Proč zvolit replikaci MySQL?
Nejprve několik základních informací o technologii replikace. Replikace MySQL není složitá! Je snadné jej implementovat, monitorovat a ladit, protože můžete využít různé zdroje – jedním z nich je Google. Replikace MySQL neobsahuje mnoho konfiguračních proměnných k vyladění. Logické chyby SQL_THREAD a IO_THREAD není tak těžké pochopit a opravit. MySQL Replication je v dnešní době velmi populární a nabízí jednoduchý způsob implementace databáze High Availability. Výkonné funkce, jako je GTID (Global Transaction Identifier) namísto staromódní pozice binárního protokolu, nebo bezztrátová semi-synchronní replikace jej činí robustnějším.
Jak jsme viděli v předchozím příspěvku, latence sítě je velkou výzvou při výběru řešení s vysokou dostupností. Použití replikace MySQL nabízí výhodu, že není tak citlivá na latenci. Neimplementuje žádnou replikaci založenou na certifikaci, na rozdíl od Galera Cluster využívá skupinovou komunikaci a techniky objednávání transakcí k dosažení synchronní replikace. Není tedy vyžadováno, aby všechny uzly musely certifikovat sadu zápisů, a není třeba čekat před potvrzením na druhém podřízeném zařízení nebo replice.
Výběr tradiční replikace MySQL s asynchronním primárním a sekundárním přístupem vám poskytne rychlost, pokud jde o zpracování transakcí z vašeho hlavního serveru; nemusí čekat, až se podřízené jednotky synchronizují nebo potvrdí transakce. Nastavení má obvykle primární (master) a jeden nebo více sekundárních (slave). Jde tedy o sdílený systém, kde všechny servery mají ve výchozím nastavení úplnou kopii dat. Samozřejmě existují nevýhody. Integrita dat může být problémem, pokud se vaše podřízené jednotky nepodařilo replikovat kvůli chybám SQL a I/O vláken nebo selhání. Alternativně k řešení problémů s integritou dat můžete zvolit implementaci replikace MySQL, která bude semisynchronní (nebo se v MySQL 5.7 nazývá bezztrátová semisynchronní replikace). Funguje to tak, že hlavní server musí počkat, dokud replika nepotvrdí všechny události transakce. To znamená, že musí dokončit své zápisy do protokolu přenosu a vyprázdnit na disk, než odešle zpět na master s odpovědí ACK. S povolenou semisynchronní replikací musí vlákna nebo relace v hlavním serveru čekat na potvrzení z repliky. Jakmile dostane odpověď ACK od repliky, může transakci potvrdit. Obrázek níže ukazuje, jak MySQL zpracovává semisynchronní replikaci.
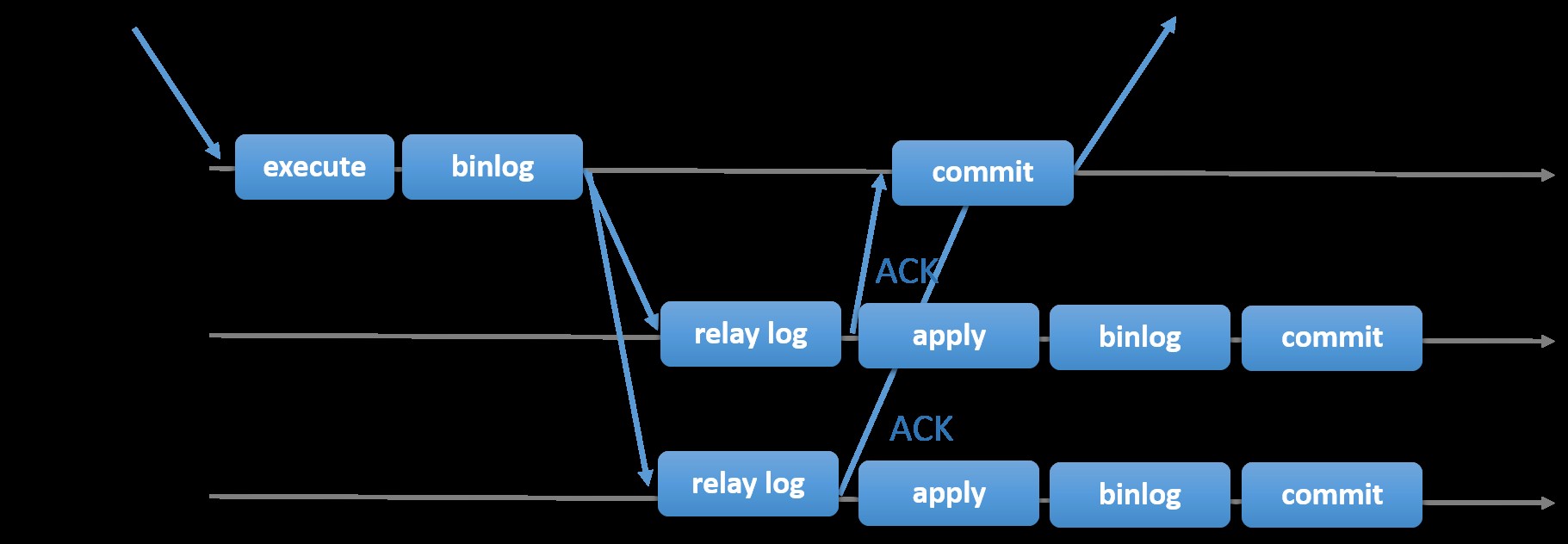 Obrázek s laskavým svolením dokumentace MySQL
Obrázek s laskavým svolením dokumentace MySQL S touto implementací jsou všechny potvrzené transakce již replikovány na alespoň jeden slave v případě hlavního selhání. Semi-synchronous sice sám o sobě nepředstavuje řešení s vysokou dostupností, ale je to komponenta pro vaše řešení. Nejlepší je znát své potřeby a podle toho vyladit implementaci semi-synchronizace. Pokud je tedy nějaká ztráta dat přijatelná, můžete místo toho použít tradiční asynchronní replikaci.
Replikace založená na GTID je pro DBA užitečná, protože zjednodušuje úkol provést převzetí služeb při selhání, zvláště když je podřízený server nasměrován na jiného hlavního nebo nového hlavního serveru. To znamená, že s jednoduchým MASTER_AUTO_POSITION=1 po nastavení správných přihlašovacích údajů hostitele a replikace se zahájí replikace z hlavního serveru, aniž by bylo nutné hledat a specifikovat správné pozice binárního log x &y. Přidání podpory paralelní replikace také zvyšuje rychlost replikačních vláken, protože zvyšuje rychlost zpracování událostí z protokolu přenosu.
Replikace MySQL je tedy skvělou volbou oproti jiným řešením HA, pokud vyhovuje vašim potřebám.
Topologie pro replikaci MySQL
Nasazení replikace MySQL v multicloudovém prostředí s GCP (Google Cloud Platform) a AWS je stále stejný přístup, pokud musíte replikovat on-prem.
Existují různé topologie, které můžete nastavit a implementovat.
Hlavní s replikací Slave (Single Replication)
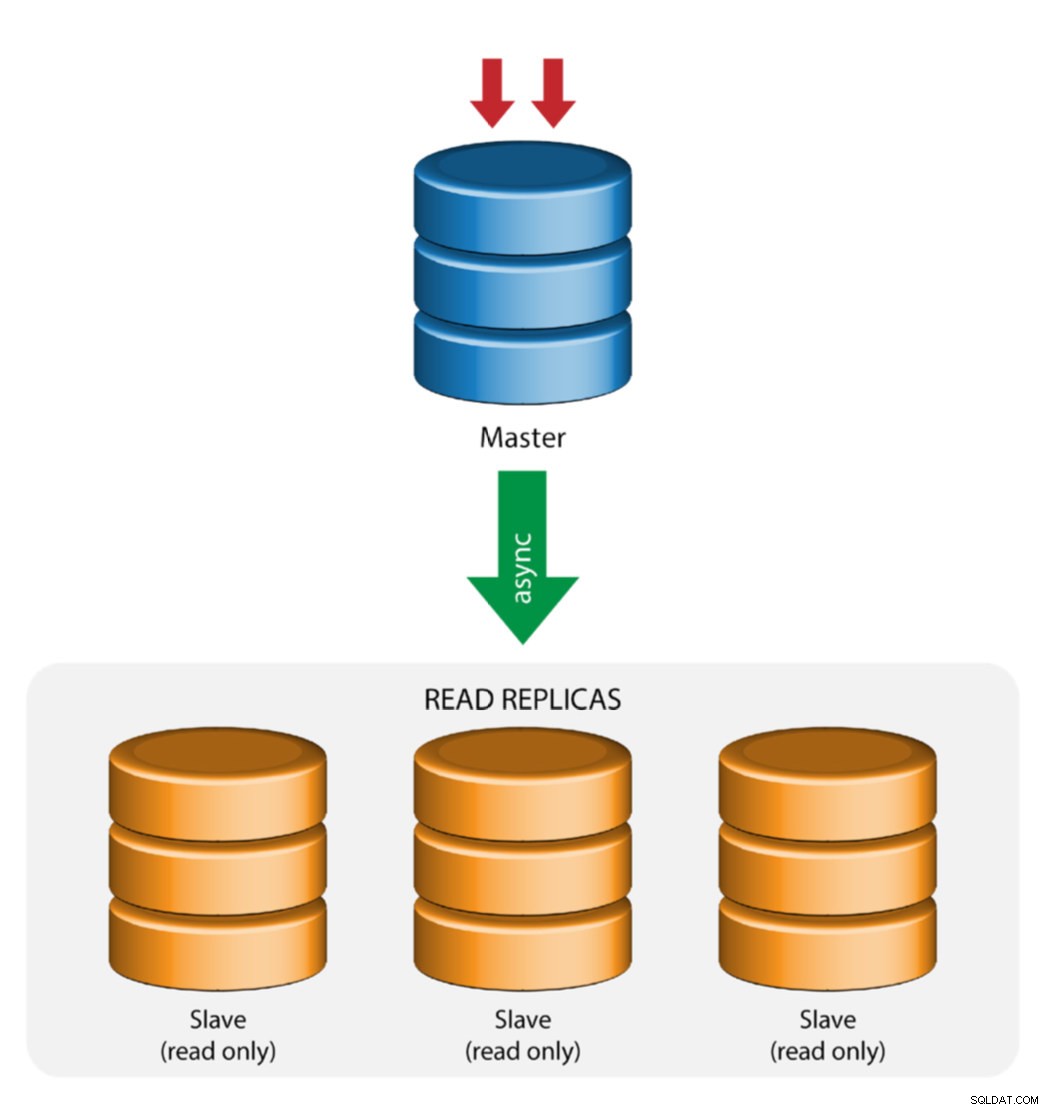
Toto je nejpřímější topologie replikace MySQL. Jeden master přijímá zápisy, jeden nebo více slave se replikuje ze stejného masteru prostřednictvím asynchronní nebo semisynchronní replikace. Pokud určený master selže, musí být nejaktuálnější slave povýšen jako nový master. Zbývající podřízené jednotky obnoví replikaci z nového hlavního serveru.
Master s reléovými podřízenými jednotkami (řetězová replikace)
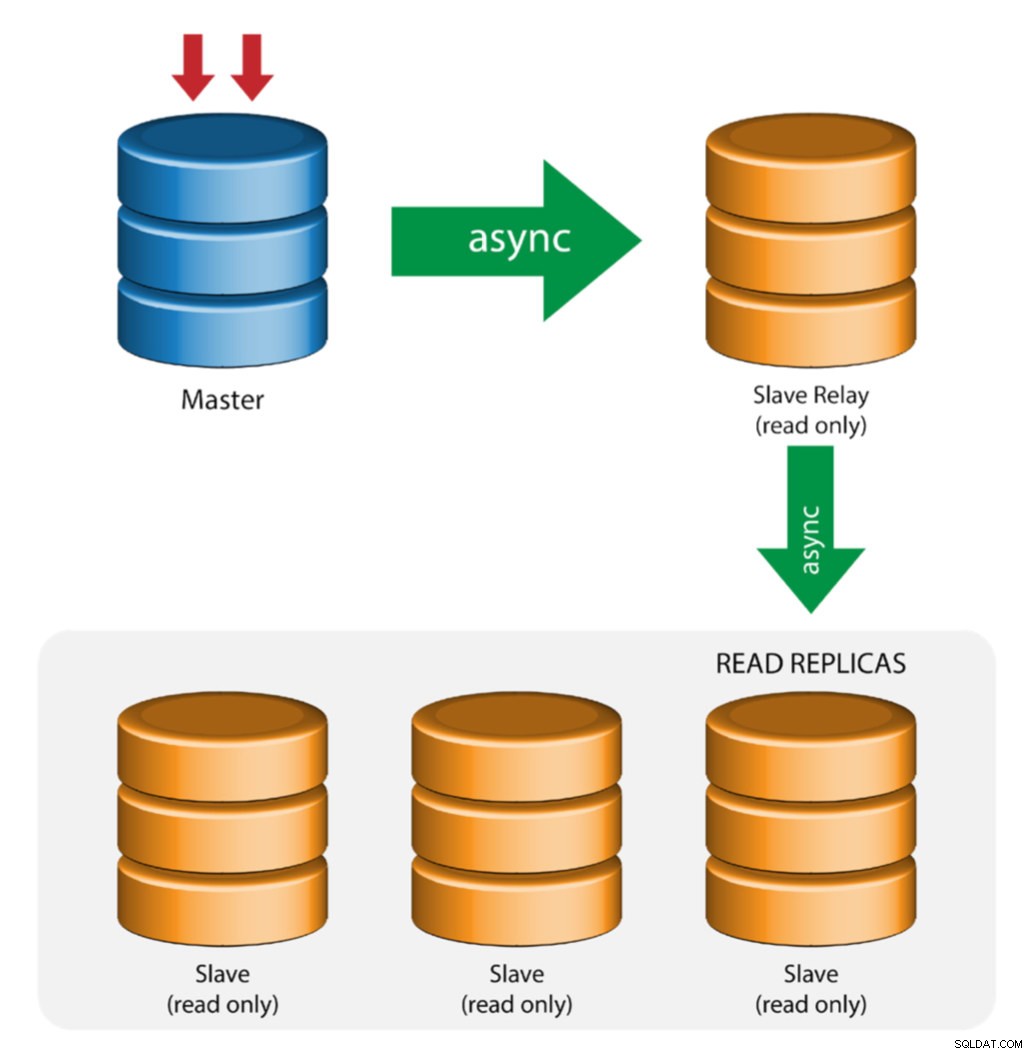
Toto nastavení používá zprostředkujícího hlavního serveru, který funguje jako přenos pro ostatní podřízené jednotky v řetězci replikace. Pokud je k masteru připojeno mnoho slave, může dojít k přetížení síťového rozhraní masteru. Tato topologie umožňuje čteným replikám stáhnout datový proud replikace z předávacího serveru a snížit zátěž hlavního serveru. Na podřízeném předávacím serveru musí být povoleno binární protokolování a log_slave_updates, přičemž aktualizace přijaté podřízeným serverem z hlavního serveru se zaznamenávají do vlastního binárního protokolu podřízeného serveru.
