V našich předchozích blozích o hybridním cloudu často zmiňujeme, že jednou z primárních možností využití nastavení topologie hybridního cloudu je použít ji jako cíl obnovy po havárii. Pro organizační strukturu je běžné, že plán obnovy po havárii (DRP) je vždy řešen před architektonickou implementací nastavení vaší databáze, ať už v cloudu nebo on-prem. Možná si myslíte, že vše nepředvídatelně selže a pokud to nebude správně řešeno a pochopeno, může to tragicky ovlivnit vaše podnikání. Překonání těchto výzev vyžaduje efektivní DRP (Disaster Recovery Plan), pro který je váš systém dobře nakonfigurován podle požadavků vaší aplikace, infrastruktury a podnikání. Klíčem k úspěchu v těchto typech situací je, jak rychle dokážeme problém vyřešit nebo se z něj zotavit.
Zatímco DRP řeší okolnosti katastrofy, Business Continuity zajistí, že DRP bude vždy v případě potřeby otestován a funkční. Vaše možnosti zotavení po havárii pro vaše databáze musí zajistit nepřetržitý provoz a omezení na hranici očekávání. Musí být v souladu s požadovaným RTO a RPO. Je bezpodmínečně nutné zajistit, aby produkční databáze byly pro aplikace dostupné i během katastrof; jinak by to mohlo být drahé. DBA, architekti, musí zajistit, aby databázová prostředí byla schopna vydržet katastrofy a aby byla v souladu se SLA pro obnovu po havárii. Nasazení databáze musí být správně nakonfigurováno, aby se zajistilo, že katastrofy neovlivní dostupnost databáze a kontinuitu podnikání.
Možnosti zotavení po havárii
Váš cluster PostgreSQL musí být nakonfigurován se systematickým přístupem, který se zavazuje dodržovat osvědčené postupy a je přijatelný podle průmyslových standardů. Spolu se systematickými přístupy vám následující procesy nebo mechanismy pomáhají zajistit, aby váš PostgreSQL nasazený do hybridního cloudu měl tyto přítomnosti:
-
Přepnutí při selhání/přepnutí
-
Automatické zálohování
-
Vysoce dostupné
-
Vyrovnávání zátěže
-
Vysoce distribuované prostředí
Přepnutí při selhání/přepnutí
Převzetí při selhání je automatický proces pro případ, že váš hlavní server selže; server v horkém pohotovostním režimu nebo v teplém pohotovostním režimu je povýšen do role primárního/hlavního serveru. Je to osvědčený postup, který umožňuje prostředí s vysokou dostupností mít alespoň sekundární uzel, který bude fungovat jako kandidát na uzel s podporou převzetí služeb při selhání. Jakmile primární server selže, záložní server by měl zahájit procedury převzetí služeb při selhání a poté sekundární nebo záložní server převezme roli hlavního serveru. Failover systém v běžné praxi využívá minimálně dva servery, které slouží jako primární a záložní. Jeho kontrole konektivity napomáhá mechanismus srdečního tepu, který nepřetržitě kontroluje a ověřuje, zda jsou oba v dobrém stavu a komunikace je naživu. V některých případech však může připojení způsobit falešný poplach. Proto v některých nastaveních a prostředích přítomnost třetího systému, jako je monitorovací uzel, leží v samostatné síti nebo datovém centru. Toto je spolehlivá možnost, jak zabránit nevhodnému nebo nechtěnému převzetí služeb při selhání. Spolehlivý ověřovací uzel může mít další funkce a kontroly, což zvyšuje složitost. Toto nastavení vyžaduje úplné a přísné testování, aby bylo zajištěno, že převzetí služeb při selhání je provedeno správně, když dojde ke změně v implementaci. To je také důležité, aby se zabránilo jakémukoli zhoršení vašeho PostgreSQL
Řekněme, že máte sekundární nebo pohotovostní cluster v jiném datovém centru s jiným nastavením hardwaru; možná nebudete chtít náhlé převzetí služeb při selhání, zvláště pokud to není ideální případ kvůli pouhému falešně pozitivnímu výsledku. V tomto scénáři však cílový uzel nebo cluster pro obnovu dat musí mít stejné prostředky a specifikace jako váš primární uzel nebo cluster. Pokud je váš cíl obnovy dat ve veřejném cloudu a primární je on-prem, ujistěte se, že to již bylo zahrnuto ve vašem plánování kapacity a že zdroje mají téměř stejné specifikace, abyste se vyhnuli nechtěným výsledkům.
