Dlouho běžící dotazy/výpisy/transakce jsou někdy v prostředí MySQL nevyhnutelné. V některých případech může být dlouhodobý dotaz katalyzátorem katastrofální události. Pokud vám na databázi záleží, optimalizace výkonu dotazů a zjišťování dlouhotrvajících dotazů musí být prováděny pravidelně. Věci se však stávají těžšími, když je zapojeno více instancí ve skupině nebo clusteru.
Když se zabýváme více uzly, musíme se vyhnout opakovaným úkolům kontroly každého jednotlivého uzlu. ClusterControl monitoruje různé aspekty vašeho databázového serveru, včetně dotazů. ClusterControl agreguje všechny informace související s dotazem ze všech uzlů ve skupině nebo clusteru a poskytuje centralizovaný pohled na pracovní zátěž. Existuje skvělý způsob, jak porozumět vašemu clusteru jako celku s minimálním úsilím.
V tomto příspěvku na blogu vám ukážeme, jak detekovat dlouhotrvající dotazy MySQL pomocí ClusterControl.
Proč dotaz trvá déle?
Nejprve musíme znát povahu dotazu, zda se očekává, že se bude jednat o dotaz s dlouhým nebo krátkým průběhem. Některé analytické a dávkové operace mají být dlouhotrvající dotazy, takže je nyní můžeme přeskočit. V závislosti na velikosti tabulky může být také úprava struktury tabulky pomocí příkazu ALTER zdlouhavou operací.
U transakce s krátkým rozsahem by měla být provedena co nejrychleji, obvykle během několika subsekund. Čím kratší, tím lepší. To přichází se sadou pravidel osvědčených postupů při dotazování, které musí uživatelé dodržovat, jako je použití správného indexování v příkazu WHERE nebo JOIN, používání správného úložiště, výběr správných datových typů, plánování dávkových operací mimo špičku, vykládání analytických /hlášení provozu do vyhrazených replik atd.
Existuje řada věcí, které mohou způsobit, že provedení dotazu bude trvat déle:
- Neefektivní dotaz – Při vyhledávání nebo připojování používejte neindexované sloupce, takže MySQL trvá déle, než se podmínce přizpůsobí.
- Zámek tabulky – Tabulka je uzamčena globálním zámkem nebo explicitním zámkem tabulky, když se k ní dotaz pokouší získat přístup.
- Zablokování – Dotaz čeká na přístup ke stejným řádkům, které jsou uzamčeny jiným dotazem.
- Datová sada se nevejde do paměti RAM – Pokud se data vaší pracovní sady vejdou do mezipaměti, budou SELECT dotazy obvykle relativně rychlé.
- Neoptimální hardwarové zdroje – Mohou to být pomalé disky, přestavba RAID, přesycená síť atd.
- Operace údržby – Spuštění mysqldump může přinést obrovské množství jinak nepoužívaných dat do fondu vyrovnávací paměti a současně (potenciálně užitečná) data, která tam již jsou, budou vyřazena a vyprázdněna na disk.
Výše uvedený seznam zdůrazňuje, že nejrůznější problémy nezpůsobuje pouze samotný dotaz. Existuje mnoho důvodů, které vyžadují podívat se na různé aspekty serveru MySQL. V některých horších případech by dlouhotrvající dotaz mohl způsobit celkové narušení služby, jako je výpadek serveru, selhání serveru a maximální výpadek připojení. Pokud uvidíte, že provedení dotazu trvá déle než obvykle, prozkoumejte jej.
Jak zkontrolovat?