Použití slave relé má své problémy:
- log_slave_updates má určité snížení výkonu.
- Prodleva replikace na podřízeném předávacím serveru způsobí zpoždění na všech podřízených podřízených serverech.
- Nečestné transakce na podřízeném předávacím serveru infikují všechny jeho podřízené.
- Pokud selže podřízený přenosový server a vy nepoužíváte GTID, všechny jeho podřízené servery se přestanou replikovat a je třeba je znovu inicializovat.
Master s aktivním masterem (kruhová replikace)
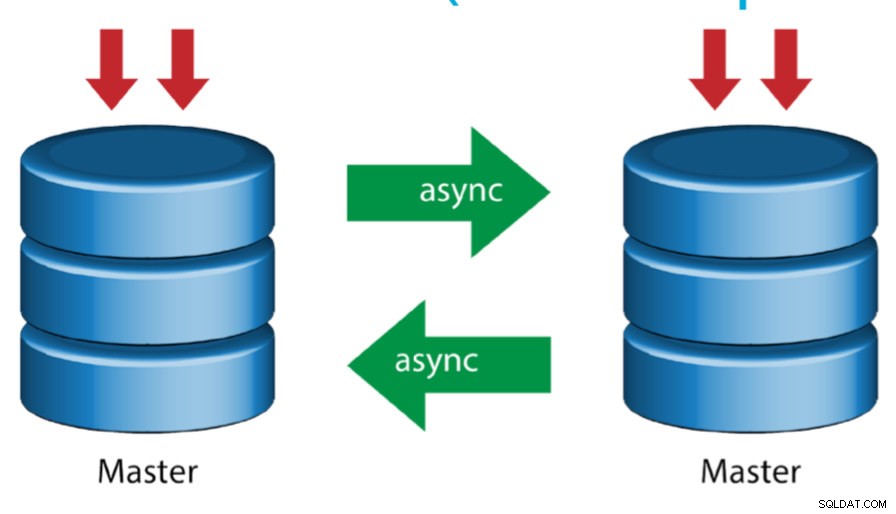
Toto nastavení, známé také jako kruhová topologie, vyžaduje dva nebo více serverů MySQL, které fungují jako hlavní. Všichni master přijímají zápisy a generují binlogy s několika upozorněními:
- Abyste předešli kolizím primárního klíče, musíte na každém serveru nastavit posun automatického přírůstku.
- Neexistuje žádné řešení konfliktu.
- Replikace MySQL v současné době nepodporuje žádný uzamykací protokol mezi master a slave, aby byla zaručena atomičnost distribuované aktualizace na dvou různých serverech.
- Běžnou praxí je zapisovat pouze do jednoho masteru a druhý master funguje jako hot-standby uzel. Pokud však máte podřízené jednotky pod touto úrovní, musíte v případě selhání určeného hlavního zařízení ručně přepnout na nový hlavní server.
- ClusterControl tuto topologii podporuje (nedoporučujeme více zapisovačů v nastavení replikace). Podívejte se na tento předchozí blog o tom, jak nasadit ClusterControl.
Hlavní se záložním hlavním serverem (vícenásobná replikace)
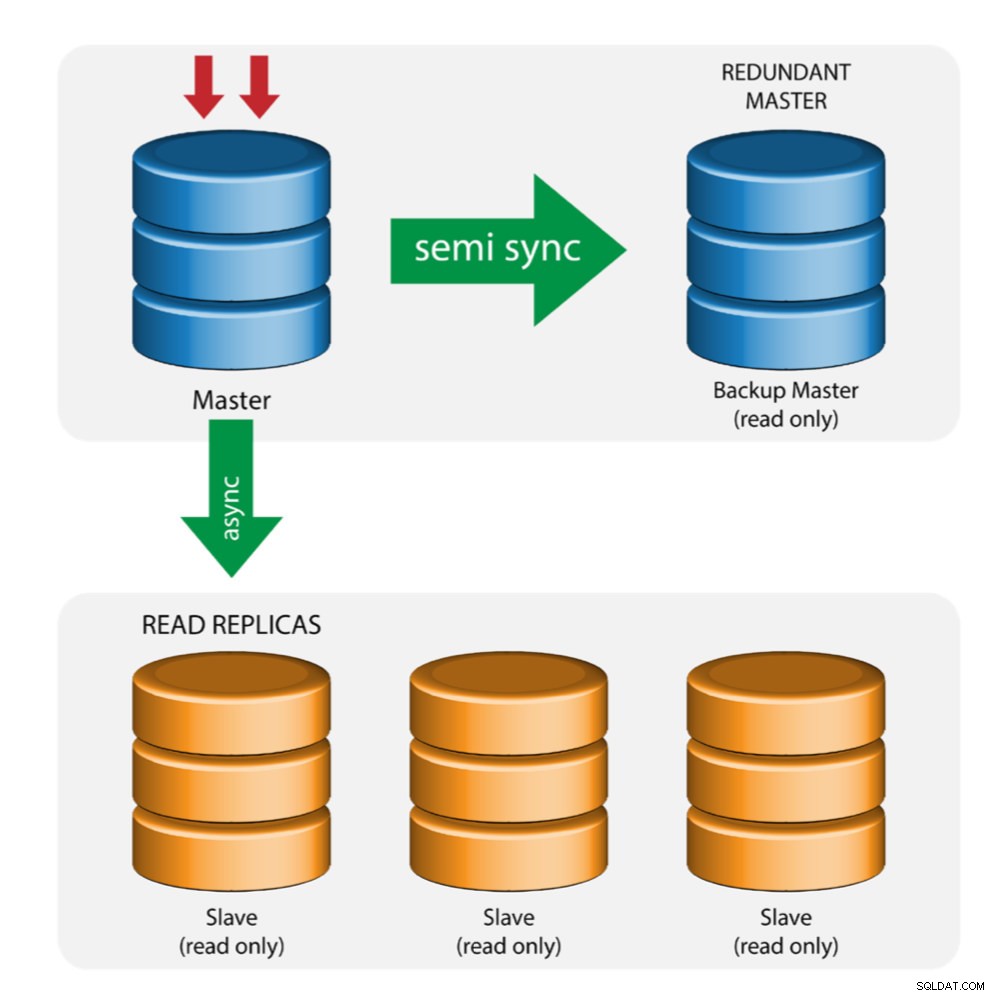
Master předává změny záložnímu masteru a jednomu nebo více podřízeným. Mezi hlavním a záložním hlavním serverem se používá semisynchronní replikace. Master odešle aktualizaci záložnímu masteru a čeká s potvrzením transakce. Backup master získává aktualizace, zapisuje do svého protokolu přenosu a vyprázdní se na disk. Záložní hlavní server pak potvrdí příjem transakce hlavnímu serveru a pokračuje v potvrzení transakce. Polosynchronní replikace má vliv na výkon, ale riziko ztráty dat je minimalizováno.
Tato topologie funguje dobře při provádění hlavního převzetí služeb při selhání v případě, že hlavní server selže. Zálohovací hlavní server funguje jako server v teplém pohotovostním režimu, protože má nejvyšší pravděpodobnost, že bude mít aktuální data ve srovnání s jinými podřízenými zařízeními.
Multiple Master to Single Slave (Multi-Source Replication)
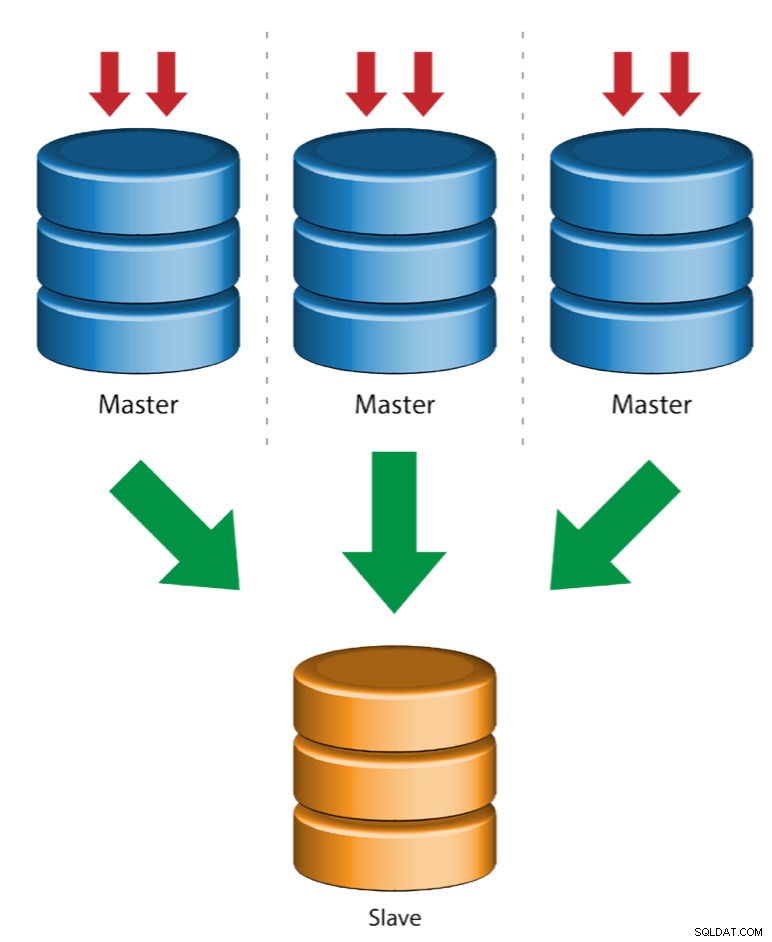
Multi-Source Replication umožňuje podřízenému replikačnímu zařízení přijímat transakce z více zdrojů současně. Replikaci z více zdrojů lze použít k zálohování více serverů na jeden server, ke sloučení fragmentů tabulek a konsolidaci dat z více serverů na jeden server.
MySQL a MariaDB mají různé implementace replikace z více zdrojů, kde MariaDB musí mít GTID s gtid-domain-id nakonfigurovaným k rozlišení původních transakcí, zatímco MySQL používá samostatný replikační kanál pro každého mastera, ze kterého se slave replikuje. V MySQL lze mastery v topologii replikace s více zdroji nakonfigurovat tak, aby používali replikaci založenou na identifikátoru globální transakce (GTID) nebo replikaci založenou na pozici binárního protokolu.
Více o replikaci více zdrojů MariaDB naleznete v tomto příspěvku na blogu. Informace o MySQL naleznete v dokumentaci MySQL.
Galera s Replication Slave (Hybrid Replication)
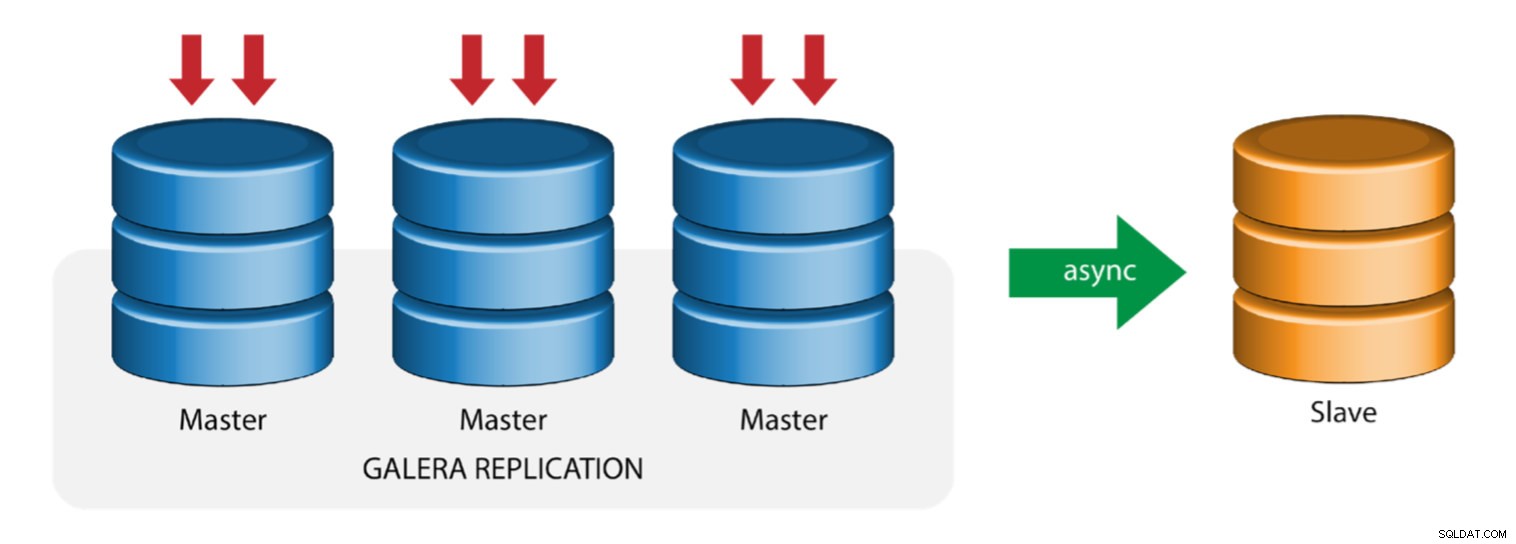
Hybridní replikace je kombinací asynchronní replikace MySQL a virtuálně synchronní replikace poskytované společností Galera. Nasazení je nyní zjednodušeno díky implementaci GTID v replikaci MySQL, kde se nastavení a provedení hlavního failover stalo přímočarým procesem na straně slave.