Při používání a přípravě na váš mechanismus převzetí služeb při selhání ve vašem clusteru PostgreSQL v rámci hybridního cloudu se musíte ujistit, že váš nástroj se perfektně hodí k provádění úkolu, kterého se má dosáhnout. Existují nástroje třetích stran, které nejsou součástí PostgreSQL s ohledem na pokročilé převzetí služeb při selhání. Jde například o ClusterControl, pg_auto_failover od CitusData (c/o Microsoft), Pgpool-II, Bucardo a další. Tyto pokročilé nástroje poskytují oplocení uzlů nebo známé jako STONITH (vystřelte druhý uzel do hlavy). Tím je zajištěno, že váš selhaný primární nebo hlavní uzel se bude vyhýbat přijímání zápisů nebo návratu online do předchozího stavu, aby obsluhoval běžné transakce. Tento problém je běžně známý jako scénář rozděleného mozku. Ztrácí synchronizaci dat kvůli selhání (úroveň hardwaru nebo zdrojů), ale vaše primární servery, které jsou údajně pouze jedním primárním serverem, se stále chovají jako normální příjemci požadavků na zápis dat, což způsobuje poškození dat v celém clusteru.
Automatické zálohování
Zálohy vždy poskytují vysokou jistotu a ochranu proti ztrátě dat. Zálohování maximalizuje vaše RPO, protože pomáhá minimalizovat ztrátu dat při katastrofě. Věci, které musíte vzít v úvahu a připravit se na automatické zálohování, se týkají vašeho zálohovacího zařízení/hardwaru, redundance zálohovaných dat, zabezpečení, výkonu, rychlosti a úložiště dat.
Záložní zařízení
Zde musíte mít tu nejlepší volbu pro vaše zálohovací zařízení. Rychlost, významný objem úložiště a vysoká dostupnost mohou být vaší požadovanou volbou. Někteří se spoléhají na úložiště SAN nebo NAS nebo svá data rozdělují na jiné poskytovatele zálohovacích úložišť třetích stran. Je nezbytné, aby vaše zálohovací zařízení nabízelo rychlost pro zápis a čtení dat, zejména pokud pro svá data v klidu použijete kompresi a šifrování. Dekomprese a dešifrování vyžadují prostředky, takže musíte zvážit, kdy musíte použít obnovu dat. Během tohoto stavu musíte určit, že musíte dosáhnout svého maximálního RPO a svěřit dosažitelné SLA (Service-Level Agreement) svým zákazníkům. Je také ideální, když budete muset zálohu izolovat od místní sítě nebo ji uložit na vzdálené místo. Alternativním přístupem je spolupráce s poskytovateli třetích stran. Možností může být například uložení zálohy do cloudu a jejich zařízení je vysoce sofistikované a uspokojí vaše požadavky.
Redundance zálohovaných dat
Rozložení dat na více místech je ideálním řešením. To posílí vaše šance na obnovu dat, například lidská chyba nebo chyba softwarové logiky způsobí, že odstraníte staré kopie zálohy, ale omylem odstraníte celé klíčové záložní kopie. V některých sofistikovaných prostředích, jako je ukládání v cloudovém prostředí, jako je Amazon S3, Cloud Storage od Googlu nebo Azure Blob Storage, nabízí replikaci vašeho uloženého souboru. To poskytuje větší redundanci a lze jej flexibilně nastavit, aby vyhovoval vašim požadavkům.
Vysoce dostupné
Vysoce dostupný cluster PostgreSQL v hybridním cloudu vždy zajistí, že vaše databázová komunikace zajistí provozuschopnost. Ideální případ vysoké dostupnosti závisí na měření vaší dostupnosti. V tomto případě může být běžným nastavením pro PostgreSQL nasazený v hybridním cloudu buď vaše databáze hostovaná ve veřejném cloudu, může to být váš sekundární cluster fungující jako váš cluster pro obnovu dat v případě, že primární cluster selže nebo utrpí síťovou katastrofu a může trvat mnoho prostojů. V některých nastaveních je možné, že sekundární cluster ležící ve veřejném cloudu nemusí být přesně tak sofistikovaný jako primární, řekněme, že se jedná o váš místní nebo soukromý cloud. Vaše aplikace si může pohrát, aby omezila návštěvníky nebo provoz, kteří se mohou připojit k vaší databázi. Tento typ scénáře může snížit vaše náklady na nastavení, ale to samozřejmě závisí pouze na vašich požadavcích. Pokud je váš typ aplikace masivní a musí nepřetržitě přijímat běžné až vytížené dopravní situace, ujistěte se, že vaše sekundární klastrové prostředky musí být stejně výkonné jako primární, aby byla zajištěna vysoká dostupnost, tj. 99,9999999 %.
