PostgreSQL, čtvrtá nejoblíbenější databáze a DBMS roku 2017, explodovala v popularitě mezi vývojovými a databázovými komunitami po celém světě. Hosting PostgreSQL, který ukradl tržní podíl předním společnostem Oracle, MySQL a Microsoft SQL Server, je také vysoce využíván novými podniky ve vzrušujících oblastech, jako je IoT, e-commerce, SaaS, analytika a další.
Co je tedy trendy ve správě PostgreSQL?
Minulý měsíc jsme se zúčastnili PostgresOpen v San Franciscu, abychom odhalili nejnovější trendy od samotných odborníků.
Časově nejnáročnější úlohy správy PostgreSQL
Co vám tedy žere čas na frontě správy PostgreSQL? Zatímco se správou vašich produkčních nasazení PostgreSQL jsou spojeny tisíce úkolů, správa dotazů byla silným lídrem s více než 30 % respondentů.
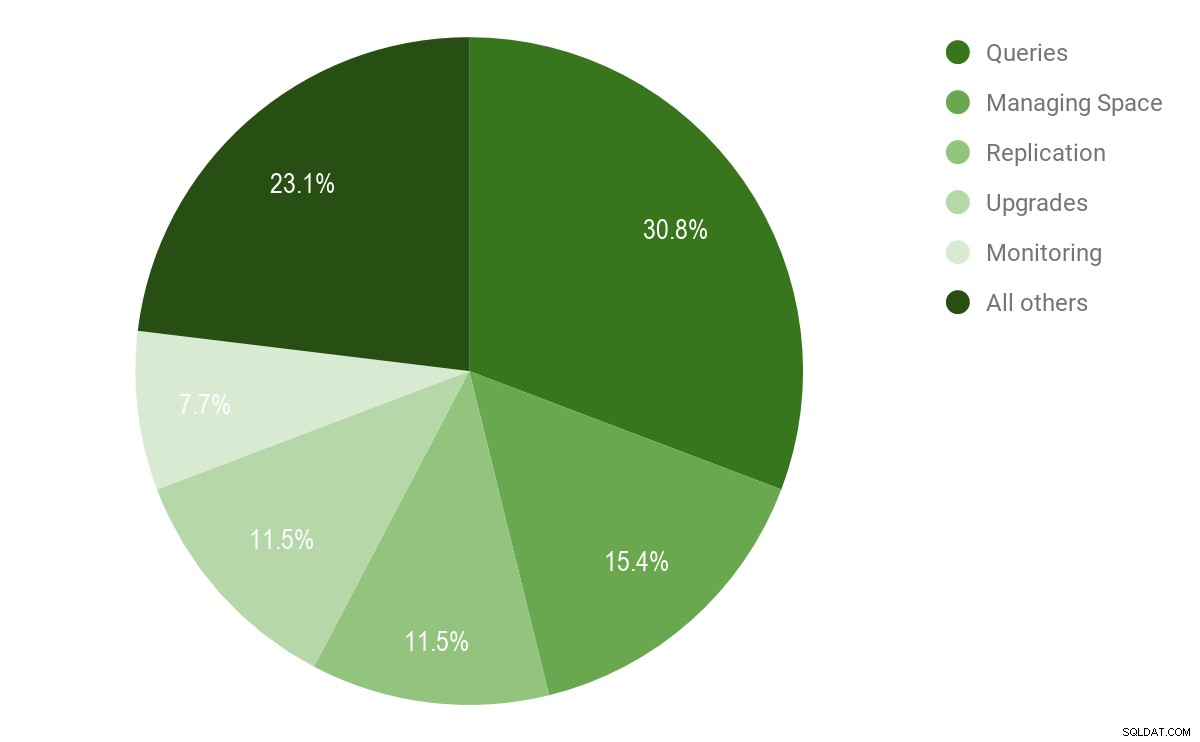
Správa prostoru byla vzdálenou sekundou a 15 % uživatelů PostgreSQL to považovalo za svůj nejobtížnější úkol, následovala replikace, upgrady a monitorování. 23 % uživatelů PostgreSQL spadalo do kategorie „Všechny ostatní“, skládající se z úkolů jako záplatování, obnovy, dělení a migrace.
Správa rozdělení dotazů PostgreSQL
S velkým náskokem ve správě PostgreSQL dotazů jsme se ponořili hlouběji, abychom zjistili, jaké konkrétní úkoly spotřebovávají jejich čas. Výsledky se rozšířily do celého procesu správy dotazů, od strukturování při nastavení až po optimalizaci po analýze.

Abychom to dále vysvětlili, začněme na začátku procesu správy dotazů:
Struktura dotazu
Nejmenší segment, spravující struktury dotazů, představoval 22 % odpovědí uživatelů PostgreSQL, kteří si vybrali dotazy jako svůj časově nejnáročnější úkol správy.