Výkon clusteru Galera je stejně rychlý jako nejpomalejší uzel. Asynchronní replikační slave může minimalizovat dopad na klastr, pokud na slave posíláte dlouhotrvající dotazy typu OLAP nebo pokud provádíte náročné úlohy, které vyžadují zámky jako mysqldump. Slave může také sloužit jako živá záloha pro obnovu po havárii na místě i mimo něj.
Hybridní replikace je podporována ClusterControl a můžete ji nasadit přímo z uživatelského rozhraní ClusterControl. Další informace o tom, jak to udělat, si přečtěte v příspěvcích na blogu – Hybridní replikace s MySQL 5.6 a Hybridní replikace s MariaDB 10.x.
Příprava platforem GCP a AWS
Problém ve "skutečném světě"
V tomto blogu předvedeme a použijeme topologii „Multiple Replication“, ve které budou instance na dvou různých veřejných cloudových platformách komunikovat pomocí replikace MySQL v různých regionech a v různých zónách dostupnosti. Tento scénář je založen na skutečném problému, kdy organizace chce svou infrastrukturu navrhnout na více cloudových platformách pro škálovatelnost, redundanci, odolnost/odolnost vůči chybám. Podobné koncepty by platily pro MongoDB nebo PostgreSQL.
Vezměme si americkou organizaci se zámořskou pobočkou v jihovýchodní Asii. Náš provoz je v regionu se sídlem v Asii vysoký. Latence musí být nízká při zajišťování zápisů a čtení, ale zároveň region se sídlem v USA může také stahovat záznamy pocházející z provozu z Asie.
Tok cloudové architektury
V této části se budu zabývat architektonickým návrhem. Za prvé, chceme nabídnout vysoce zabezpečenou vrstvu, pro kterou mohou naše uzly Google Compute a AWS EC2 komunikovat, aktualizovat nebo instalovat balíčky z internetu, zabezpečenou, vysoce dostupnou v případě výpadku AZ (zóna dostupnosti), mohou se replikovat a komunikovat s jinou cloudovou platformou přes zabezpečenou vrstvu. Pro ilustraci viz obrázek níže:

Na základě výše uvedeného obrázku jsou na platformě AWS všechny uzly spuštěny v různých zónách dostupnosti. Má soukromou a veřejnou podsíť, pro kterou jsou všechny výpočetní uzly v soukromé podsíti. Proto může jít mimo internet a v případě potřeby stáhnout a aktualizovat své systémové balíčky. Má bránu VPN, pro kterou musí komunikovat s GCP v tomto kanálu a obcházet internet, ale prostřednictvím zabezpečeného a soukromého kanálu. Stejně jako GCP jsou všechny výpočetní uzly v různých zónách dostupnosti, použijte NAT Gateway k aktualizaci systémových balíčků v případě potřeby a použijte připojení VPN k interakci s uzly AWS, které jsou hostovány v jiném regionu, například v Asii a Tichomoří (Singapur). Na druhou stranu je region se sídlem v USA hostován pod us-východ1. Pro přístup k uzlům slouží jeden uzel v architektuře jako bastion-node, pro který jej použijeme jako hostitele skoku a nainstalujeme ClusterControl. Tomu se budeme věnovat později v tomto blogu.
Nastavení prostředí GCP a AWS
Při registraci vašeho prvního účtu GCP vám Google poskytne výchozí účet VPC (Virtual Private Cloud). Proto je nejlepší vytvořit samostatný VPC, než je výchozí, a upravit jej podle svých potřeb.
Naším cílem je umístit výpočetní uzly do soukromých podsítí nebo uzly nebudou nastaveny s veřejným IPv4. Oba veřejné cloudy tedy musí být schopny spolu komunikovat. Výpočtové uzly AWS a GCP pracují s různými CIDR, jak již bylo zmíněno. Zde jsou tedy následující CIDR:
Výpočetní uzly AWS: 172.21.0.0/16
Výpočetní uzly GCP: 10.142.0.0/20
V tomto nastavení AWS jsme alokovali tři podsítě, které nemají žádnou internetovou bránu, ale bránu NAT; a jednu podsíť, která má internetovou bránu. Každá z těchto podsítí je hostována samostatně v různých zónách dostupnosti (AZ).
ap-southeast-1a =172.21.1.0/24
ap-jihovýchod-1b =172.21.8.0/24
ap-jihovýchod-1c =172.21.24.0/24
V GCP se používá výchozí podsíť vytvořená ve VPC pod us-east1, což je 10.142.0.0/20 CIDR. Toto jsou tedy kroky, podle kterých můžete nastavit svou platformu pro více veřejných cloudů.
-
Pro toto cvičení jsem vytvořil VPC v regionu us-east1 s následující podsítí 10.142.0.0/20. Viz níže:

-
Rezervujte si statickou IP. Toto je IP adresa, kterou nastavíme jako zákaznickou bránu v AWS
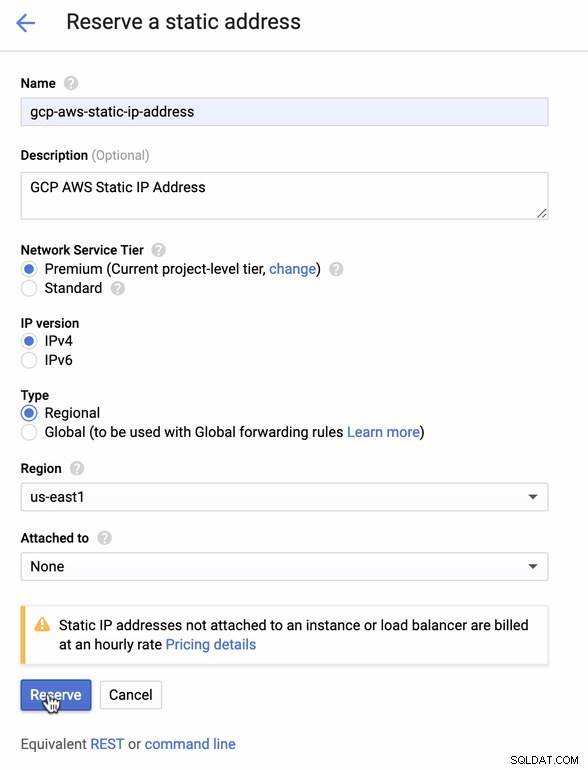
-
Protože máme podsítě (poskytované jako subnet-us-east1 ), přejděte na GCP -> Síť VPC -> Sítě VPC a vyberte VPC, které jste vytvořili, a přejděte na Pravidla brány firewall . V této části přidejte pravidla zadáním svého vstupu a výstupu. V zásadě se jedná o příchozí/odchozí pravidla v AWS nebo vašem firewallu pro příchozí a odchozí připojení. V tomto nastavení jsem otevřel všechny TCP protokoly z rozsahu CIDR nastaveného v mém AWS a GCP VPC, abych to zjednodušil pro účely tohoto blogu. Proto to není optimální způsob zabezpečení. Viz obrázek níže:
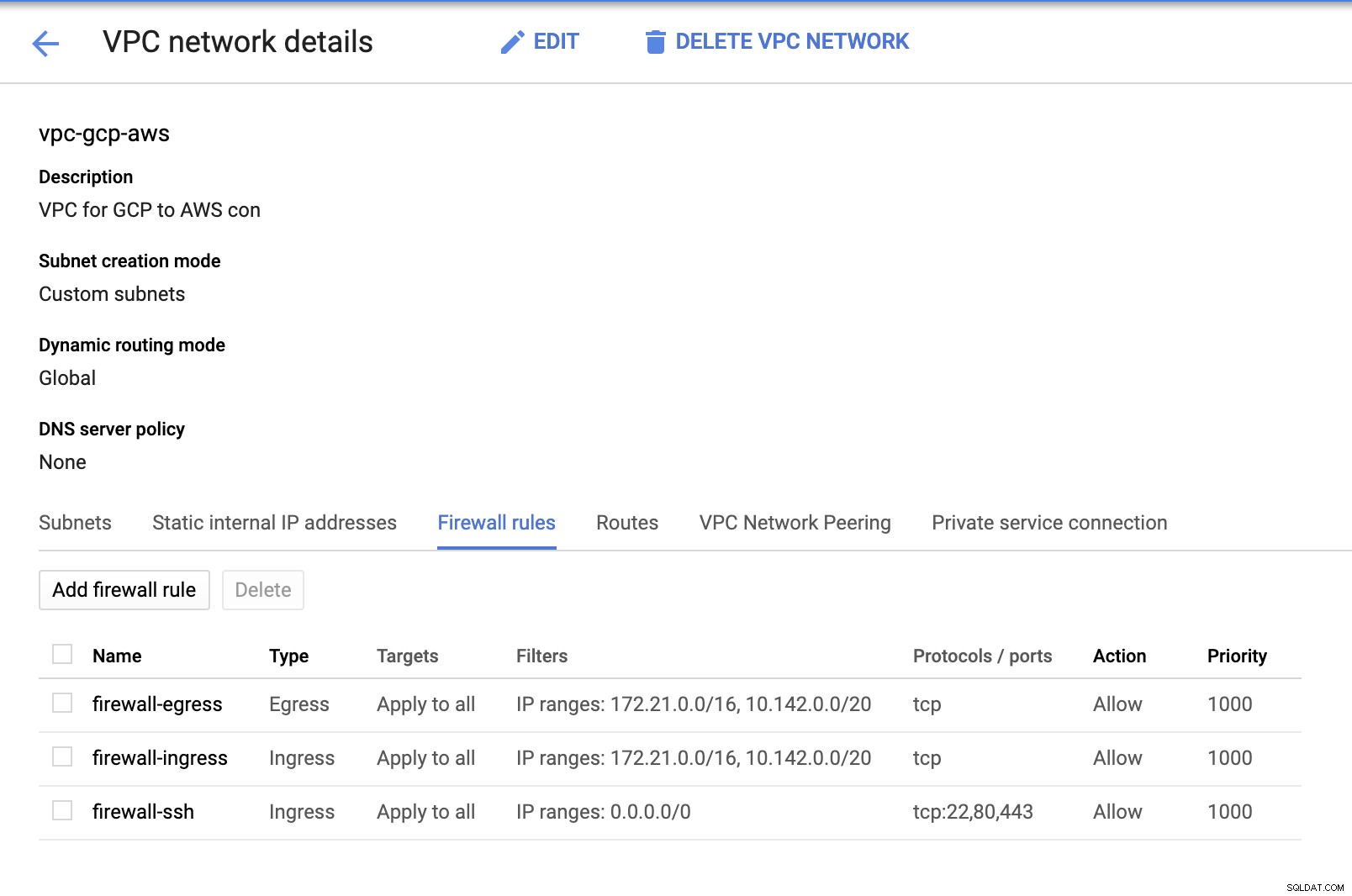
Firewall-ssh zde bude použit k povolení příchozích připojení ssh, HTTP a HTTPS.
-
Nyní přepněte na AWS a vytvořte VPC. Pro tento blog jsem použil CIDR (Classless Inter-Domain Routing) 172.21.0.0/16
-
Vytvořte podsítě, pro které je musíte přiřadit v každé AZ (zóně dostupnosti); a alespoň jednu podsíť vyhradit pro veřejnou podsíť, která bude obsluhovat bránu NAT, a zbytek je pro uzly EC2.

-
Dále vytvořte svou tabulku tras a ujistěte se, že jsou správně nastaveny „Cíl“ a „Cíle“. Pro tento blog jsem vytvořil 2 tabulky tras. Jeden, který zvládne 3 AZ, které budou mé výpočetní uzly přiřazeny jednotlivě a budou přiřazeny bez internetové brány, protože nebude mít žádnou veřejnou IP. Druhý bude ovládat bránu NAT a bude mít internetovou bránu, která bude ve veřejné podsíti. Viz obrázek níže:

a jak již bylo zmíněno, můj příklad cíle pro soukromou cestu, která zpracovává 3 podsítě, ukazuje, že má cíl brány NAT plus cíl virtuální brány, o kterém se zmíním později v následujících krocích.

-
Dále vytvořte „Internet Gateway“ a přiřaďte ji k VPC, které bylo dříve vytvořeno v sekci AWS VPC. Tato internetová brána může být nastavena pouze jako cíl veřejné podsítě, protože to bude služba, která se musí připojit k internetu. Je zřejmé, že název znamená službu internetové brány.
-
Dále vytvořte „bránu NAT“. Při vytváření „brány NAT“ se ujistěte, že jste svůj NAT přiřadili k veřejné podsíti. NAT Gateway je váš kanál pro přístup k internetu z vaší privátní podsítě nebo EC2 uzlů, které nemají přidělenou veřejnou IPv4. Poté vytvořte nebo přiřaďte EIP (Elastic IP), protože v AWS se mohou k internetu přímo připojit pouze výpočetní uzly, které mají přidělenou veřejnou IPv4.
-
Nyní pod VPC -> Zabezpečení -> Skupiny zabezpečení (SG) , váš vytvořený VPC bude mít výchozí SG. Pro toto nastavení jsem vytvořil „Příchozí pravidla“ se zdroji přiřazenými pro každý CIDR, tj. 10.142.0.0/20 v GCP a 172.21.0.0/16 v AWS. Viz níže:

U „Odchozích pravidel“ to můžete ponechat tak, jak je, protože přiřazení pravidel k „Příchozím pravidlům“ je dvoustranné, což znamená, že se otevře také pro „Odchozí pravidla“. Vezměte na vědomí, že toto není optimální způsob nastavení vaší skupiny zabezpečení; ale pro usnadnění tohoto nastavení jsem vytvořil širší rozsah portů a zdrojů. Protokol je také specifický pouze pro připojení TCP, protože pro tento blog se nebudeme zabývat UDP.