Abyste dosáhli vysoce dostupného clusteru PostgreSQL v prostředí hybridního cloudu, musíte mít mechanismus převzetí služeb při selhání. V případě selhání a výpadku primárního klastru nebo primárního serveru může sekundární nebo pohotovostní server převzít roli hlavního serveru bez ohledu na jeho umístění. Nejdůležitější je funkčnost a výkon, zejména z hlediska aplikace nebo klienta, není ovlivněn vůbec nebo alespoň velmi minimálně.
Vyrovnávání zátěže
Mechanismus vyvažování zátěže pro váš cluster PostgreSQL napomáhá nastavení hybridního cloudu, který je lépe ovladatelný a méně riskantní, zvláště když dochází k velkému zatížení provozem. V mnoha situacích server přijímá velké zatížení, které způsobuje paniku serveru. To vede k nepoužitelnosti serveru kvůli zaneprázdněným zdrojům spotřebovaným mnoha vlákny běžícími na pozadí. Tuto situaci lze zlepšit opravou chybných dotazů a návrhové architektury vaší databáze. To by mělo zahrnovat to, jak distribuujete čtení proti zátěži zápisu a hloubkové pochopení požadavků vaší aplikace, jako je nastavení master-master nebo pouze jeden master, ale vertikální škálování, abyste získali vyšší výpočetní a paměťové zdroje. K dispozici je také velký výběr nástrojů třetích stran, jako je pgbouncer a Pgpool II, které vám pomohou při nasazení PostgreSQL v hybridním cloudovém prostředí.
Vysoce distribuované prostředí
Škálovatelnost, vysoká distribuce na více místech nebo u různých poskytovatelů cloudu (on-prem nebo privátní a veřejný cloud) poskytuje větší flexibilitu a snášenlivost v prostředí hybridního cloudu, což je skvělé pro zotavení po havárii. Je flexibilní, když potřebuje převzetí služeb při selhání na konkrétním cloudovém umístění příznivém pro přírodní katastrofu nebo katastrofu, zejména pokud je vámi určená oblast, kde sídlí váš primární cluster, aktuálně zdevastována nebo ovlivněna přírodní příčinou. To je nevyhnutelná příčina, kterou musíte pochopit a být spolehliví na současnou situaci. Vaše aplikace a klienti musí být obsluhováni nepřetržitě nepřetržitě. Slouží k tomu, aby byla veřejně dostupná v cloudu a zároveň sloužila v soukromém nebo místním prostředí. Toto nastavení zvyšuje složitost a vyžaduje pokročilé znalosti na straně databáze a zabezpečení a sítí. Optimalizace a ladění jsou klíčové pro úspěch, protože je velmi důležité, aby při poskytování zpřísněného zabezpečení pro zapouzdření vašich dat při cestování na internetu bylo prokázáno, že se výkon stabilizuje a není ovlivněn implementovaným nastavením.
Kvůli složitosti nastavení je nástroj ideální pro správu nasazení a usnadnění celkového stavu vašich databází, dohlíží na jeden aspekt vašeho clusteru, ale na celé úrovni z místního privátního cloudu, a na aspekt veřejného cloudu. Všechna nastavení musí být udržována na zvládnutelné a přímočaré úrovni, aby v případě poplachů a výstrah bylo snadné problém správně a včas opravit a vyřešit.
ClusterControl pro zotavení po havárii v prostředí hybridního cloudu
ClusterControl umožňuje organizaci nebo společnostem flexibilně spravovat databázi a snížit celkovou složitost nastavení. ClusterControl nabízí převzetí služeb při selhání, automatizované zálohování, poskytuje vysoce dostupné nastavení, vyrovnávání zátěže a podporuje nasazení v distribuovaném prostředí, což usnadňuje přidávání uzlů buď ve veřejném cloudu, soukromě nebo on-prem.
