daty jako novou primární. Funguje také na zbývajících sekundárních serverech, aby se replikovaly z nového primárního.

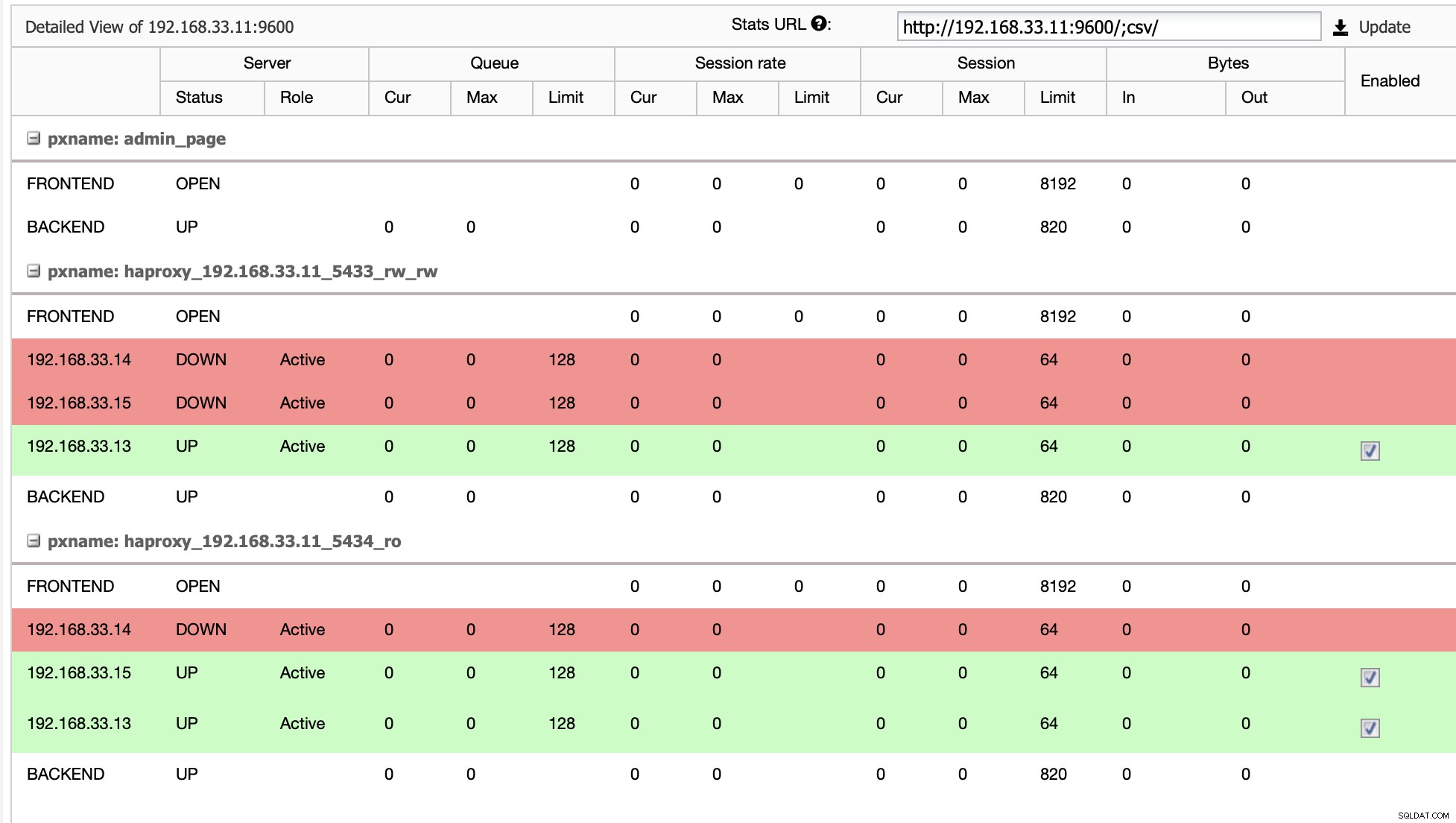
V našem případě je (192.168.33.13) nový primární server a sekundární servery se nyní replikují z tohoto nového primárního serveru. Nyní HAProxy směruje databázový provoz ze serverů Moodle na nejnovější primární server.