SEZNAM PROCESŮ
MySQL poskytuje řadu vestavěných nástrojů pro kontrolu dlouhotrvající transakce. Za prvé, příkazy SHOW PROCESSLIST nebo SHOW FULL PROCESSLIST mohou odhalit běžící dotazy v reálném čase. Zde je snímek obrazovky funkce ClusterControl Running Queries, která je podobná příkazu SHOW FULL PROCESSLIST (ale ClusterControl agreguje celý proces do jednoho zobrazení pro všechny uzly v clusteru):
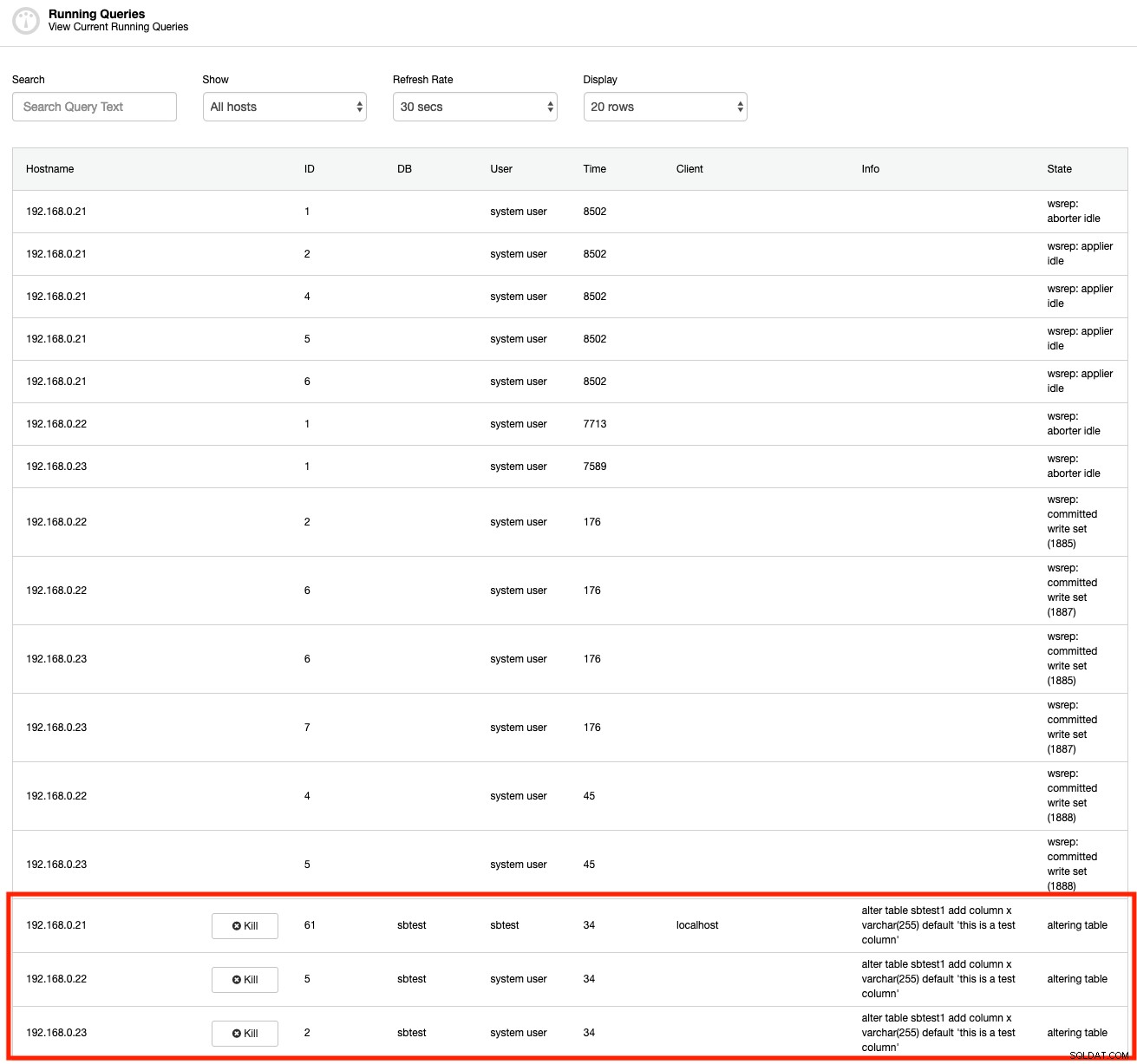
Jak vidíte, útočný dotaz můžeme okamžitě vidět hned z výstupu. Ale jak často se na ty procesy díváme? To je užitečné pouze v případě, že jste si vědomi dlouhotrvající transakce. Jinak byste to nevěděli, dokud se něco nestane – například se hromadí připojení nebo se server zpomaluje než obvykle.
Protokol pomalého dotazu
Protokol pomalých dotazů zachycuje pomalé dotazy (příkazy SQL, které trvají déle než long_query_time sekund k provedení), nebo dotazy, které nepoužívají indexy pro vyhledávání (log_queries_not_using_indexes ). Tato funkce není ve výchozím nastavení povolena a pro její aktivaci stačí nastavit následující řádky a restartovat MySQL server:
[mysqld]
slow_query_log=1
long_query_time=0.1
log_queries_not_using_indexes=1Protokol pomalých dotazů lze použít k vyhledání dotazů, jejichž provedení trvá dlouho, a proto jsou kandidáty na optimalizaci. Zkoumání dlouhého pomalého protokolu dotazů však může být časově náročný úkol. Existují nástroje pro analýzu souborů protokolu pomalých dotazů MySQL a shrnutí jejich obsahu, jako je mysqldumpslow, pt-query-digest nebo ClusterControl Top Queries.