Automatické obnovení ClusterControl
Automatická obnova ClusterControl představuje tuny mechanismu převzetí služeb při selhání a charakteristik obnovy, zejména když uzel selže nebo se cluster dostane do degradovaného stavu. To lze snadno provést, jak je znázorněno na níže uvedeném snímku obrazovky:
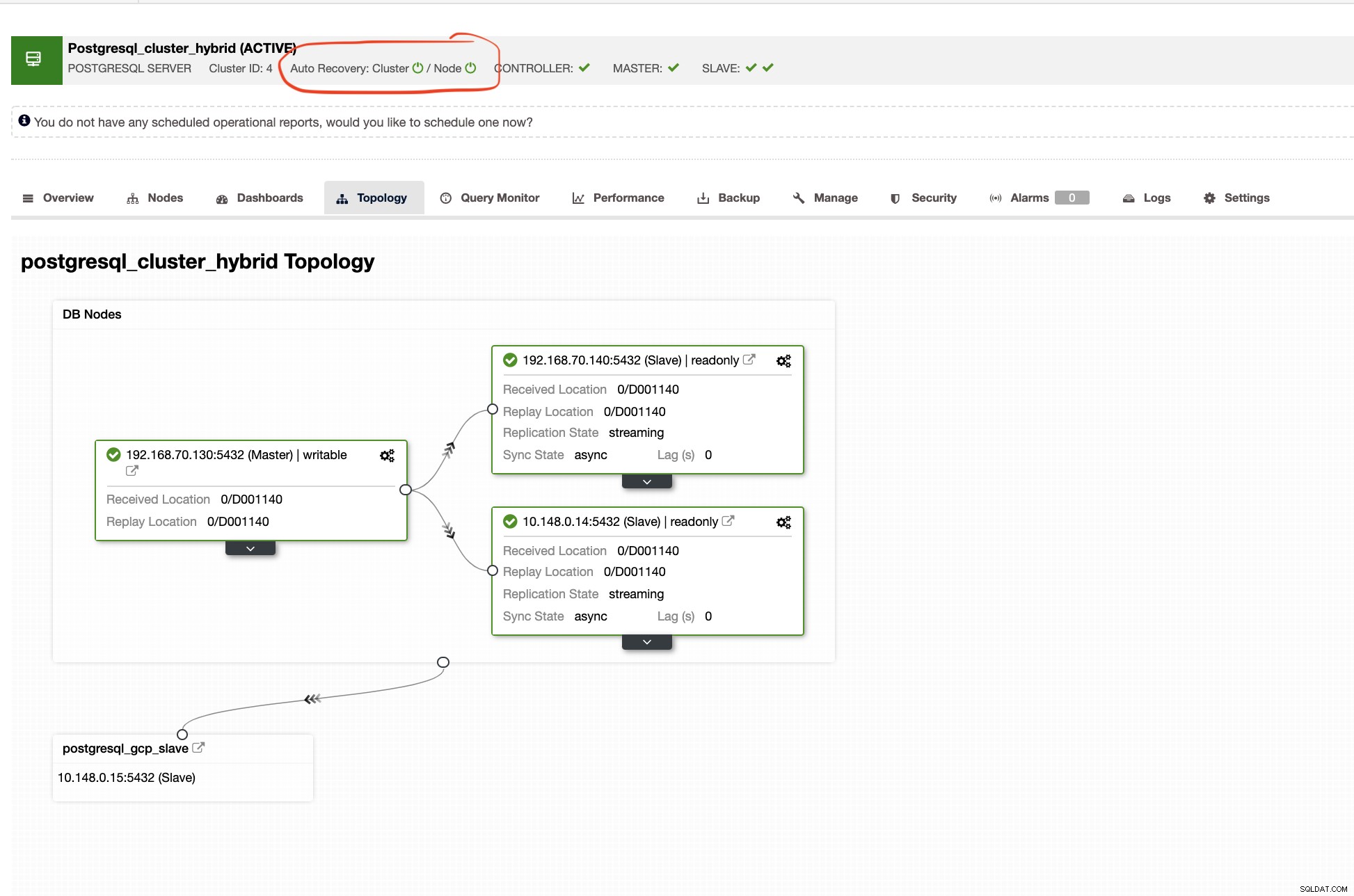
Zálohování a obnovení
ClusterControl má také funkci Backup and Restore, která vám umožňuje spravovat zálohování, vytvářet zálohy, plánovat zálohování a obnovovat zálohy. Správa zálohy je velmi přímočará a vytváření nebo plánování zálohování je