Od (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Od (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
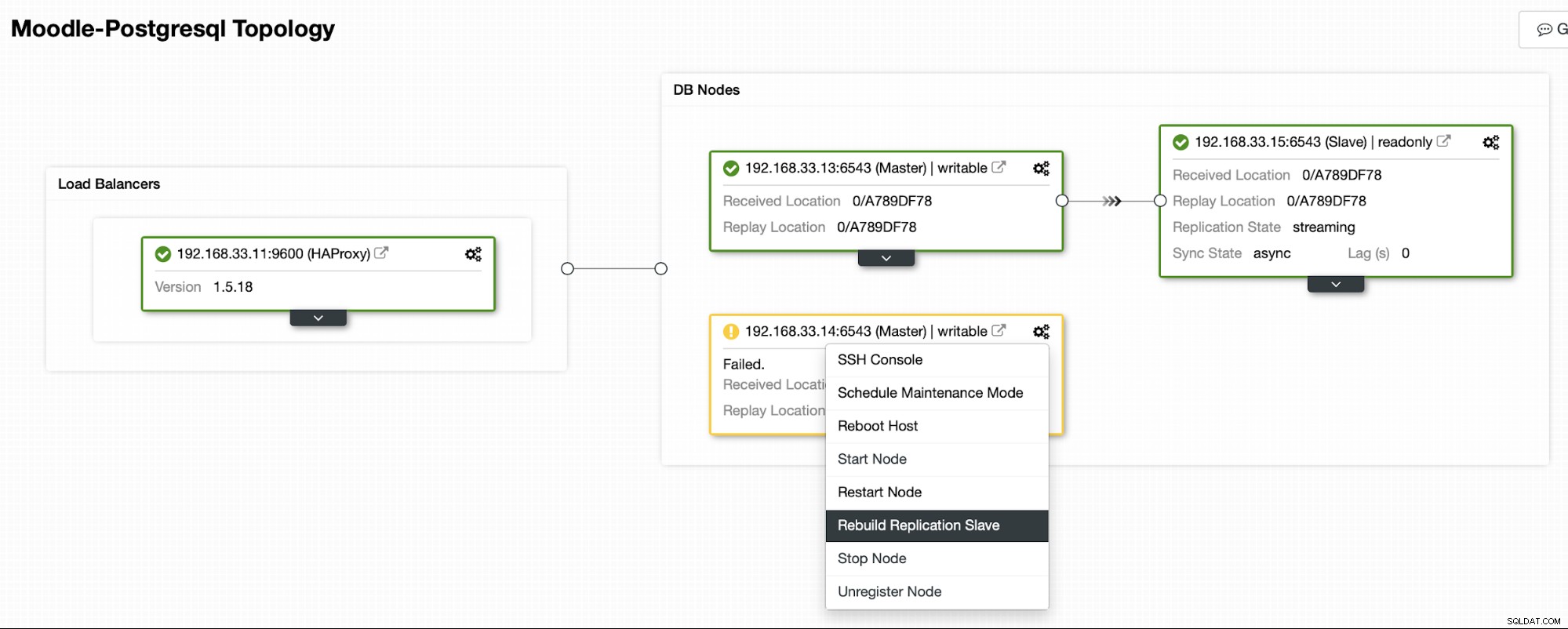
Aktuální topologie
Když HAProxy zjistí, že jeden z našich uzlů, ať už primární nebo replika, je není přístupný, automaticky jej označí jako offline. HAProxy do něj nebude odesílat žádný provoz z aplikace Moodle. Tato kontrola se provádí pomocí skriptů kontroly stavu, které jsou konfigurovány ClusterControl v době nasazení.
Jakmile ClusterControl povýší replikovaný server na primární, naše HAProxy označí starý primární uzel jako offline a uvede povýšený uzel online.