Kromě toho můžete ponechat své VPC -> Zabezpečení -> Síťové ACL nedotčené, pokud neodmítá žádná připojení tcp z CIDR uvedeného ve vašem zdroji. -
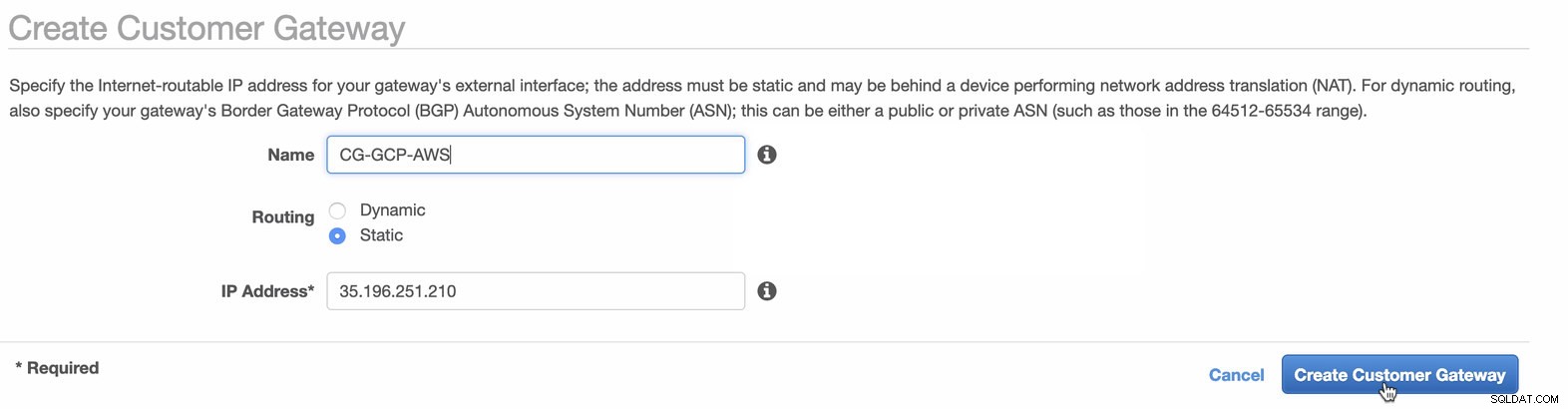
Dále nastavíme konfiguraci VPN, která bude hostována na platformě AWS. V části VPC -> Zákaznické brány , vytvořte bránu pomocí statické IP adresy, která byla vytvořena dříve v předchozím kroku. Podívejte se na obrázek níže:
-
Dále vytvořte virtuální privátní bránu a připojte ji k aktuální VPC, kterou jsme vytvořili dříve v předchozím kroku. Viz obrázek níže:

-
Nyní vytvořte připojení VPN, které bude použito pro připojení mezi weby mezi AWS a GCP. Při vytváření připojení VPN se ujistěte, že jste vybrali správnou virtuální privátní bránu a zákaznickou bránu, kterou jsme vytvořili v předchozích krocích. Viz obrázek níže:
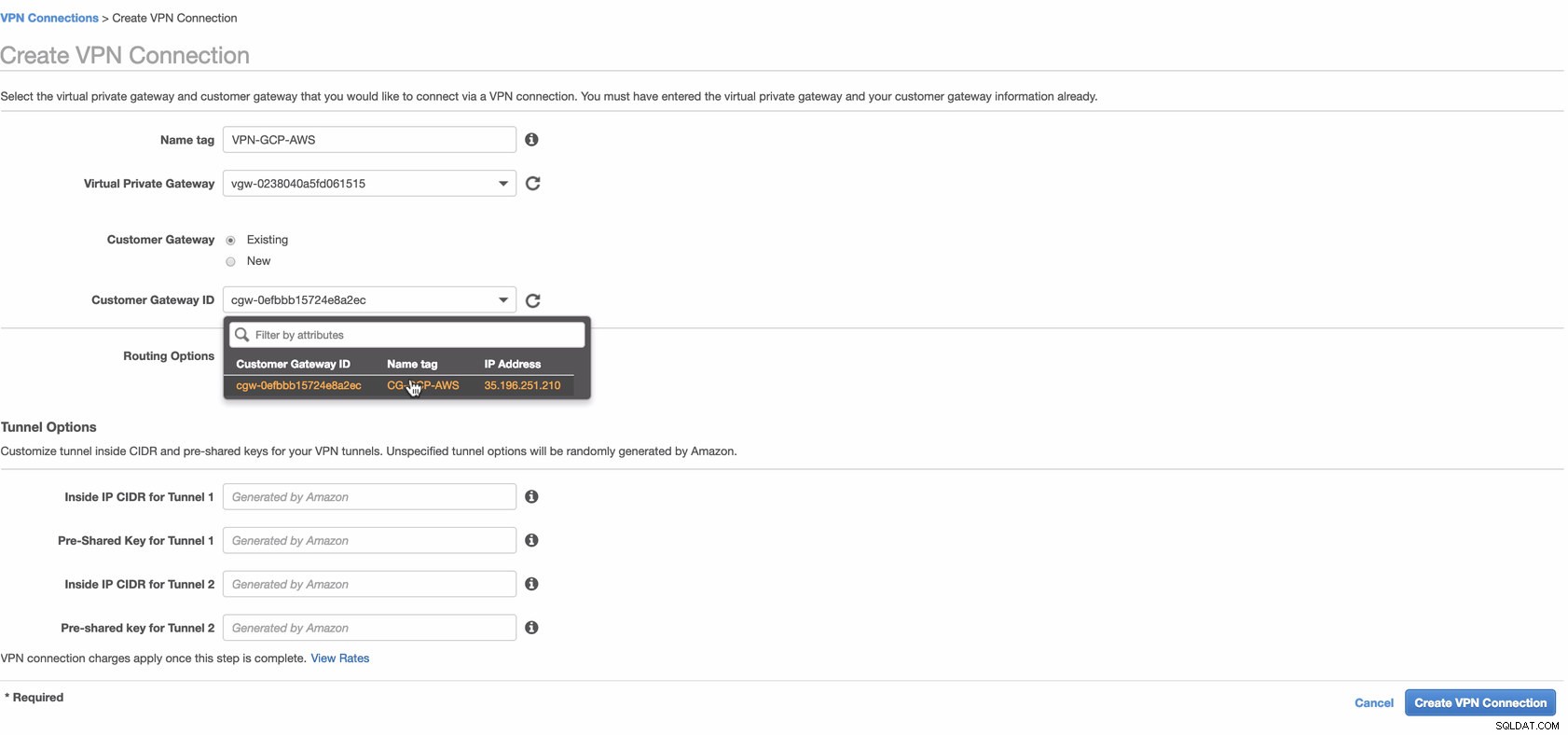
To může chvíli trvat, než AWS vytvoří vaše připojení VPN. Když je pak vaše připojení VPN zřízeno, možná se divíte, proč se na kartě Tunel (po výběru připojení VPN) zobrazí, že Vnější IP adresa je dole. To je normální, protože od klienta dosud nebylo navázáno žádné spojení. Podívejte se na ukázkový obrázek níže:

Jakmile je připojení VPN připraveno, vyberte vytvořené připojení VPN a stáhněte si konfiguraci. Obsahuje vaše přihlašovací údaje potřebné pro následující kroky k vytvoření připojení VPN typu site-to-site s klientem.
Poznámka: V případě, že jste nastavili svou VPN tam, kde IPSEC JE UP ale Stav je DOLŮ stejně jako na obrázku níže

je to pravděpodobně kvůli nesprávným hodnotám nastaveným na konkrétní parametry při nastavování relace BGP nebo cloudového routeru. Podívejte se zde na odstraňování problémů s vaší VPN.
-
Protože máme připravené připojení VPN hostované v AWS, vytvořte připojení VPN v GCP. Nyní se vraťme do GCP a nastavíme tam klientské připojení. V GCP přejděte na GCP -> Hybridní připojení -> VPN . Ujistěte se, že vybíráte správný region, který je na tomto blogu, používáme us-east1 . Poté vyberte statickou IP adresu vytvořenou v předchozích krocích. Viz obrázek níže:
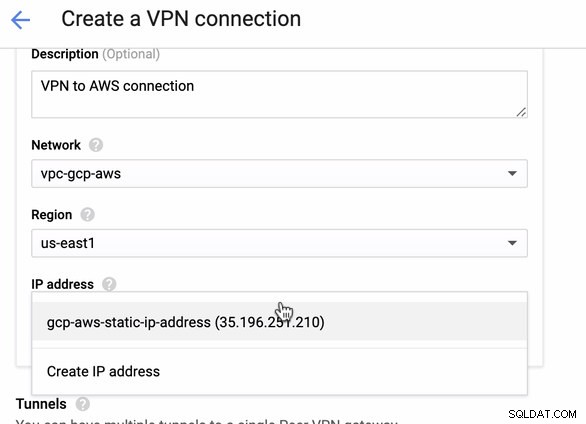
Poté v tunelech Zde budete muset provést nastavení na základě stažených přihlašovacích údajů z připojení AWS VPN, které jste vytvořili dříve. Doporučuji prostudovat si tohoto užitečného průvodce od Googlu. Například jeden z nastavovaných tunelů je zobrazen na obrázku níže:
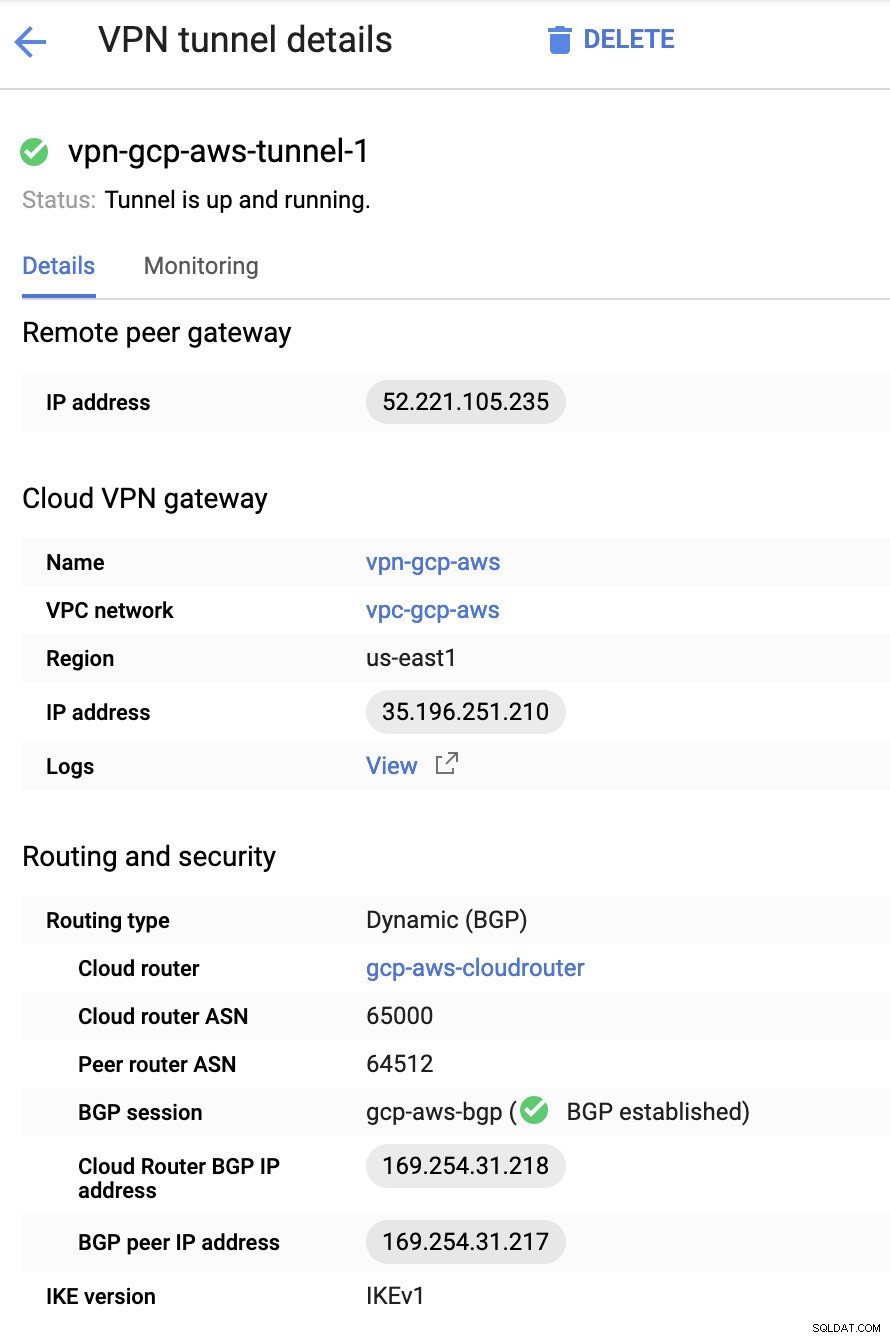
V zásadě jsou nejdůležitější následující věci:
- Vzdálená brána peer:IP adresa – Toto je adresa IP serveru VPN uvedená v části Podrobnosti tunelu -> Vnější adresa IP . Nepleťte si to se statickou IP, kterou jsme vytvořili v rámci GCP. To je Cloudová brána VPN -> IP adresa ačkoli.
- Cloud router ASN – Ve výchozím nastavení používá AWS 65000. Tyto informace však pravděpodobně získáte ze staženého konfiguračního souboru.
- ASN peer routeru – toto je ASN virtuální privátní brány který se nachází ve staženém konfiguračním souboru.
- IP adresa BGP cloudového routeru – toto je brána zákazníka naleznete ve staženém konfiguračním souboru.