jednoduché, ale nabízí také pokročilé možnosti. Nabízí také možnosti cloudového zálohování, které vám umožní mít zálohovaná data, čímž posílí možnosti obnovy po havárii. Viz níže:
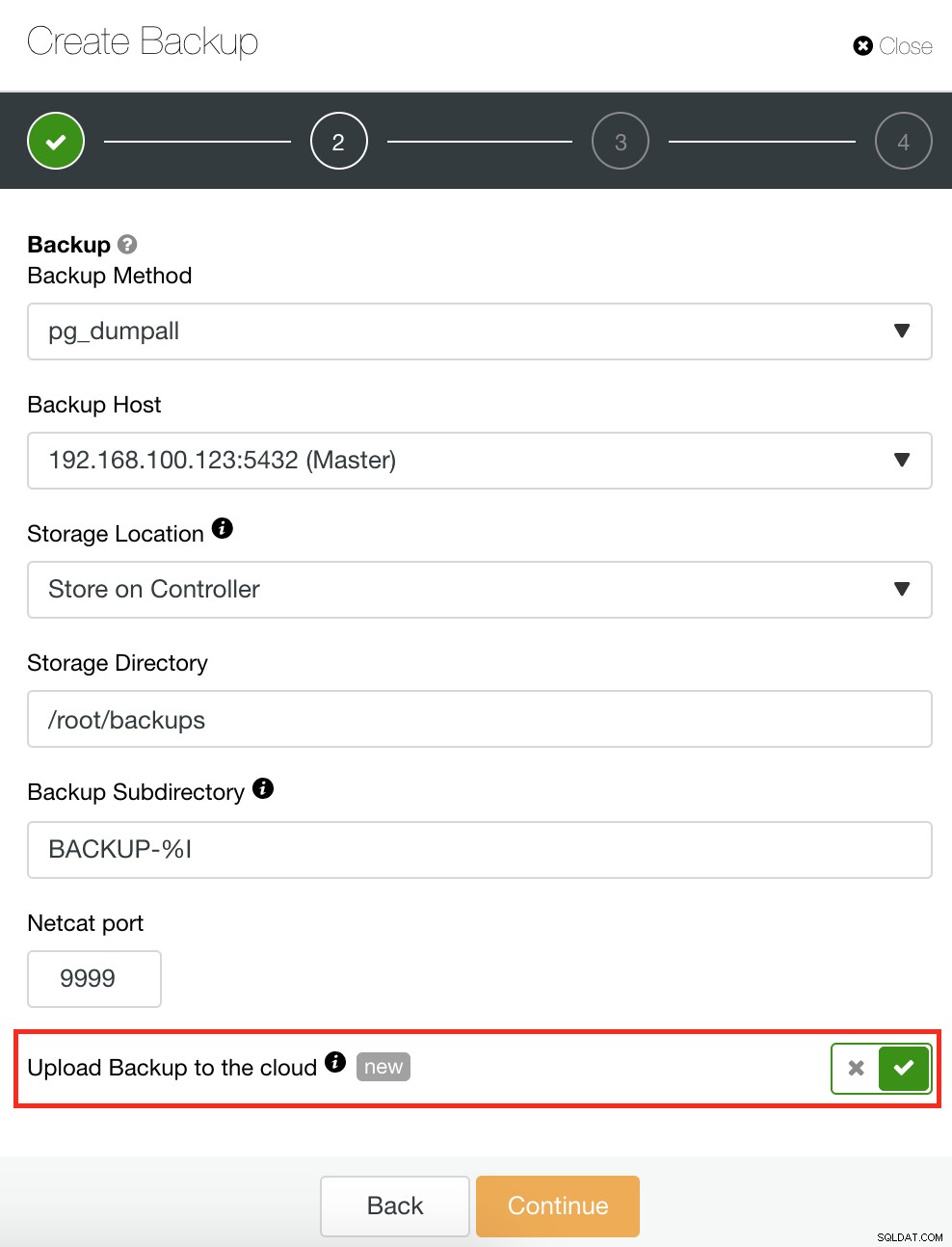
Jak je znázorněno níže, správa zálohy poskytuje jednoduché uživatelské rozhraní, pomocí kterého si můžete vybrat, kterou zálohu chcete obnovit, jinak ji možná budete muset zrušit. Záloha ClusterControl vám umožňuje zvolit dobu uchování, takže v případě, že máte dlouhý seznam, některé z nich lze po dosažení doby uchování odstranit. 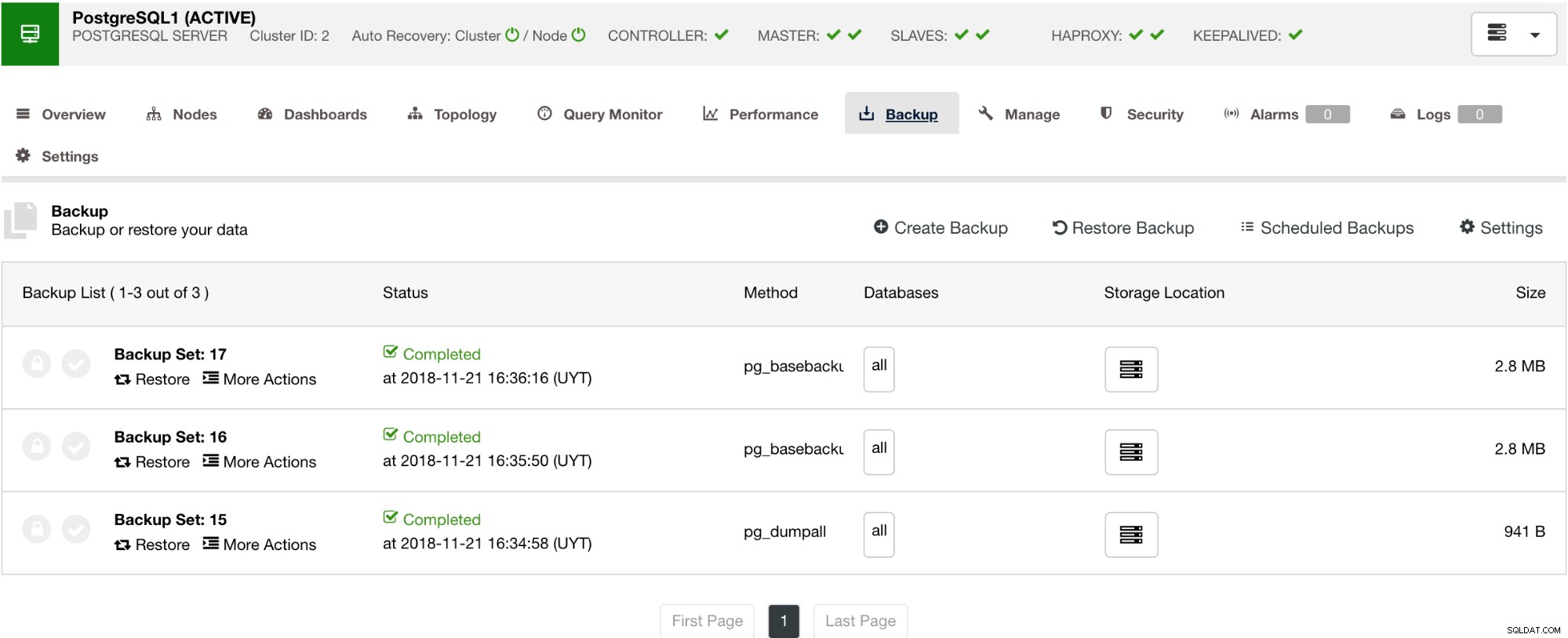