ClusterControl Top Queries shrnuje pomalý dotaz pomocí dvou metod – protokolu pomalých dotazů MySQL nebo schématu výkonu:
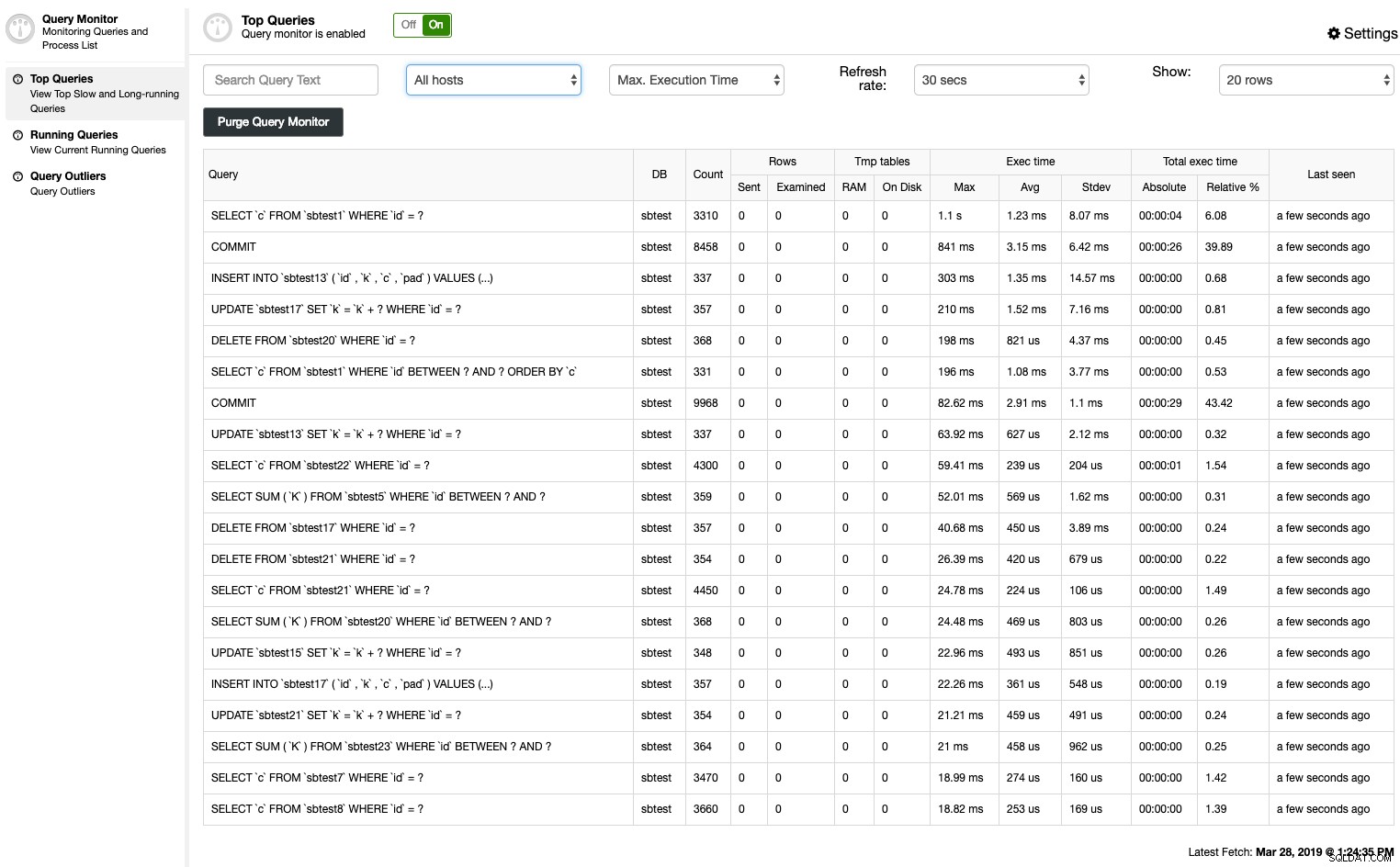
Můžete snadno zobrazit souhrn normalizovaných výpisů výpisů, seřazených na základě řady kritérií:
- Hostitel
- Výskyty
- Celková doba provedení
- Maximální doba provedení
- Průměrná doba provedení
- Doba standardní odchylky
Tuto funkci jsme velmi podrobně popsali v tomto blogovém příspěvku Jak používat ClusterControl Query Monitor pro MySQL, MariaDB a Percona Server.
Schéma výkonu
Performance Schema je skvělý nástroj dostupný pro monitorování vnitřních částí serveru MySQL a podrobností o provádění na nižší úrovni. Následující tabulky ve schématu výkonu lze použít k nalezení pomalých dotazů:
- events_statements_current
- events_statements_history
- events_statements_history_long
- events_statements_summary_by_digest
- events_statements_summary_by_user_by_event_name
- events_statements_summary_by_host_by_event_name
MySQL 5.7.7 a vyšší obsahuje schéma sys, sadu objektů, která pomáhá správcům databází a vývojářům interpretovat data shromážděná pomocí schématu výkonu do srozumitelnější podoby. Objekty sys schématu lze použít pro typické případy použití ladění a diagnostiky.