- BGP peer IP adresa – Toto je Virtual Private Gateway naleznete ve staženém konfiguračním souboru.
-
Podívejte se na příklad konfiguračního souboru, který mám níže:
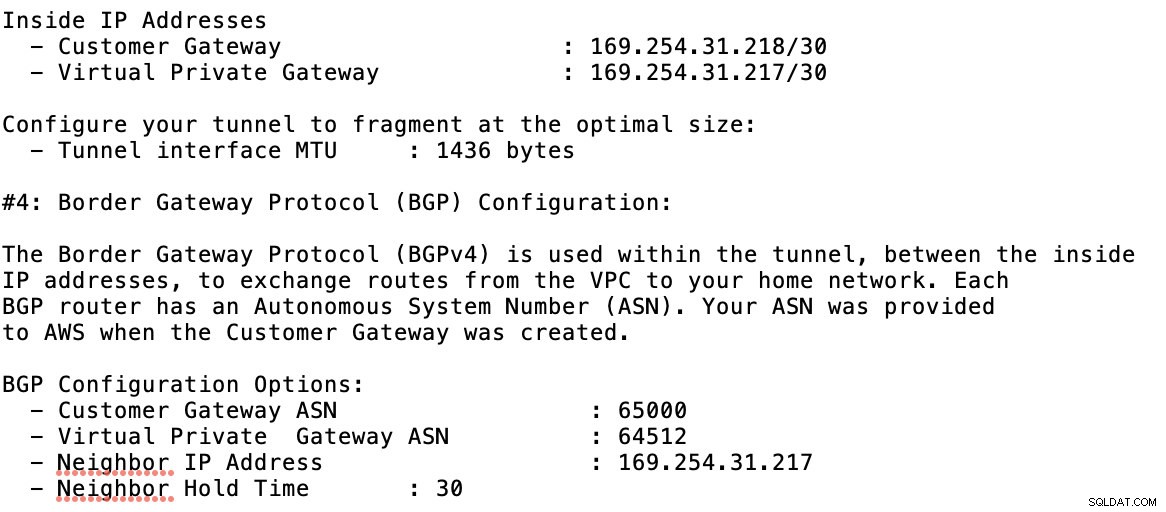
pro které to musíte při přidávání tunelu pod GCP -> Hybrid Connectivity -> VPN nastavení konektivity. Podívejte se na obrázek níže, pro který jsem vytvořil cloudový router a relaci BGP během vytváření ukázkového tunelu:
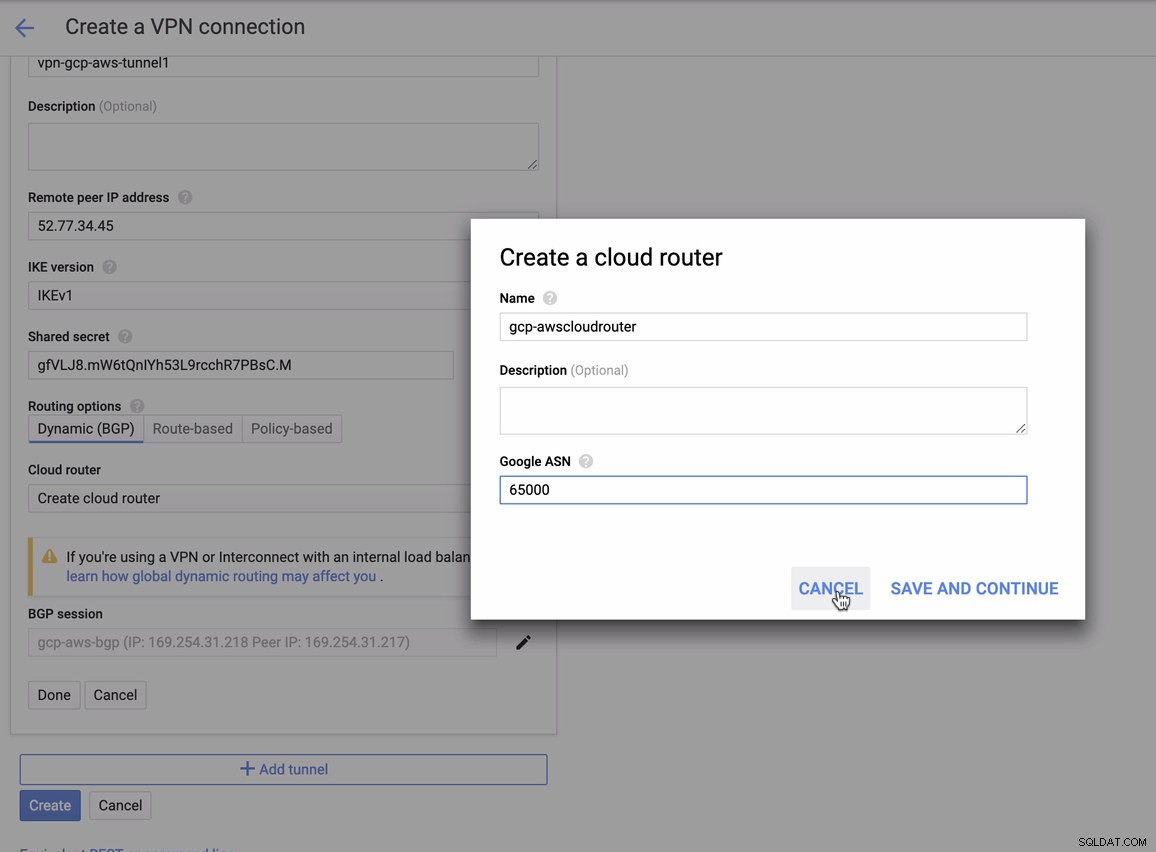
Poté relace BGP jako,

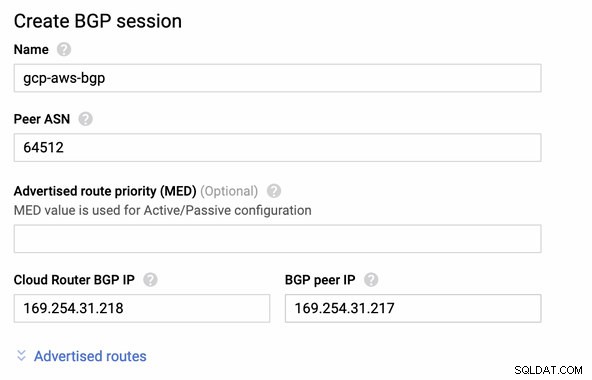
Poznámka: Stažený konfigurační soubor obsahuje konfigurační tunel IPSec, pro který AWS také obsahuje dva (2) VPN servery připravené pro vaše připojení. Musíte je nastavit oba, abyste měli vysoké dostupné nastavení. Jakmile je správně nastaveno pro oba tunely, připojení AWS VPN na kartě Tunely zobrazí, že obě Vnější IP adresa jsou nahoře. Viz obrázek níže:

-
A konečně, protože jsme vytvořili internetovou bránu a bránu NAT, naplňte veřejné a soukromé podsítě správně správným cílem a cíl jak je vidět na snímku obrazovky z předchozích kroků. To lze nastavit tak, že přejdete na Služby -> Sítě a doručování obsahu -> VPC -> Tabulky směrování a vyberte vytvořené tabulky tras uvedené v předchozích krocích. Viz obrázek níže:
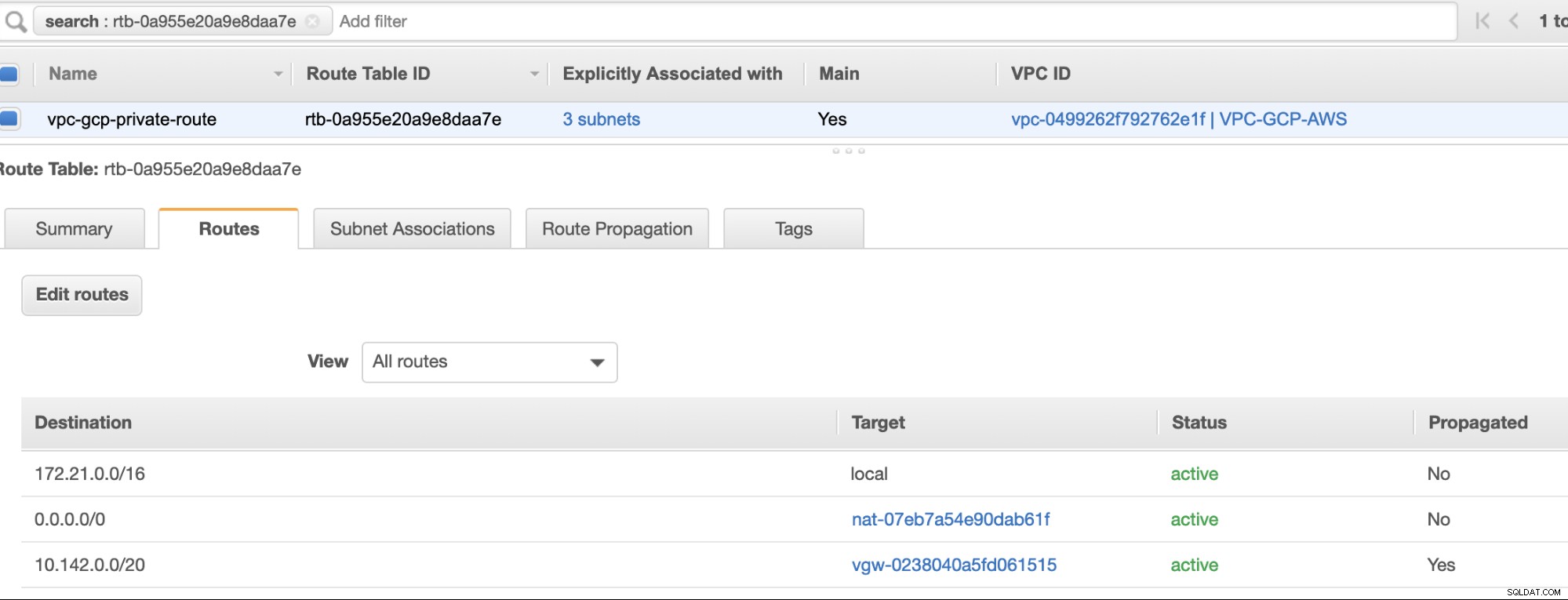
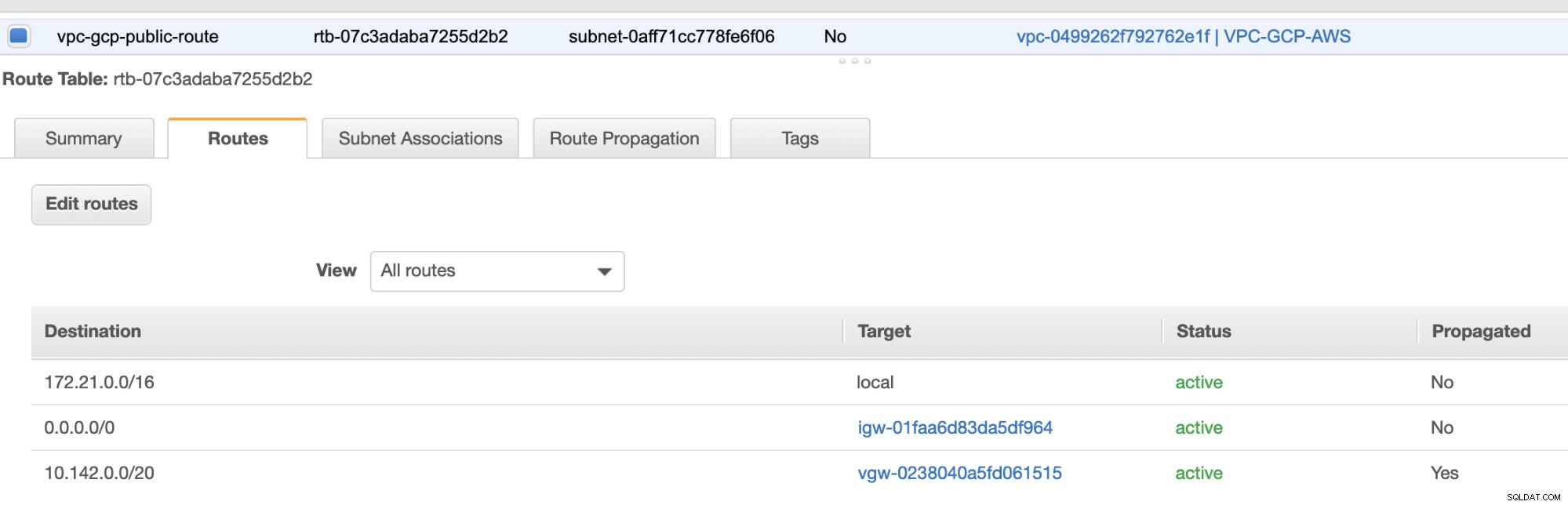
Jak jste si všimli, igw-01faa6d83da5df964 je internetová brána, kterou jsme vytvořili a je používána veřejnou cestou. Soukromá směrovací tabulka má cíl a cíl nastaven na nat-07eb7a54e90dab61f a oba mají Cíl nastavte na 0.0.0.0/0, protože to umožní různá připojení IPv4. Nezapomeňte také nastavit Propagaci trasy správně pro virtuální bránu, jak je vidět na snímku obrazovky, který má cíl vgw-0238040a5fd061515 . Stačí kliknout na Propagace trasy a nastavit ji na Ano, stejně jako na obrázku níže:
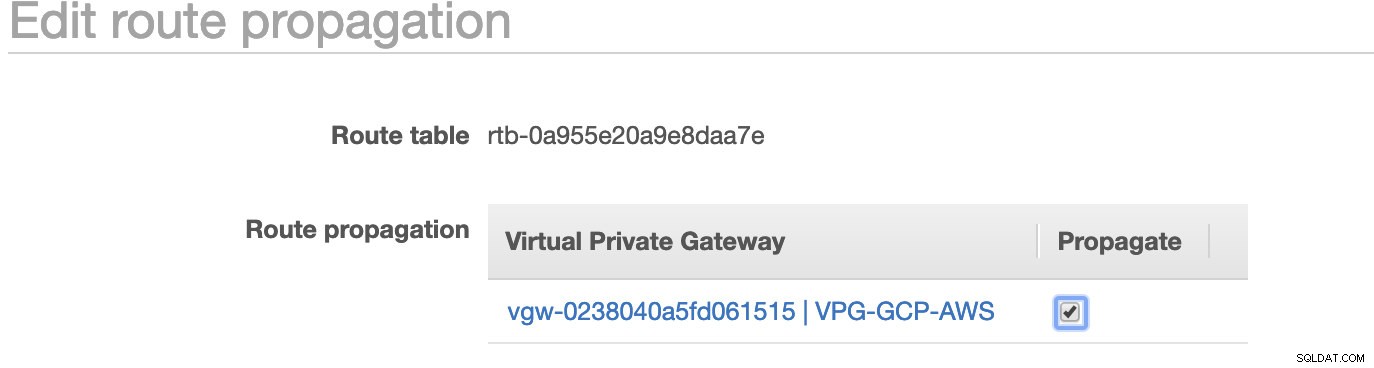
To je velmi důležité, aby spojení z externích připojení GCP bylo směrováno do směrovacích tabulek v AWS a nebyla potřeba žádná další ruční práce. Jinak váš GCP nemůže navázat spojení s AWS.
