NE použijte indexy kromě jedinečného jediného číselného klíče.
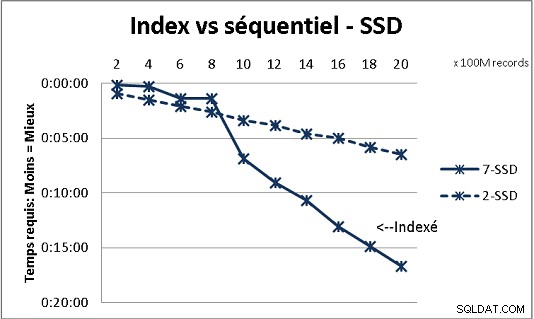
To se neslučuje s celou teorií DB, kterou jsme obdrželi, ale testování s velkým množstvím dat to ukazuje. Zde je výsledek 100 milionů zatížení najednou, aby se dosáhlo 2 miliard řádků v tabulce, a pokaždé spousta různých dotazů ve výsledné tabulce. První grafika s 10gigabitovým NAS (150 MB/s), druhá se 4 SSD v RAID 0 (R/W @ 2 GB/s).
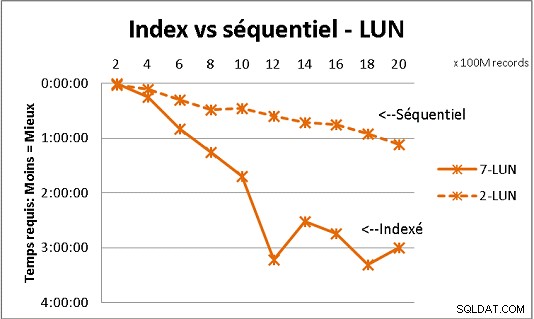
Pokud máte v tabulce na běžných discích více než 200 milionů řádků, je rychlejší, když zapomenete indexy. Na SSD je limit 1 miliarda.
Pro lepší výsledky jsem to udělal také s oddíly, ale s PG9.2 je obtížné z nich těžit, pokud používáte uložené procedury. Musíte se také postarat o zápis/čtení pouze do 1 oddílu najednou. Nicméně oddíly jsou způsob, jak udržet vaše stoly pod zdí 1 miliardy. Také to hodně pomáhá pro vícenásobné zpracování vašich nákladů. S SSD mi jeden proces umožňuje vložit (zkopírovat) 18 000 řádků/s (včetně některých prací na zpracování). S multiprocessingem na 6 CPU roste na 80 000 řádků/s.
Při testování sledujte využití CPU a IO, abyste obojí optimalizovali.