ClusterControl poskytuje poradce, což jsou miniprogramy, které můžete psát pomocí ClusterControl DSL (obdoba JavaScriptu) a rozšířit tak možnosti monitorování ClusterControl přizpůsobené vašim potřebám. Existuje řada skriptů založených na schématu výkonu, které můžete použít ke sledování výkonu dotazů, jako je čekání na vstup/výstup, doba čekání na zámek a tak dále. Například pod Manage -> Developer Studio , přejděte na s9s -> mysql -> p_s -> top_tables_by_iowait.js a klikněte na tlačítko "Zkompilovat a spustit". Měli byste vidět výstup na kartě Zprávy pro 10 nejlepších tabulek seřazených podle I/O čekání na server:
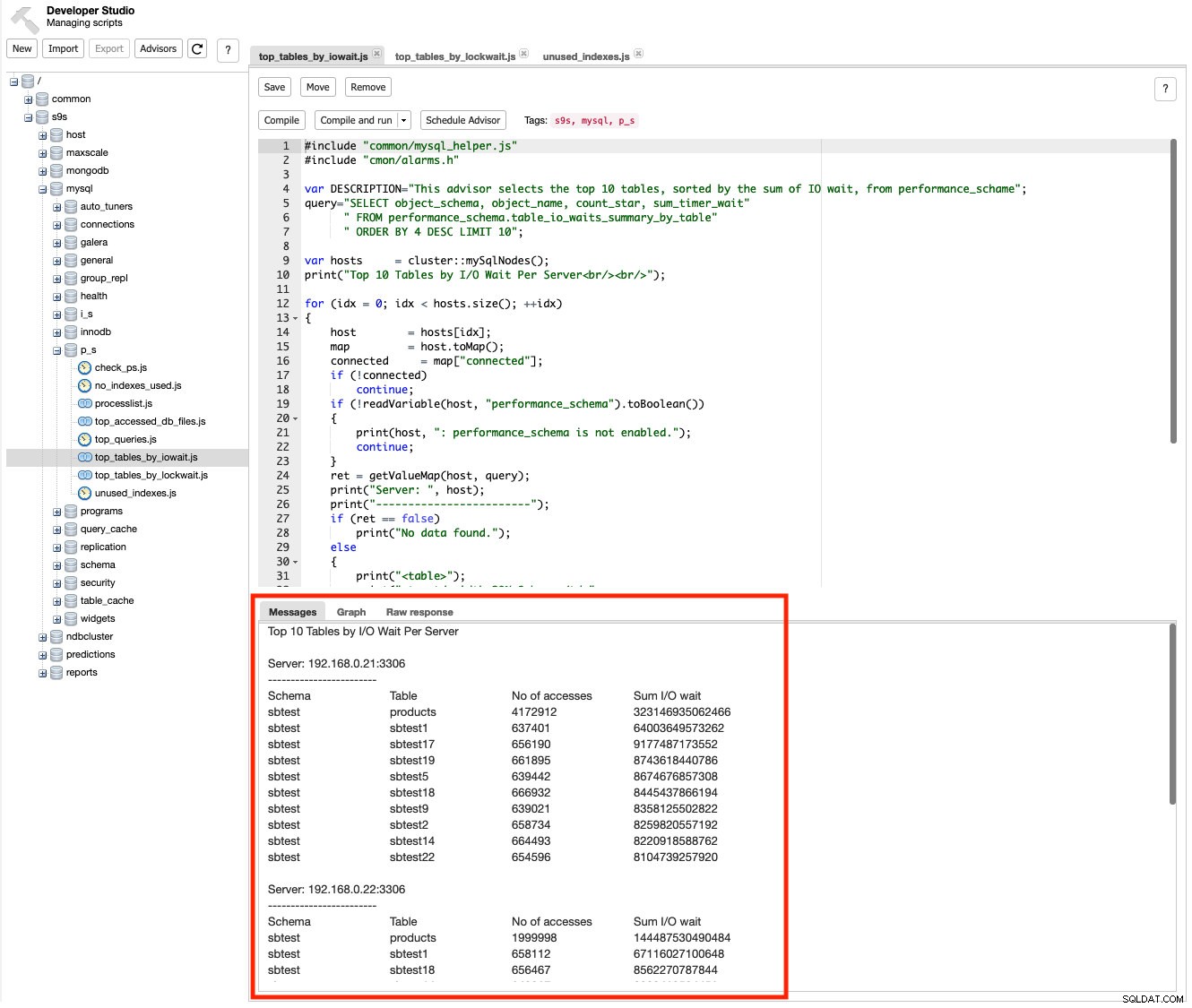
Existuje řada skriptů, které můžete použít k pochopení informací na nízké úrovni, kde a proč dochází ke zpomalení, jako top_tables_by_lockwait.js , top_accessed_db_files.js a tak dále.