Nyní, když je naše VPN spuštěna, budeme pokračovat v nastavování našich soukromých uzlů včetně hostitele bastion.
Nastavení uzlů Compute Engine
Nastavení uzlů Compute Engine/EC2 bude rychlé a snadné, protože vše máme na svém místě. Nebudu zabíhat do těchto podrobností, ale podívejte se na níže uvedené snímky obrazovky, které vysvětlují nastavení.
AWS EC2 Uzly :

Výpočetní uzly GCP :
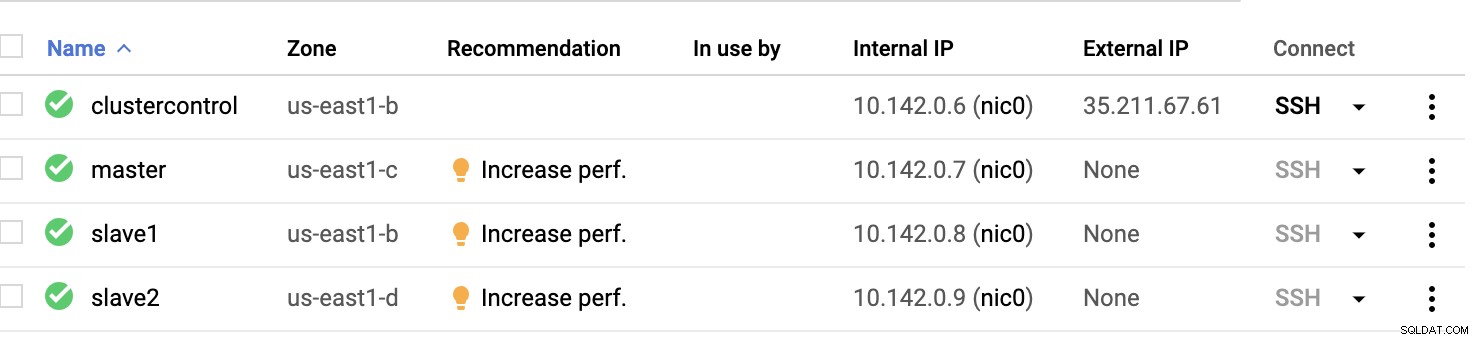
V podstatě na tomto nastavení. Hostitel clustercontrol bude hostitelem bašty nebo skoku a pro kterého bude nainstalován ClusterControl. Je zřejmé, že všechny uzly zde nejsou přístupné přes internet. Nemají přiřazenou žádnou externí IPv4 a uzly komunikují prostřednictvím velmi zabezpečeného kanálu pomocí VPN.
A konečně, všechny tyto uzly od AWS po GCP jsou nastaveny s jedním jednotným uživatelem systému s přístupem sudo, což je potřeba v naší další části. Podívejte se, jak vám ClusterControl může usnadnit život v multicloudu a více regionech.
ClusterControl k záchraně!!!
Manipulace s více uzly a na různých veřejných cloudových platformách a navíc v jiném „regionu“ může být „skutečně bolestivý a skličující“ úkol. Jak to efektivně monitorujete? ClusterControl funguje nejen jako váš švýcarský nůž, ale také jako váš virtuální DBA. Nyní se podívejme, jak vám ClusterControl může usnadnit život.
Vytvoření clusteru s více replikacemi pomocí ClusterControl
Nyní se pokusíme vytvořit replikační cluster MariaDB master-slave podle topologie "Multiple Replication".
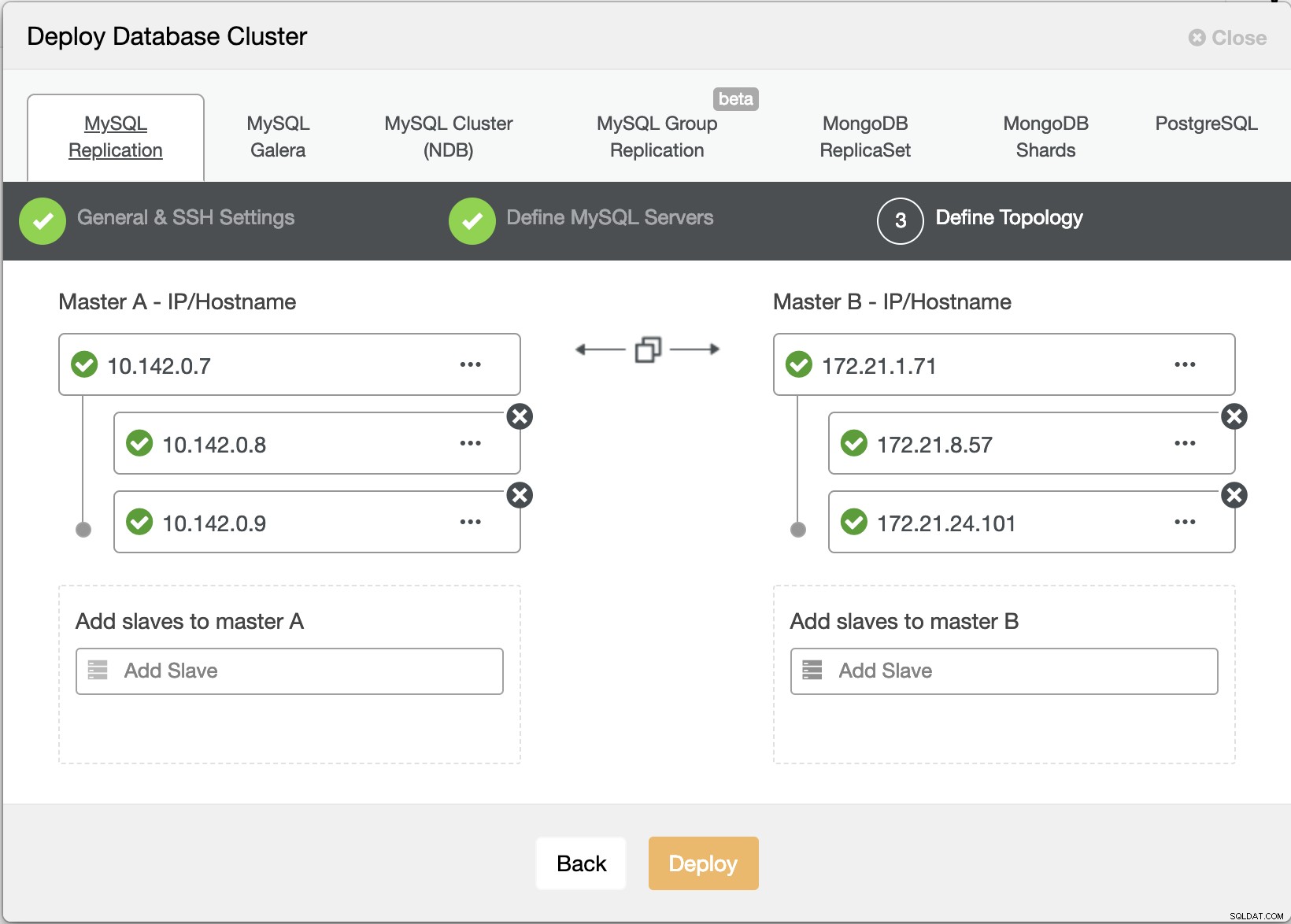 Průvodce nasazením ClusterControl
Průvodce nasazením ClusterControl Stisknutím tlačítka Nasadit tlačítko nainstaluje balíčky a podle toho nastaví uzly. Logický pohled na to, jak by topologie vypadala:
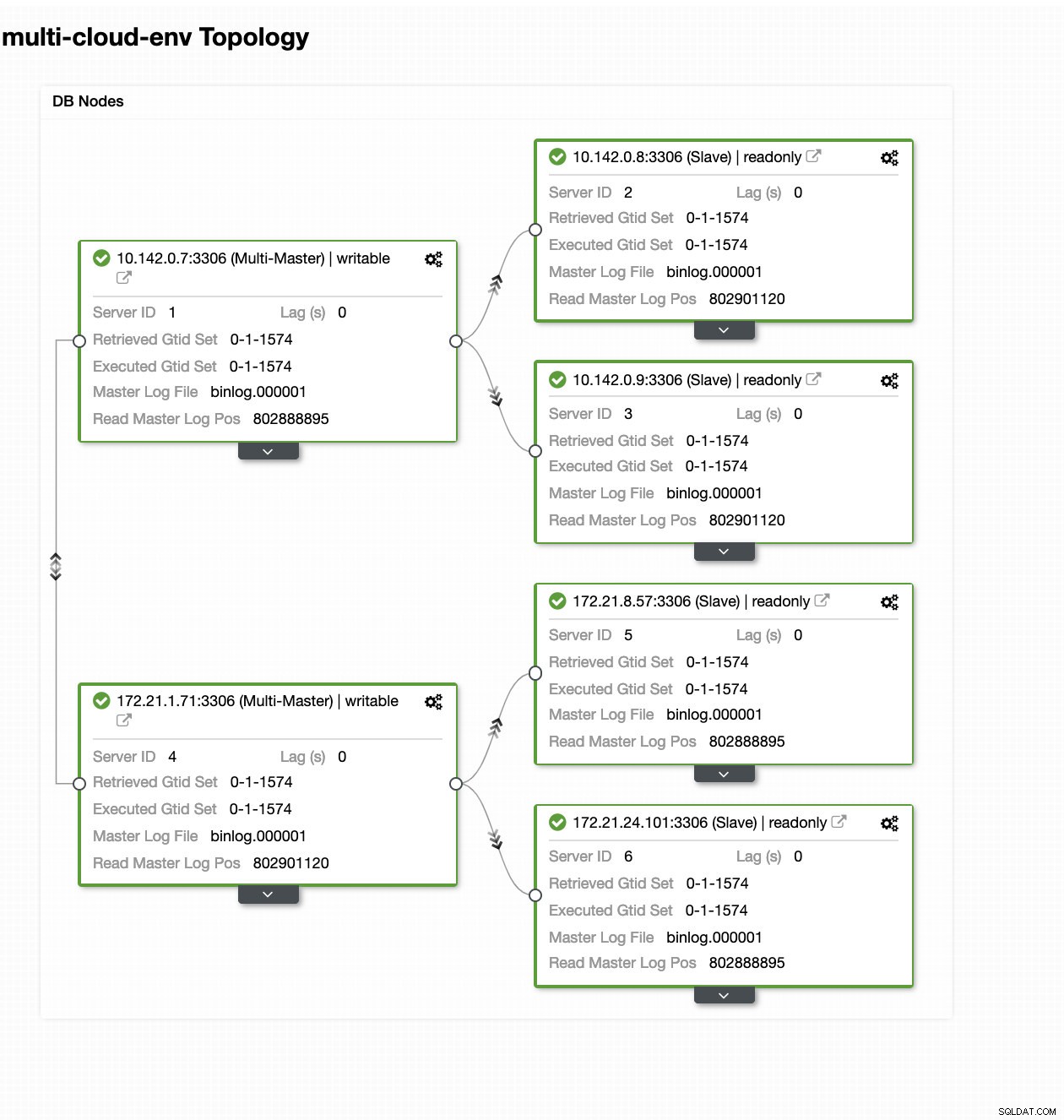 ClusterControl – zobrazení topologie
ClusterControl – zobrazení topologie IP adresy uzlů rozsahu 172.21.0.0/16 se replikují z hlavního serveru běžícího na GCP.