Podporuje mechanismy vysoké dostupnosti (HA) a vyvažování zátěže (LB)
Nemusíte ručně nastavovat nebo dokonce zkoumat některé způsoby, jak přidat vysokou dostupnost do vašeho clusteru PostgreSQL. S ClusterControl existuje snadný a pohodlný způsob, jak dokončit práci. Pokud vidíte ukázkový snímek obrazovky, má nastavení HAProxy a Keepalived. Viz snímek obrazovky níže:
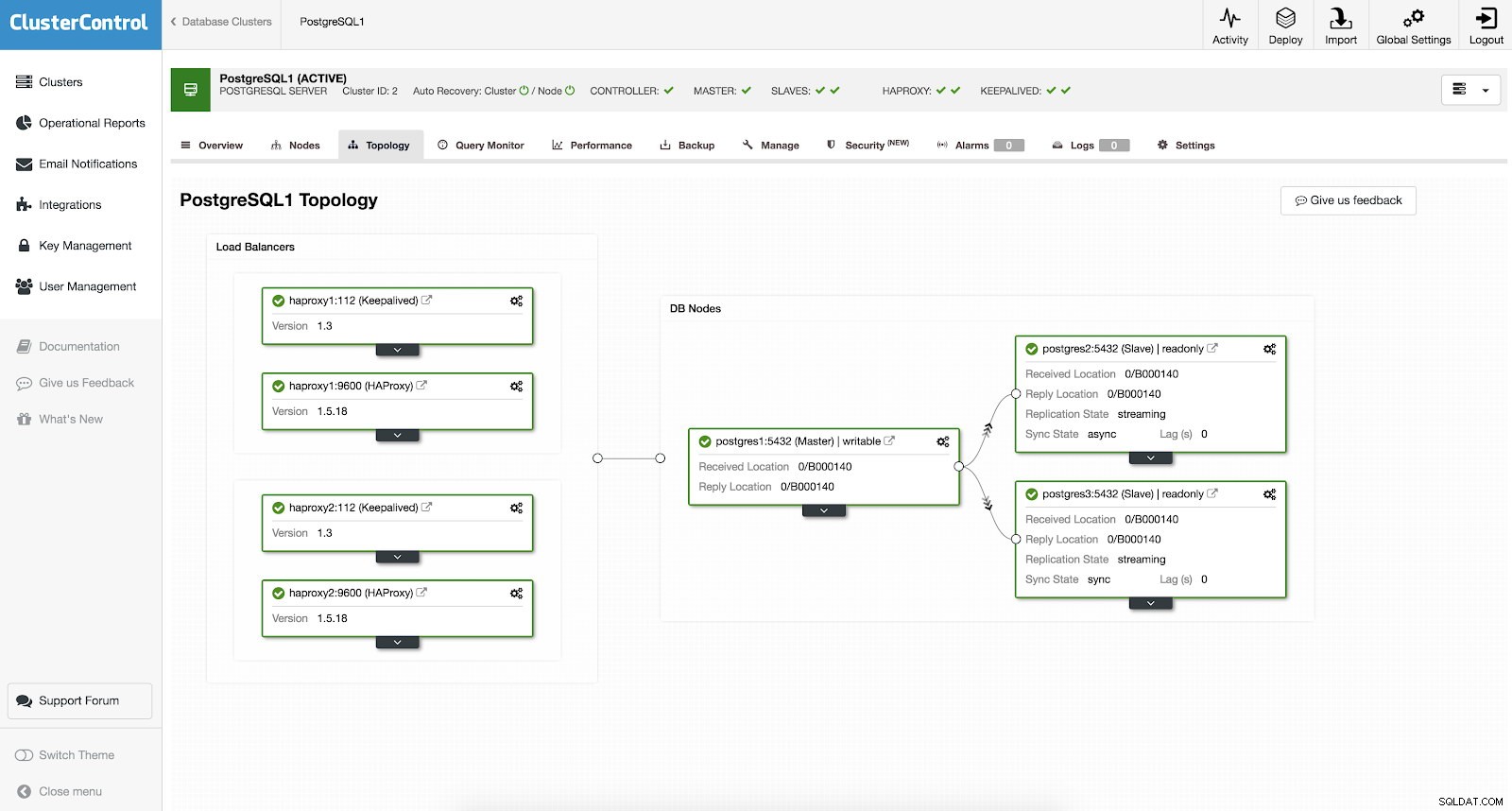
Nastavení vysoké dostupnosti pomocí ClusterControl lze provést pomocí
Podporuje distribuované prostředí