ClusterControl – Detekce a upozornění na dlouho běžící dotazy
S ClusterControl získáte další výkonné funkce, které nenajdete ve standardní instalaci MySQL. ClusterControl může být nakonfigurován tak, aby proaktivně monitoroval běžící procesy a spustil poplach a zasílal upozornění uživateli, pokud je překročen práh dlouhého dotazu. To lze nakonfigurovat pomocí Konfigurace běhového prostředí v části Nastavení:
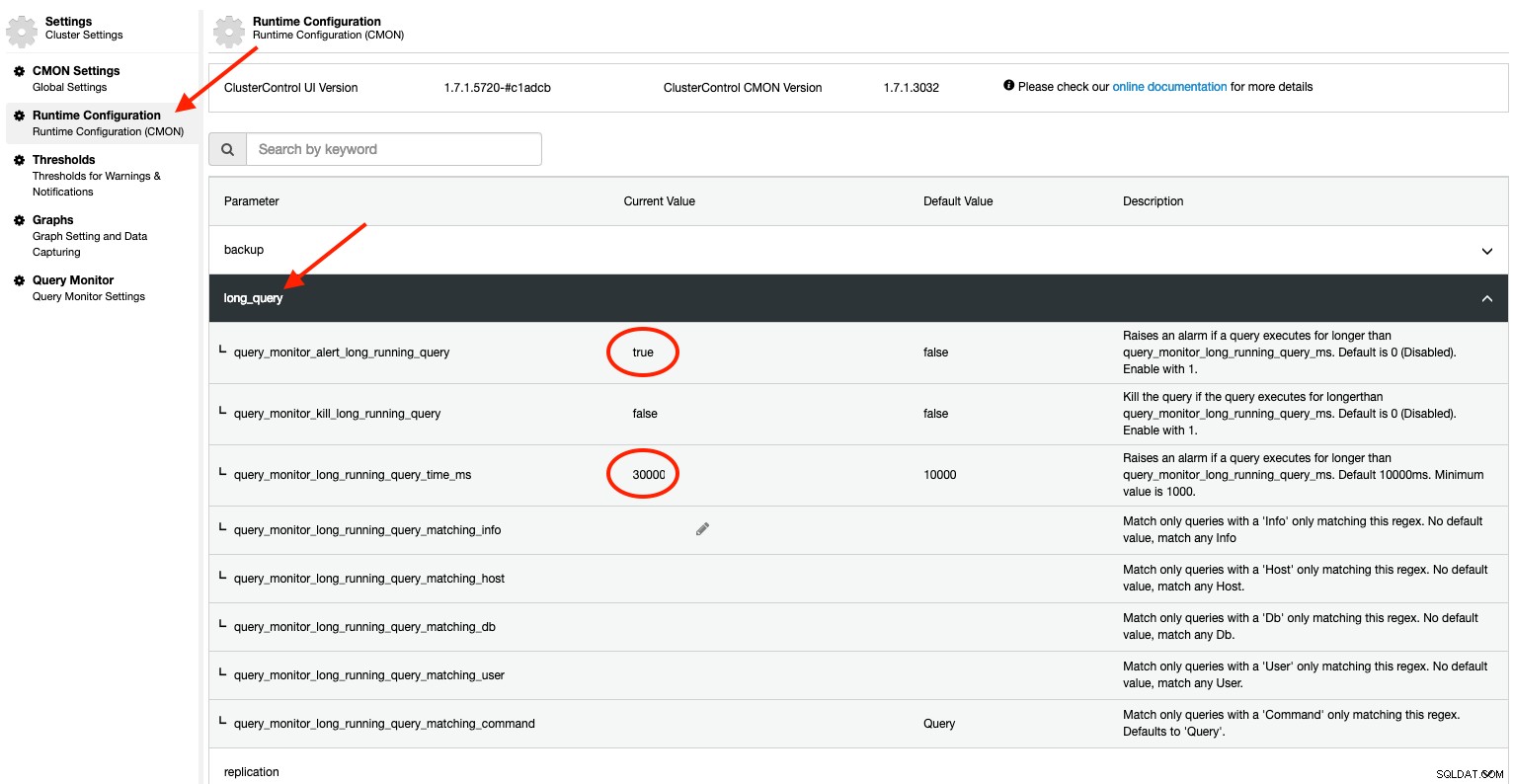
Pro verzi starší 1.7.1 výchozí hodnota pro query_monitor_alert_long_running_query je nepravdivé. Doporučujeme uživateli, aby to povolil nastavením na 1 (pravda). Aby byl trvalý, přidejte do /etc/cmon.d/cmon_X.cnf následující řádek:
query_monitor_alert_long_running_query=1
query_monitor_long_running_query_ms=30000Jakékoli změny provedené v Runtime Configuration se použijí okamžitě a není potřeba restart. Něco takového uvidíte v části Alarmy, pokud dotaz překročí prahové hodnoty 30 000 ms (30 sekund):