A teď, co kdybychom zkusili nahrát nějaké zápisy na master? Jakékoli problémy s konektivitou nebo latencí mohou způsobit zpoždění slave, budete to moci zjistit pomocí ClusterControl. Viz snímek obrazovky níže:
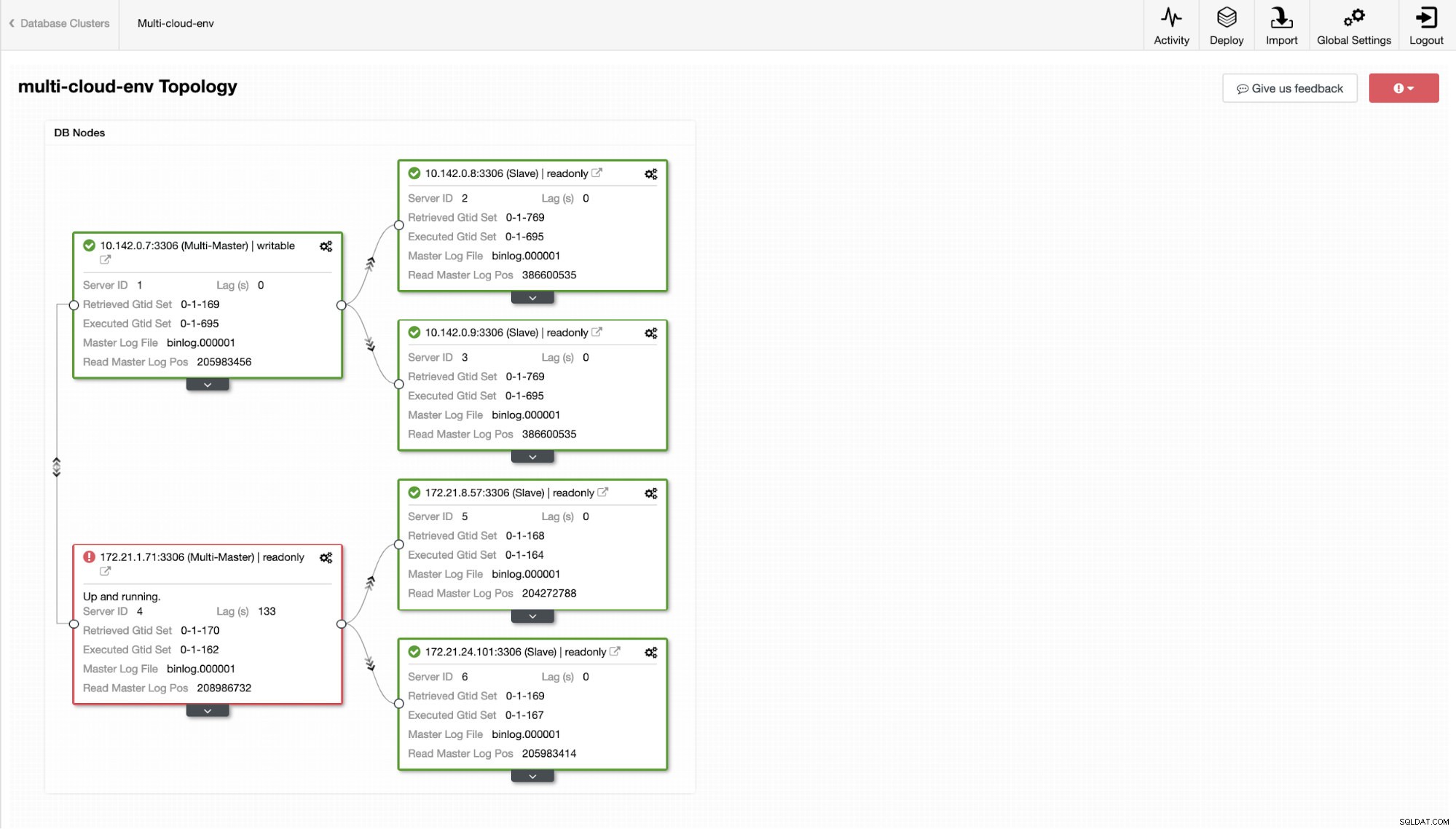
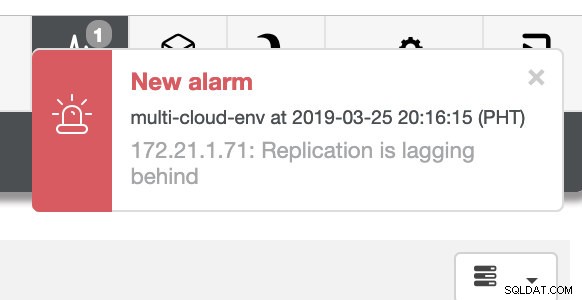
a jak vidíte v pravém horním rohu snímku obrazovky, změní se na červenou, protože znamená, že byly zjištěny problémy. Proto byl během zjištění tohoto problému odeslán poplach. Viz níže:
Musíme se v tom pohrabat. Pro podrobné monitorování jsme povolili agenty na instancích databáze. Pojďme se podívat na hlavní panel.
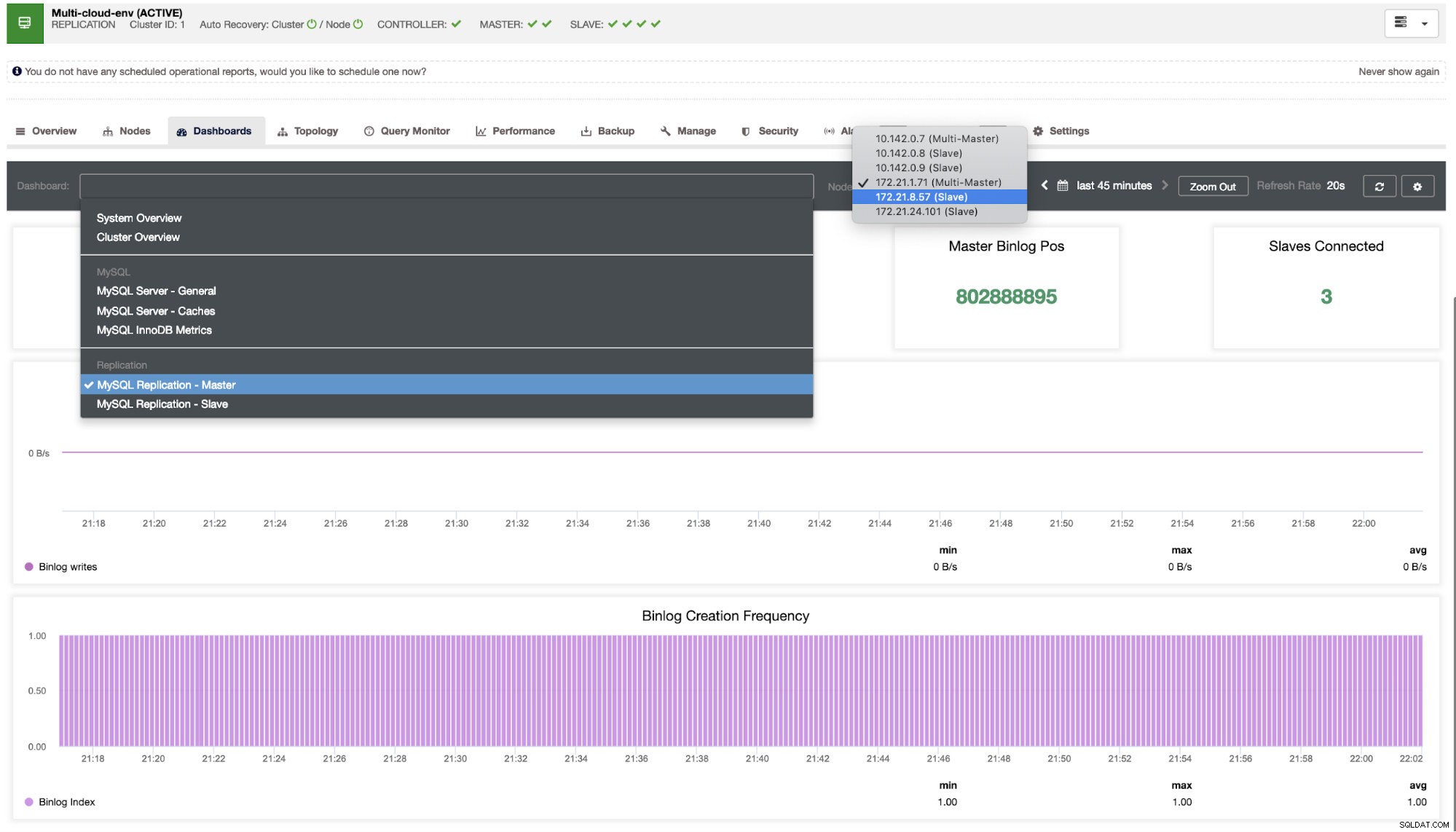
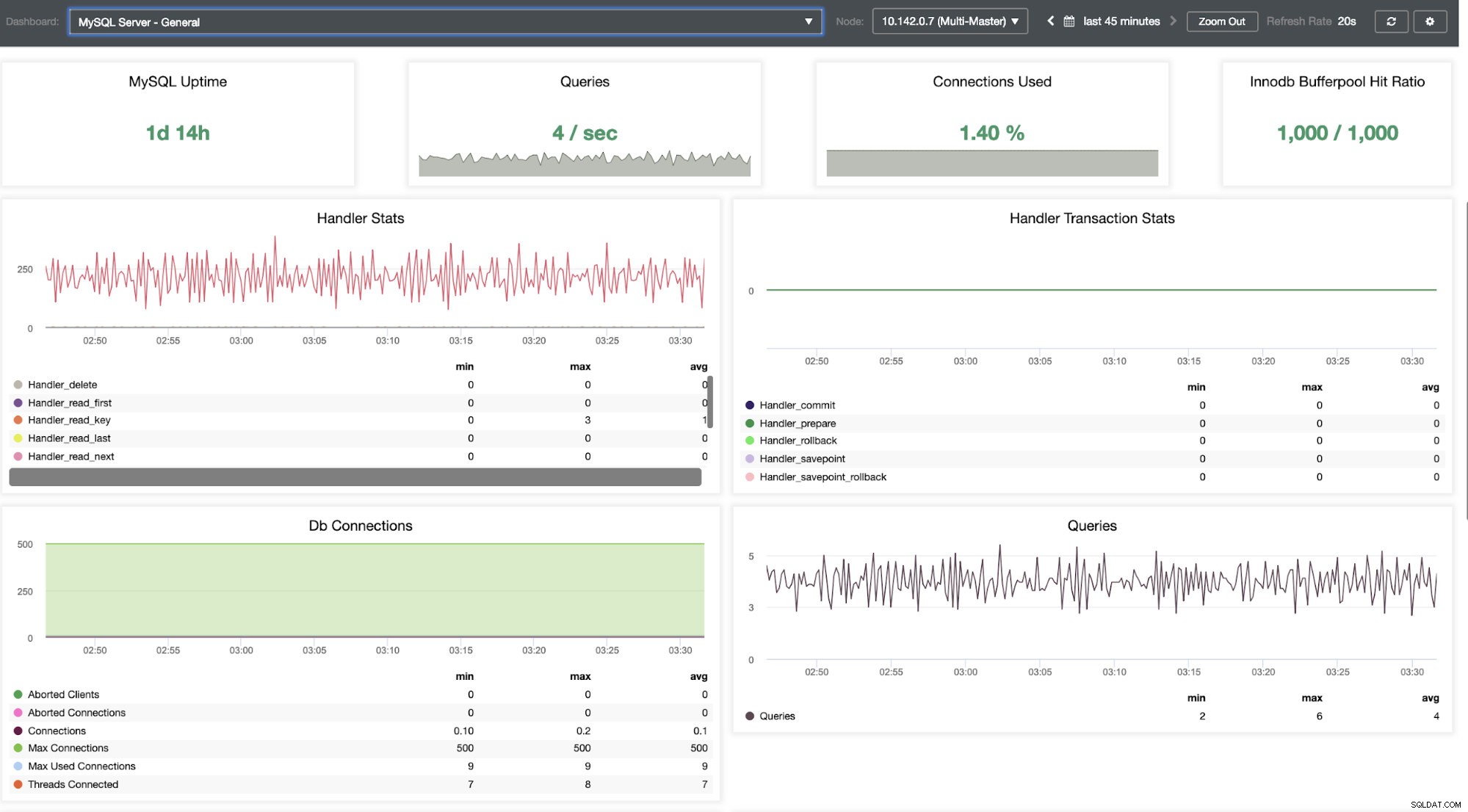
Nabízí super hladký zážitek z hlediska monitorování vašich uzlů.
