Posledních pár měsíců jsme ve 2ndQuadrant pracovali na sloučení PostgreSQL 9.6 do Postgres-XL, což se ukázalo z různých důvodů jako docela náročné a kvůli několika invazivním upstream změnám to zabralo více času, než se původně plánovalo. Pokud vás to zajímá, podívejte se na oficiální úložiště zde (prozatím se podívejte na větev „master“).
Zbývá ještě udělat docela dost práce – sloučit pár zbývajících bitů z upstreamu, opravit známé chyby a selhání regrese, testovat atd. Pokud zvažujete přispět do Postgres-XL, je to ideální příležitost (zašlete mi e-mail a já vám pomohu s prvními kroky).
Celkově je však Postgres-XL 9.6 jednoznačně velkým krokem vpřed v řadě důležitých oblastí.
Nové funkce v Postgres-XL 9.6
Jaké nové funkce tedy Postgres-XL získává sloučením PostgreSQL 9.6? Mohl bych vás jednoduše odkázat na poznámky k upstream verzi – většina vylepšení se přímo vztahuje na XL 9.6, s výjimkou těch, které se týkají funkcí nepodporovaných na XL.
Hlavním uživatelsky viditelným vylepšením PostgreSQL 9.6 byl jednoznačně paralelní dotaz, a to platí také pro Postgres-XL 9.6.
Vnitrouzlový paralelismus
Před PostgreSQL 9.6 byl Postgres-XL jedním ze způsobů, jak získat paralelní dotazy (umístěním více uzlů Postgres-XL na stejný počítač). Od PostgreSQL 9.6 to již není nutné, ale také to znamená, že Postgres-XL získává schopnost paralelního intra-uzlu.
Pro srovnání, toto vám umožnil Postgres-XL 9.5 – distribuci dotazu do více datových uzlů, ale každý datový uzel stále podléhal limitu „jeden backend na dotaz“, stejně jako prostý PostgreSQL.
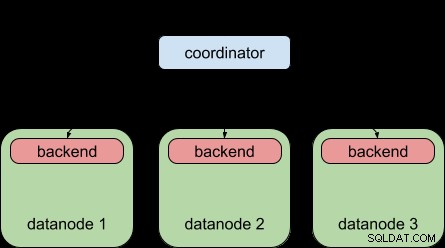
Díky funkci paralelního dotazu PostgreSQL 9.6 to nyní Postgres-XL 9.6 umí:
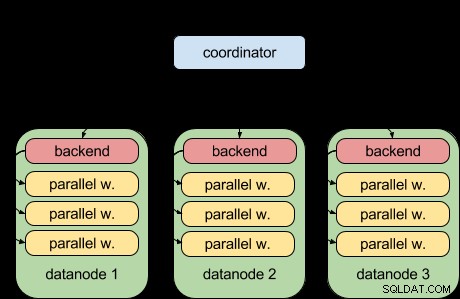
To znamená, že každý datový uzel nyní může spouštět svou část dotazu paralelně pomocí upstream infrastruktury paralelních dotazů. To je skvělé a Postgres-XL je mnohem výkonnější, pokud jde o analytické pracovní zátěže.
Údržba vidlice
Zmínil jsem se, že toto sloučení se ukázalo být náročnější, než jsme původně očekávali, a to z mnoha důvodů.
Za prvé, údržba forků je obecně obtížná, zvláště když se upstream projekt pohybuje tak rychle jako PostgreSQL. Musíte vyvinout vlastnosti specifické pro vaši vidlici, a proto vidlice na prvním místě existují. Ale také chcete držet krok s protiproudem, jinak beznadějně zaostáváte. Což je důvod, proč některé ze stávajících forků stále uvízly na PostgreSQL 8.x a postrádají všechny vychytávky od té doby.
Za druhé, sloučení bylo provedeno v jedné velké hrudce, stejně jako všechny předchozí (9.5, 9.2, …). To znamená, že všechny upstream commity byly sloučeny do jediného příkazu git merge. To je docela zaručeno, že způsobí spoustu konfliktů při začleňování do té míry, že se kód ani nezkompiluje, nemluvě o spuštění regresních testů nebo něčeho podobného.