Než začnete, musíte vytvořit plán dotazů PostgreSQL kolem vašich clusterů, aby odpovídala struktuře dotazu vašim vlastnostem dat. Ty se skládají z uzlů, od uzlů skenování na spodní úrovni pro nezpracované návraty tabulky řádků spolu s řádky mimo tabulky, jako jsou hodnoty.
Pomalá analýza dotazů
Po vytvoření struktury je dalším krokem analýza vašich dotazů za účelem identifikace pomalu běžících dotazů, které mohou mít vliv na výkon vaší aplikace. Ve výchozím nastavení jsou „pomalé dotazy“ definovány jako dotazy, které trvají déle než 100 ms.
Optimalizace dotazů
Teď, když jste identifikovali své pomalé dotazy, začíná skutečná práce – optimalizace vašich PostgreSQL dotazů. Ladění výkonu Postgresu může být příšerný úkol, ale se správnou identifikací a analýzou se můžete zaměřit na úzká hrdla a provést potřebné změny dotazů a přidat indexy tam, kde je to potřeba, abyste zlepšili své provádění. Zde je skvělý článek o dotazech na ladění výkonu v PostgreSQL.
Nejnovější trendy PostgreSQL:Nejvíce časově náročné úkoly a důležité metriky pro sledování tweetování kliknutím
Nejdůležitější metriky ke sledování výkonu PostgreSQL
Nyní, když jsme identifikovali časově nejnáročnější úlohu správy PostgreSQL, pojďme se hlouběji podívat na důležité metriky, které uživatelé PostgreSQL sledují, aby optimalizovali svůj výkon.
Nejdůležitější výsledky metrik PostgreSQL byly výrazně rovnoměrnější než úkoly správy, což vedlo ke čtyřsměrnému spojení mezi statistikami replikace, využitím CPU a RAM, transakcemi za sekundu (TPS) a pomalé dotazy:

Statistiky replikace
Monitorování stavu replikace PostgreSQL je zásadním úkolem pro zajištění správného provádění replikací a zachování vysoké dostupnosti vašich produkčních nasazení. Proces replikace by měl být přizpůsoben tak, aby co nejlépe vyhovoval potřebám vaší aplikace, a nepřetržité monitorování koncových bodů je nejlepším způsobem, jak zajistit, aby vaše data byla zabezpečena a připravena k obnově.
Je důležité sledovat metriky na serverech v pohotovostním režimu i na primárních serverech. Vaše rezervní servery by měly být monitorovány pro příchozí replikaci a stav obnovy a vaše primární servery by měly být monitorovány z hlediska odchozích replikačních a replikačních slotů. Pokud používáte streamovací replikaci PostgreSQL, nejsou replikační sloty vždy vyžadovány. Streamová replikace zajišťuje okamžitou dostupnost dat na vašich záložních serverech a je ideální pro servery s nízkým TPS.
Využití CPU a RAM
Sledování využití CPU a RAM (paměti) jsou zásadní metriky, které je třeba sledovat, abyste zajistili stav vašich PostgreSQL serverů. Pokud je vaše využití procesoru příliš vysoké, vaše aplikace zaznamená zpomalení, takže vaši uživatelé budou trpět. Často je to důsledek špatně optimalizovaných dotazů nebo dokonce vysokého paralelismu dotazů. Monitorování paměti RAM je velmi důležité, abyste se ujistili, že máte dostatek místa na disku, a abyste přesně pochopili, k čemu se vaše RAM používá. Doporučuje se vyčlenit přibližně 25 % paměti pro sdílené vyrovnávací paměti. PostgreSQL také výchozí velikost vyrovnávací paměti pracovní paměti nastavuje na 4 MB, což je často příliš málo a má za následek dlouhé doby provádění.
Transakce za sekundu
Monitorování počtu transakcí za sekundu vám umožňuje určit zatížení systému a aktuální propustnost. Analýzou této metriky se lze rozhodnout odpovídajícím způsobem škálovat systém, aby bylo dosaženo požadované propustnosti. Můžete také určit, jak změna nastavení konfigurace nebo systémových prostředků ovlivní propustnost.
Pomalé dotazy
Neefektivní dotazy mohou zpomalit výkon PostgreSQL, i když je systém nakonfigurován s adekvátními zdroji. Vždy je dobré analyzovat tyto neefektivní dotazy a opravit je. PostgreSQL poskytuje parametr nazvaný log_min_duration_statement . Když je toto nastaveno, způsobí to, že se zaprotokoluje trvání každého dokončeného příkazu, pokud příkaz běžel alespoň po zadaný počet milisekund. Jakmile získáte pomalé dotazy, můžete spustit EXPLAIN ANALYZE, abyste pochopili plán provádění. To vám umožní sledovat problém a podle toho optimalizovat dotaz. Pravidelné sledování pomalých dotazů tedy zabrání zpomalení výkonu.
Najděte nás příští týden na události PostgresConf Silicon Valley 2018, kde doufáme, že odhalíme další poznatky o trendech v oblasti správy PostgreSQL. Pokud máte nějaké dotazy nebo komentáře, neváhejte je s námi sdílet zde v komentářích nebo na Twitteru na @scalegridio.