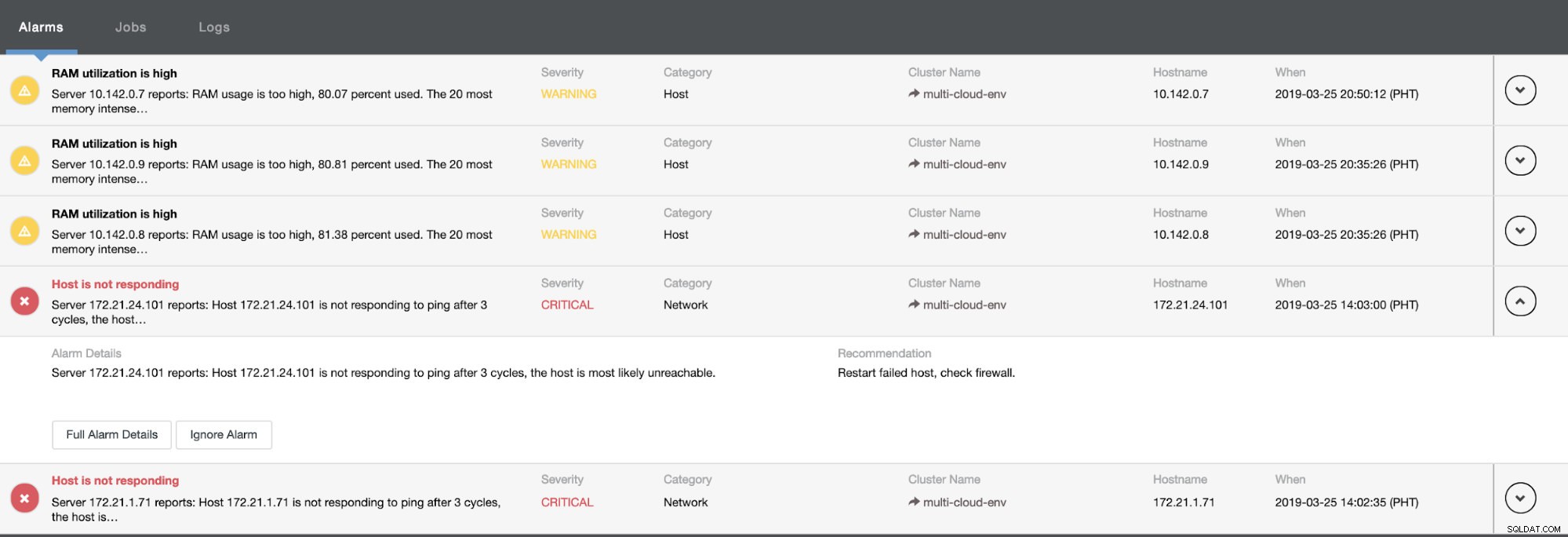
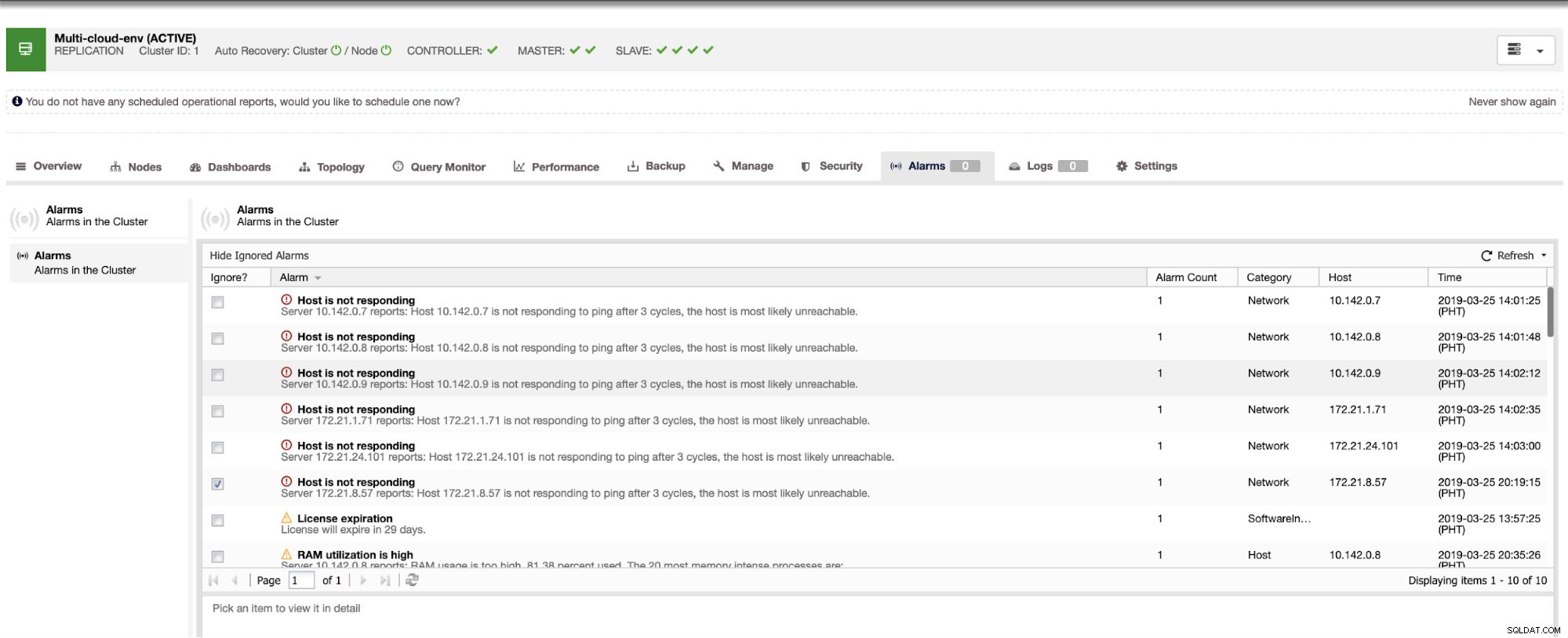
Říká nám, že využití je vysoké nebo hostitel neodpovídá. I když se jednalo pouze o pping selhání odezvy, můžete upozornění ignorovat, abyste zabránili jeho bombardování. V případě potřeby jej tedy můžete „zrušit ignorování“ přechodem do Cluster -> Alarms v Clustercontrol. Viz níže:
Správa selhání a provádění selhání
Řekněme, že hlavní uzel us-east1 selhal nebo vyžaduje zásadní opravu z důvodu upgradu systému nebo hardwaru. Řekněme, že toto je právě teď topologie (viz obrázek níže):
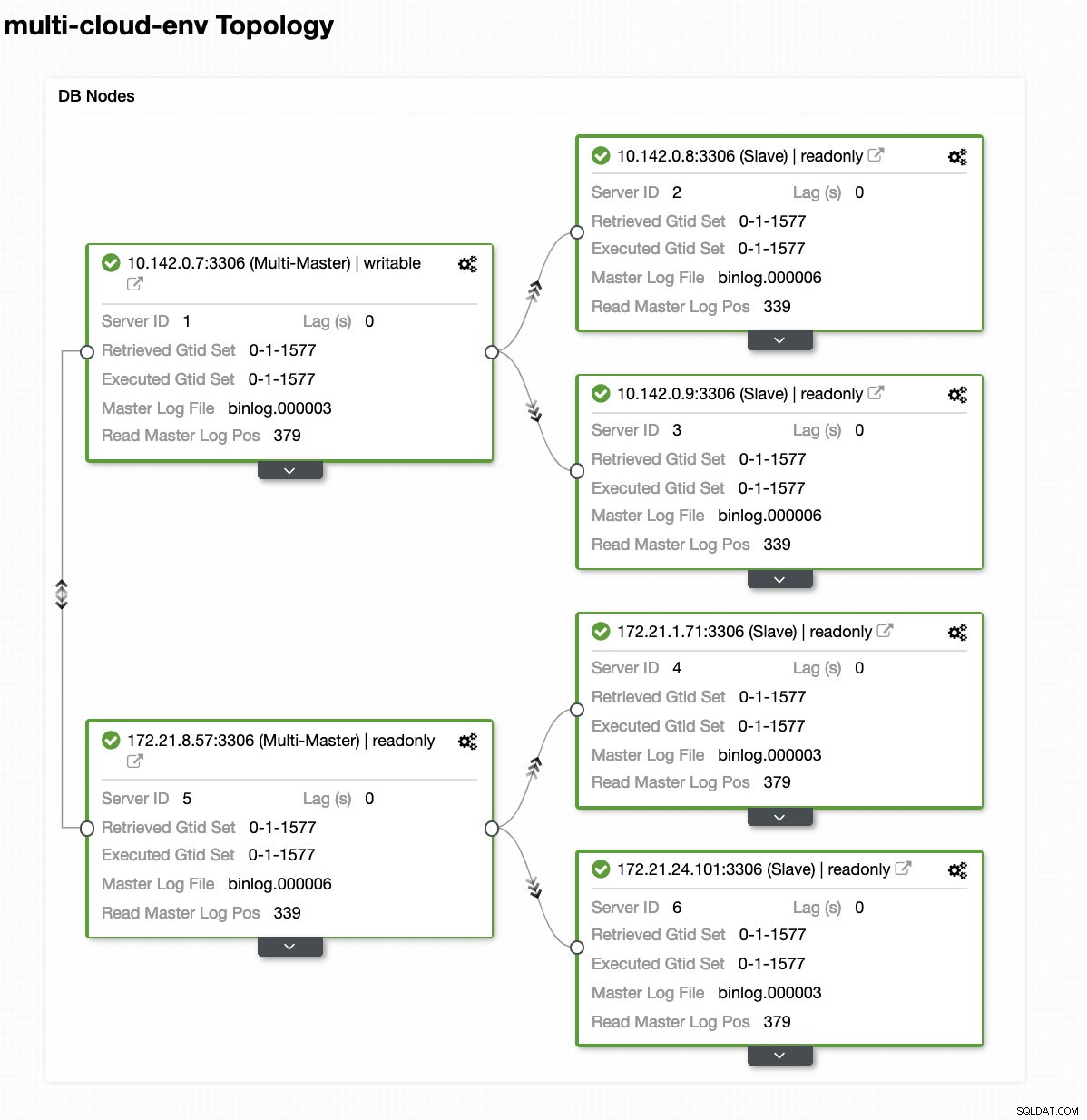
Zkusme vypnout hostitele 10.142.0.7, což je hlavní pod regionem us-východ1. Podívejte se na níže uvedené snímky obrazovky, jak na to ClusterControl reaguje:
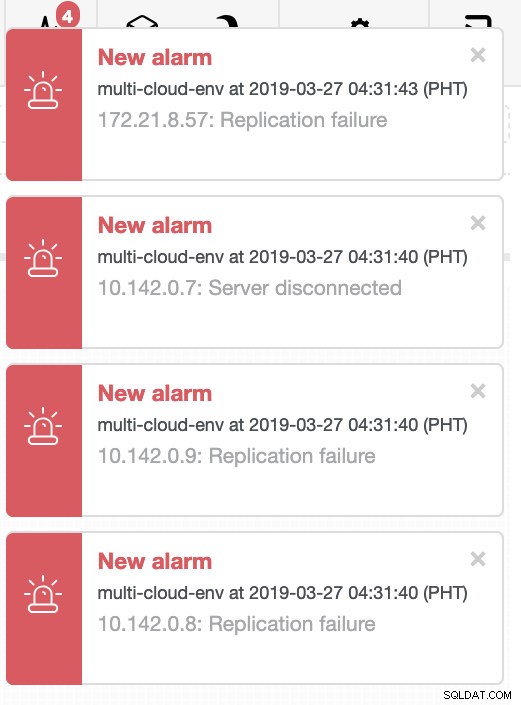
ClusterControl odesílá alarmy, jakmile detekuje anomálie v clusteru. Poté se pokusí provést převzetí služeb při selhání u nového hlavního serveru výběrem správného kandidáta (viz obrázek níže):

Poté odloží stranou neúspěšnou master, která již byla vyjmuta z clusteru (viz obrázek níže):
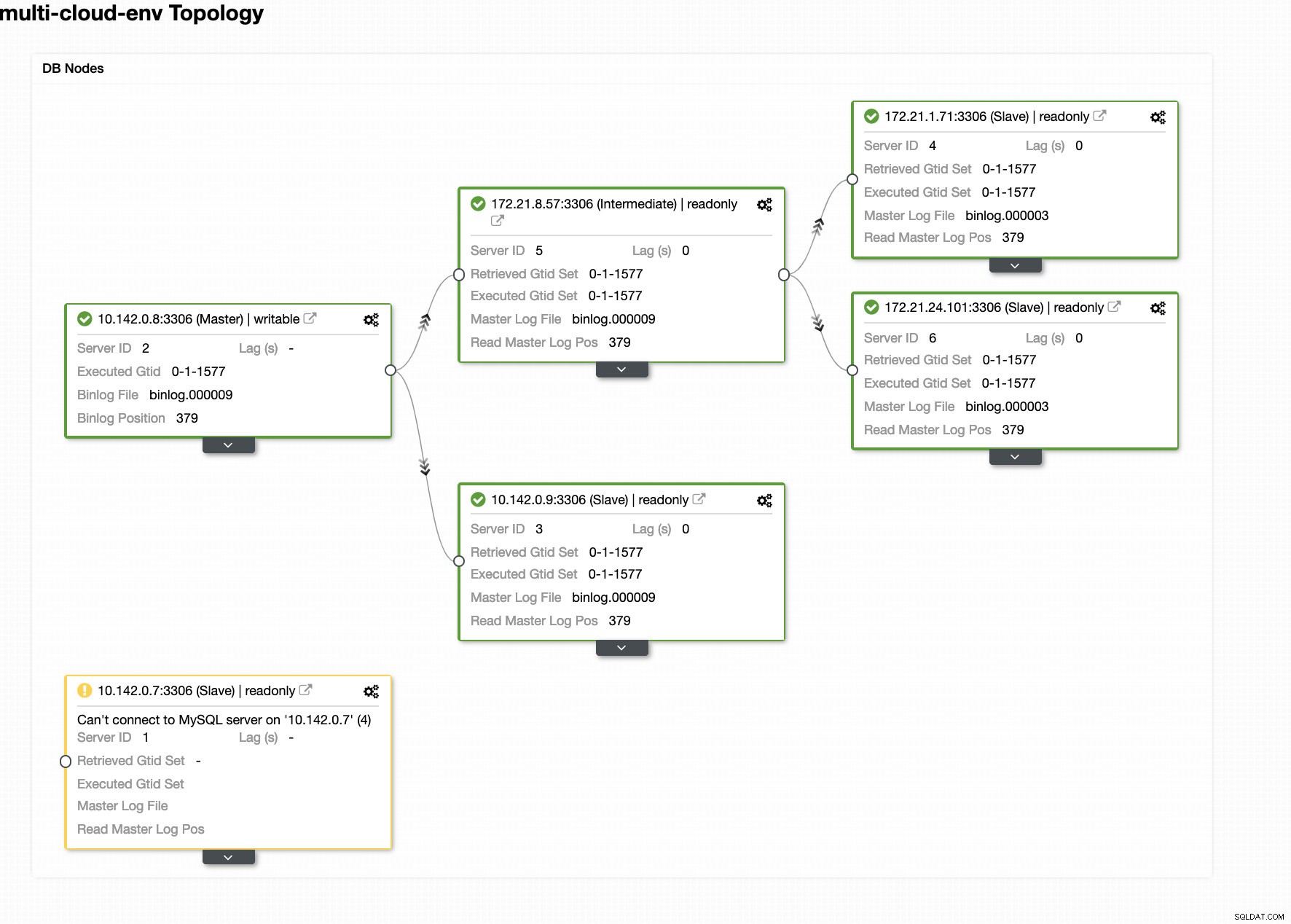
Toto je jen letmý pohled na to, co ClusterControl umí, existují další skvělé funkce, jako je zálohování, monitorování dotazů, nasazení/správa nástrojů pro vyrovnávání zatížení a mnoho dalších!
Závěr
Správa nastavení replikace MySQL v multicloudu může být složitá. Zabezpečení našeho nastavení je třeba věnovat velkou pozornost, takže doufejme, že tento blog poskytuje nápad, jak definovat podsítě a chránit uzly databáze. Po zabezpečení je potřeba spravovat řadu věcí a právě zde může být ClusterControl velmi užitečný.
Zkuste to hned a dejte nám vědět, jak to jde. Zde nás můžete kdykoli kontaktovat.