Pokud chcete mít distribuce rovnoměrně z on-prem nebo privátního cloudu do veřejného cloudu, ClusterControl také podporuje cloudové nasazení. Ale pro cluster PostgreSQL a plánujete mít sekundárního slave umístěného v jiném cloudu, můžete vytvořit slave cluster, jak je uvedeno níže,
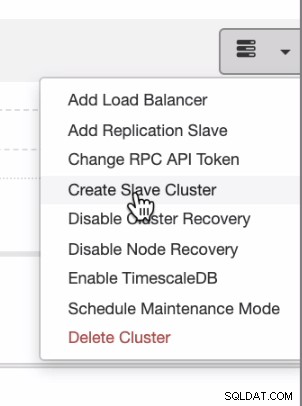
a můžete dorazit s konečným výsledkem, jak je uvedeno níže,

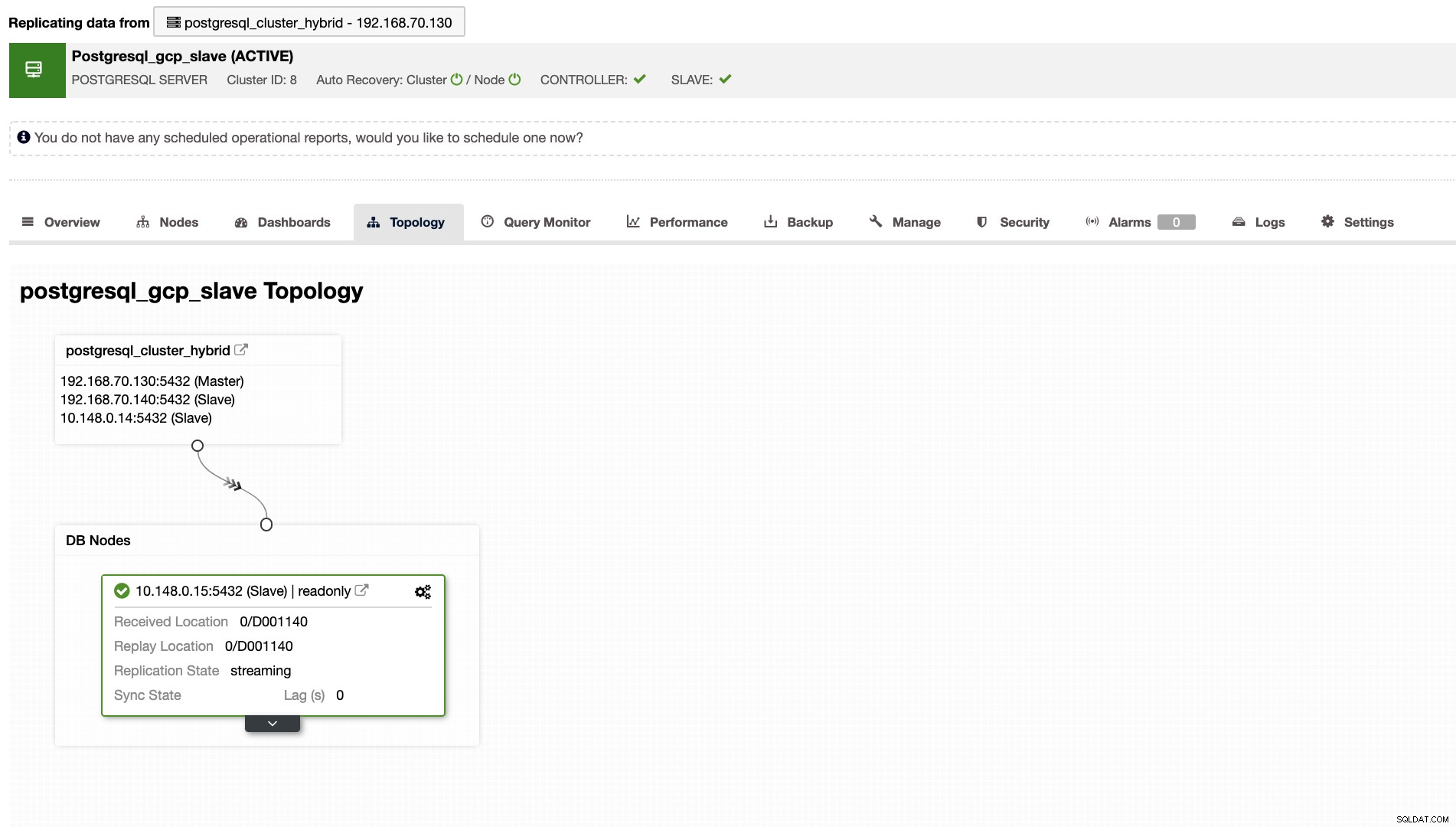
ClusterControl vám také ukáže správnou topologii vašeho clusteru, kdykoli budete mít nastaveno prostředí hybridního cloudu. Viz následující níže,
Zatímco v podřízeném clusteru topologie ukáže svůj strom původu a odhalí svého hlavního. Slave zde ukazuje, že je umístěn v samostatné síti primárně umístěné v Google Cloud, zatímco hlavní je on-prem.
Závěr
Je přijatelné připustit, že nastavení hybridního cloudu, zejména s clusterem PostgreSQL, zvyšuje složitost. Musíte mít správný nástroj s dostupnými možnostmi na podporu plánování obnovy po havárii. Ty jsou velmi důležité pro záchranu a prevence vašeho podnikání před potenciální katastrofou finančních škod a ztrátou důvěry zákazníků. Investujte do správných nástrojů a dovedností vaší technologie a ochráníte své podnikání před negativními dopady.