Takže první várka oprav se týká uvedení do kompilovatelného stavu, další várka je o tom, aby to skutečně běželo bez okamžitých segfaultů, a pak konečně začne „běžná“ oprava (spustit regresní testy, opravit problémy, opláchnout a opakovat) .
Tyto složitosti jsou vlastní údržbě forku (a důvod, proč byste pravděpodobně měli znovu zvážit spuštění dalšího forku a místo toho přispívat přímo buď do Postgresu a/nebo Postgres-XL).
Existují však způsoby, jak výrazně snížit dopad – například plánujeme provést další sloučení (s PostgreSQL 10) po menších kouscích. To by mělo minimalizovat rozsah konfliktů sloučení a umožnit nám mnohem rychleji vyřešit selhání.
Blíže k PostgreSQL
Je zajímavé, že přijetí paralelismu z upstreamu nám také umožnilo zbavit se velkého množství kódu z kódové základny XL – ukázkovým příkladem toho je paralelní agregovaný kód, který snadno nahradil kód specifický pro XL.
Dalším příkladem upstream změny, která významně ovlivnila kód XL, je „patifikace“ horního plánovače, která byla prosazena pozdě ve vývojovém cyklu 9.6. To se ukázalo jako velmi invazivní změna (ve skutečnosti s ní pravděpodobně souvisí řada otevřených chyb), ale nakonec nám to umožnilo zjednodušit plánovací kód (v podstatě vytvořit správné cesty místo ladění výsledného plánu).
Když říkám, že sloučení nám umožnilo zjednodušit kód XL a přiblížit ho PostgreSQL, co tím myslím? Nejjednodušší způsob, jak kvantifikovat změnu, je provést „git diff –stat“ proti odpovídající větvi proti proudu a porovnat čísla. Pro větve 9.5 a 9.6 vypadají výsledky takto:
| verze | soubory změněny | přídavky | smazání |
|---|---|---|---|
| XL 9.5 | 1099 | 234509 | 18336 |
| XL 9.6 | 1051 | 201158 | 17627 |
| delta | -48 (-4,3 %) | -33351 (-14,2 %) | -709 (-3,8 %) |
Je zřejmé, že sloučení 9.6 výrazně snižuje deltu proti upstreamu (celkem o ~14 %). Kde se bere tento rozdíl?
Za prvé, určité snížení je způsobeno skutečným zjednodušením kódu. Ukázkovým příkladem toho je paralelní agregace, která je v podstatě náhradou 1:1 původní implementace Postgres-XL. Takže jsme to právě vytrhli a místo toho jsme použili upstream implementaci. Doufáme, že v budoucnu najdeme více takových míst a namísto udržování vlastní implementace použijeme upstream implementaci.
Za druhé, velká část snížení pochází z odstranění mrtvého kódu. Nejen, že jsme zredukovali některé mrtvé/nedosažitelné části kódu, ale také jsme objevili několik zdrojových souborů, které ani nebyly zkompilovány, a tak dále.
Co bude dál?
V tomto bodě jsme sloučili změny až do b5bce6c1, což je místo, kde se PostgreSQL 9.6 oddělil od hlavního. Abychom dohnali PostgreSQL 9.6.2, musíme sloučit zbývající změny ve větvi 9.6. Vzhledem k tomu, že by měly být většinou pouze opravy chyb, měla by to být (doufejme) poměrně jednoduchá práce ve srovnání s úplným začleněním.
Chyby samozřejmě budou. Ve skutečnosti v tomto bodě stále existuje několik neúspěšných regresních testů. To je třeba opravit před oficiálním vydáním XL 9.6. A musíme provést další testování, takže pokud máte zájem pomoci Postgres-XL, bylo by to mimořádně přínosné.
Jedna nepříjemnost, o které stále slýcháme, jsou balíčky nebo jejich nedostatek. Možná jste si všimli, že poslední dostupné balíčky jsou poměrně staré a je tam jen .rpm, nic jiného. Plánujeme to vyřešit a začít nabízet aktuální balíčky v několika příchutích (např. .rpm a .deb).
Plánujeme také provést určité změny ve způsobu organizace vývojového procesu, aby bylo snazší přispívat a účastnit se procesu vývoje. To je opravdu samostatné téma, které nesouvisí s větví 9.6, takže o něm za pár dní zveřejním další podrobnosti.