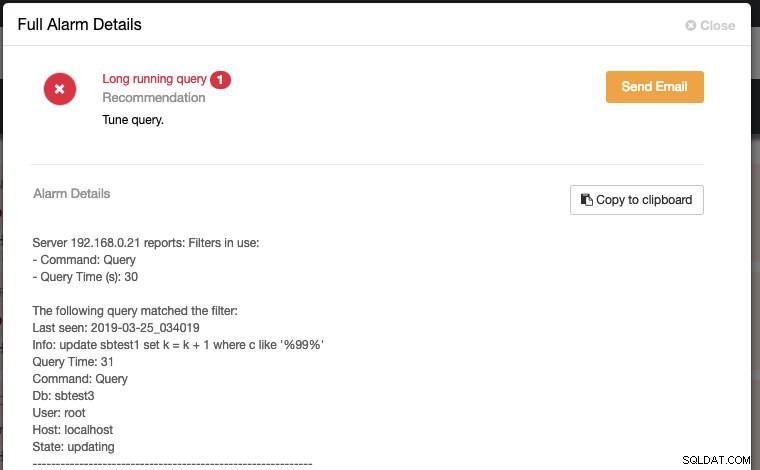
Pokud nakonfigurujete nastavení příjemce pošty jako "Doručit" pro kategorii závažnosti DbComponent plus CRITICAL (jak je znázorněno na následujícím snímku obrazovky):
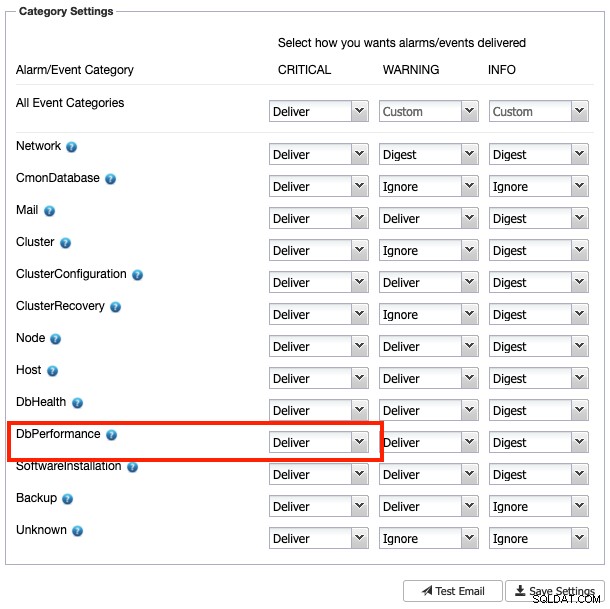
Kopii tohoto alarmu byste měli obdržet ve svém e-mailu. V opačném případě jej lze přeposlat ručně kliknutím na tlačítko „Odeslat e-mail“.
Kromě toho můžete odfiltrovat jakýkoli druh zdrojů seznamu procesů, které odpovídají určitým kritériím s regulárním výrazem (regulární výraz). Pokud například chcete, aby ClusterControl detekoval dlouho běžící dotaz pro tři uživatele MySQL s názvem 'sbtest', 'myshop' a 'db_user1', mělo by to fungovat následovně:
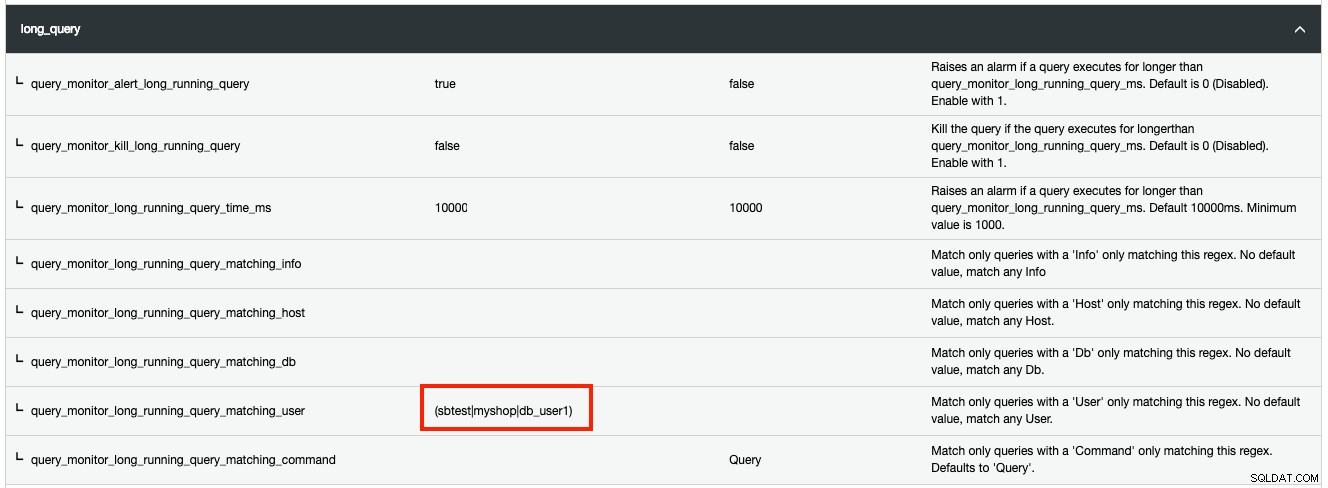
Jakékoli změny provedené v Runtime Configuration se použijí okamžitě a není třeba restartovat.