Jakmile bude starý primární server opět online, nebude se automaticky synchronizovat s novým primárním serverem. Musíme to vrátit zpět do topologie a lze to provést prostřednictvím rozhraní ClusterControl. Vyhneme se tak možnosti ztráty dat nebo nekonzistence v případě, že bychom chtěli nejprve prozkoumat, proč tento server selhal.
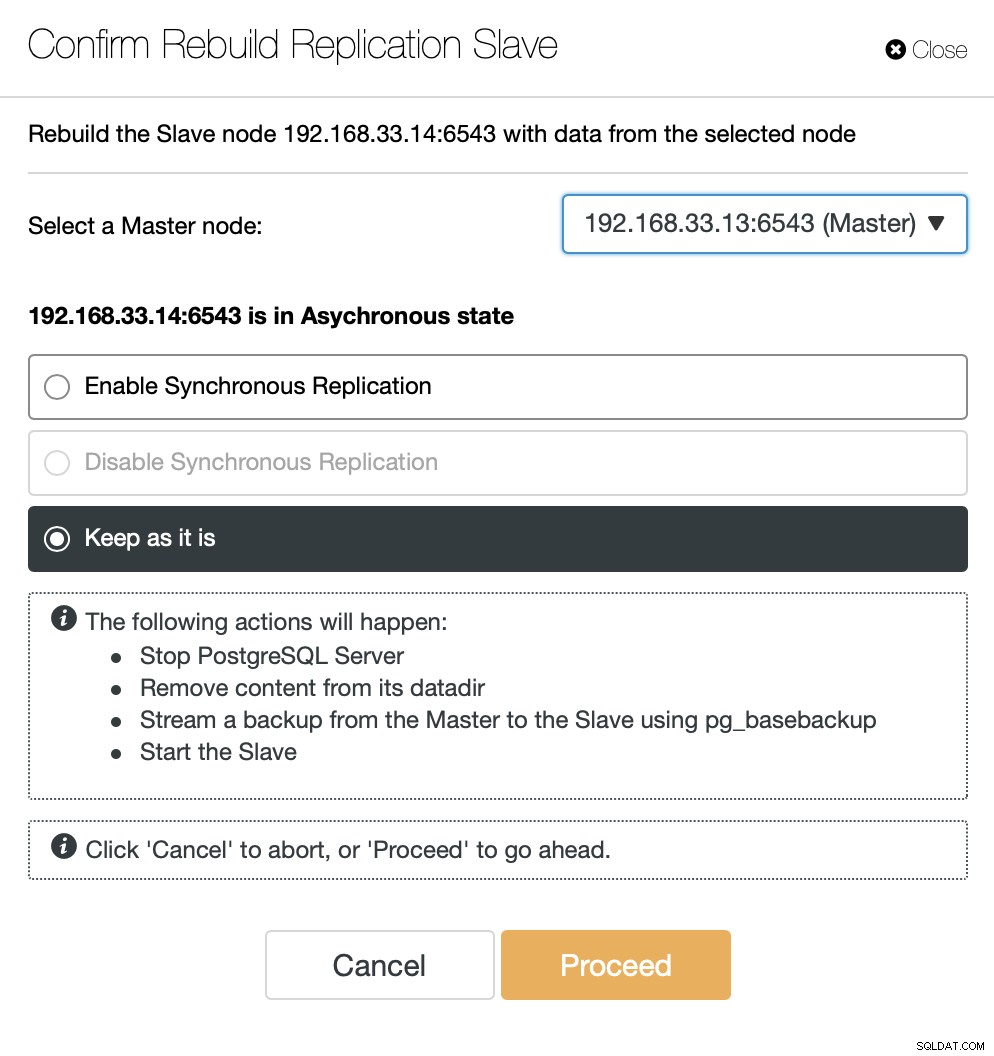
ClusterControl bude streamovat zálohu z nového primárního serveru a konfigurovat replikaci.
Závěr
Automatické převzetí služeb při selhání je důležitou součástí každé produkční databáze Moodle. Může snížit prostoje při výpadku serveru, ale také při provádění běžných úkolů údržby nebo migrace. Je důležité, aby to bylo správně, protože je důležité, aby software pro převzetí služeb při selhání přijal správná rozhodnutí.