Kromě toho ClusterControl vypíše všechny transakce uváznutí spolu se stavem InnoDB, když k němu došlo, pod Výkon -> Protokol transakcí :
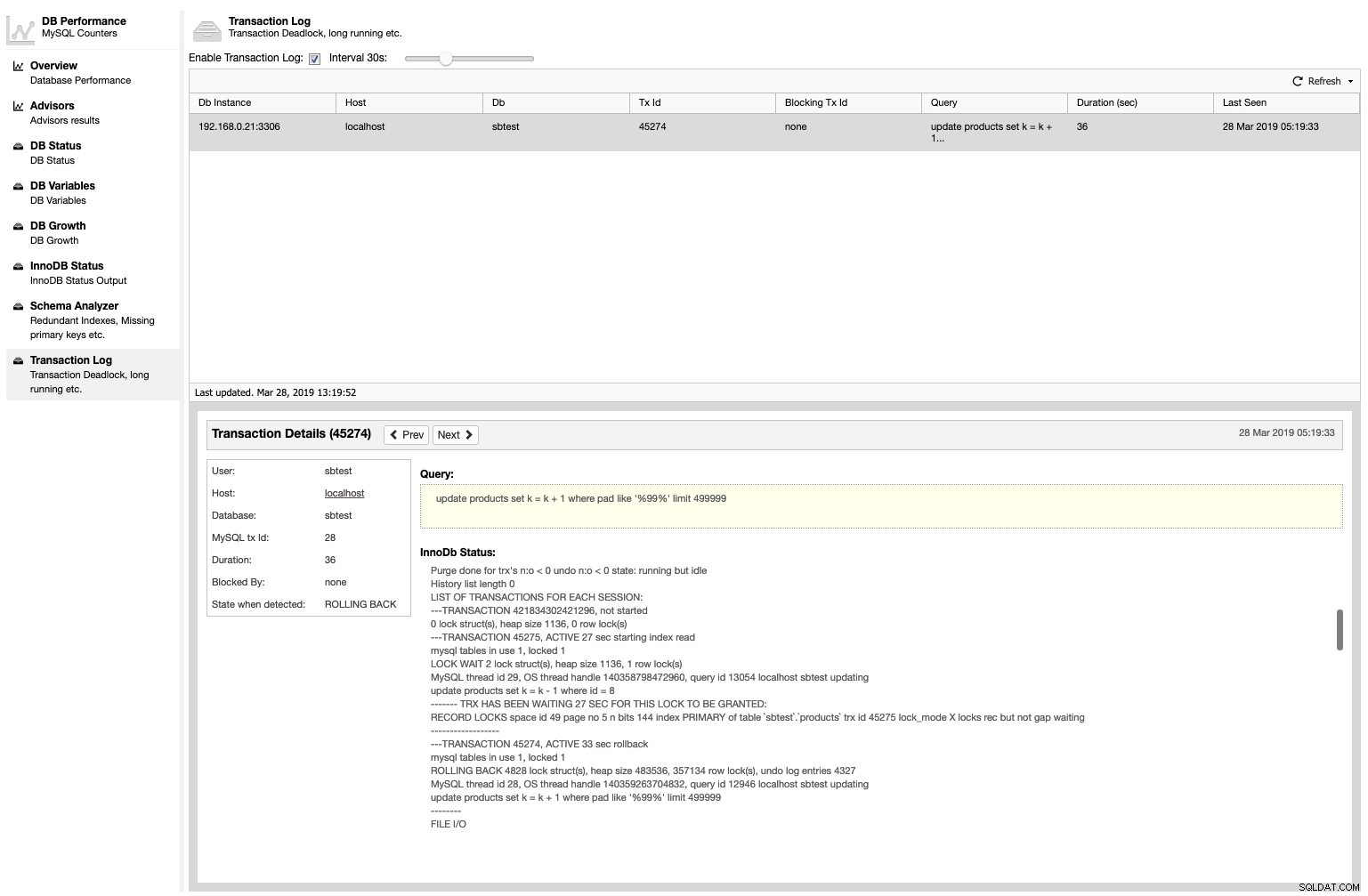
Tato funkce není ve výchozím nastavení povolena, protože detekce uváznutí ovlivní využití procesoru v uzlech databáze. Chcete-li jej povolit, jednoduše zaškrtněte políčko „Povolit protokol transakcí“ a zadejte požadovaný interval. Aby byla trvalá, přidejte proměnnou s hodnotou v sekundách do /etc/cmon.d/cmon_X.cnf:
db_deadlock_check_interval=30Podobně, pokud chcete zkontrolovat stav InnoDB, jednoduše přejděte na Výkon -> Stav InnoDB a z rozevírací nabídky vyberte server MySQL. Například:
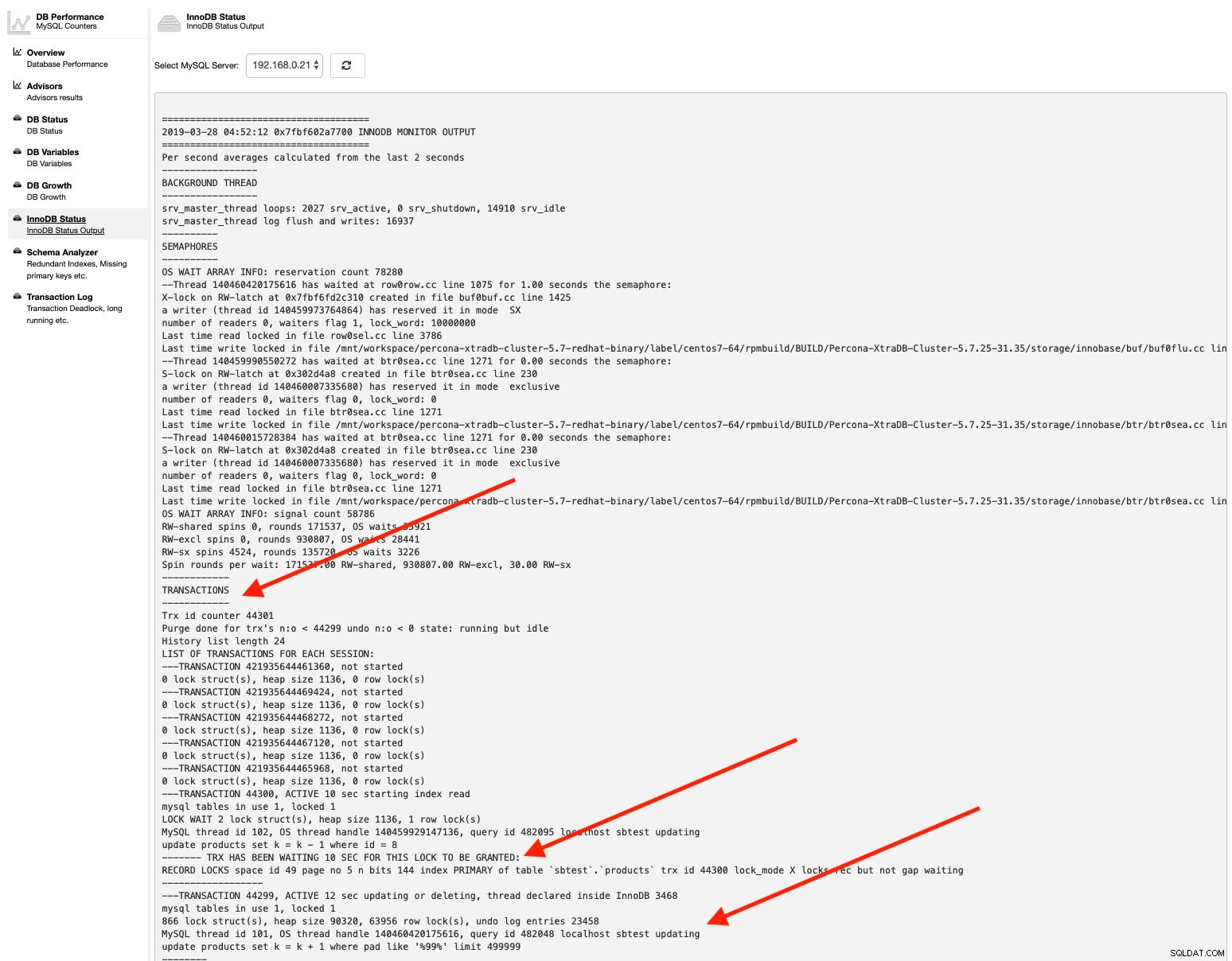
Tady to je – všechny požadované informace lze snadno získat několika kliknutími.
Shrnutí
Dlouho běžící transakce by mohly vést ke snížení výkonu, výpadku serveru, maximálnímu výpadku připojení a uváznutí. S ClusterControl můžete detekovat dlouho běžící dotazy přímo z uživatelského rozhraní, aniž byste museli zkoumat každý jednotlivý uzel MySQL v clusteru.