Vysoká dostupnost je vysoké procento času, po který systém funguje a reaguje podle potřeb podniku. Pro produkční databázové systémy je obvykle nejvyšší prioritou udržet ji blízko 100 %. Vytváříme databázové clustery, abychom eliminovali všechny jednotlivé body selhání. Pokud se instance stane nedostupnou, jiný uzel by měl být schopen převzít pracovní zátěž a pokračovat odtud. V dokonalém světě by databázový cluster vyřešil všechny problémy s dostupností našeho systému. Bohužel, i když na papíře může vše vypadat dobře, realita je často jiná. Kde se tedy může pokazit?
Transakční databázové systémy jsou dodávány se sofistikovanými úložnými systémy. Udržování konzistentních dat ve více uzlech tento úkol značně ztěžuje. Clustering zavádí řadu nových proměnných, které velmi závisí na síti a základní infrastruktuře. Není neobvyklé, že samostatná instance databáze, která běžela bez problémů na jediném uzlu, náhle funguje špatně v prostředí klastru.
Mezi řadou věcí, které mohou ovlivnit dostupnost clusteru, hrají zásadní roli problémy s latencí. Jaká je však latence? Týká se to pouze sítě?
Termín „latence“ ve skutečnosti odkazuje na několik druhů zpoždění, ke kterým dochází při zpracování údajů. Jde o to, jak dlouho trvá, než se informace přesune z fáze do druhé.
V tomto příspěvku na blogu se podíváme na dvě hlavní řešení vysoké dostupnosti pro MySQL a MariaDB a na to, jak je mohou ovlivnit problémy s latencí.
Na konci článku se podíváme na moderní nástroje pro vyrovnávání zatížení a diskutujeme o tom, jak vám mohou pomoci vyřešit některé typy problémů s latencí.
V předchozím článku můj kolega Krzysztof Książek psal o „Řešení s nespolehlivými sítěmi při vytváření řešení HA pro MySQL nebo MariaDB“. Najdete zde tipy, které vám mohou pomoci navrhnout vaši produkční architekturu HA a vyhnout se některým zde popsaným problémům.
Replikace Master-Slave pro vysokou dostupnost.
MySQL replikace master-slave je pravděpodobně nejoblíbenějším typem databázového clusteru na planetě. Jednou z hlavních věcí, kterou chcete sledovat při spuštění replikačního clusteru master-slave, je zpoždění podřízeného serveru. V závislosti na požadavcích vaší aplikace a způsobu, jakým využíváte databázi, může latence replikace (slave lag) určovat, zda lze data číst z podřízeného uzlu nebo ne. Data přijatá na master, ale ještě nedostupná na asynchronním slave znamenají, že slave má starší stav. Když není v pořádku číst z podřízeného zařízení, budete muset přejít na master, což může ovlivnit výkon aplikace. V nejhorším případě váš systém nebude schopen zvládnout veškerou zátěž na masteru.
Prodleva a zastaralá data slave
Chcete-li zkontrolovat stav replikace master-slave, měli byste začít následujícím příkazem:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)Pomocí výše uvedených informací můžete určit, jak dobrá je celková latence replikace. Čím nižší hodnotu vidíte v "Seconds_Behind_Master", tím vyšší je rychlost přenosu dat pro replikaci.
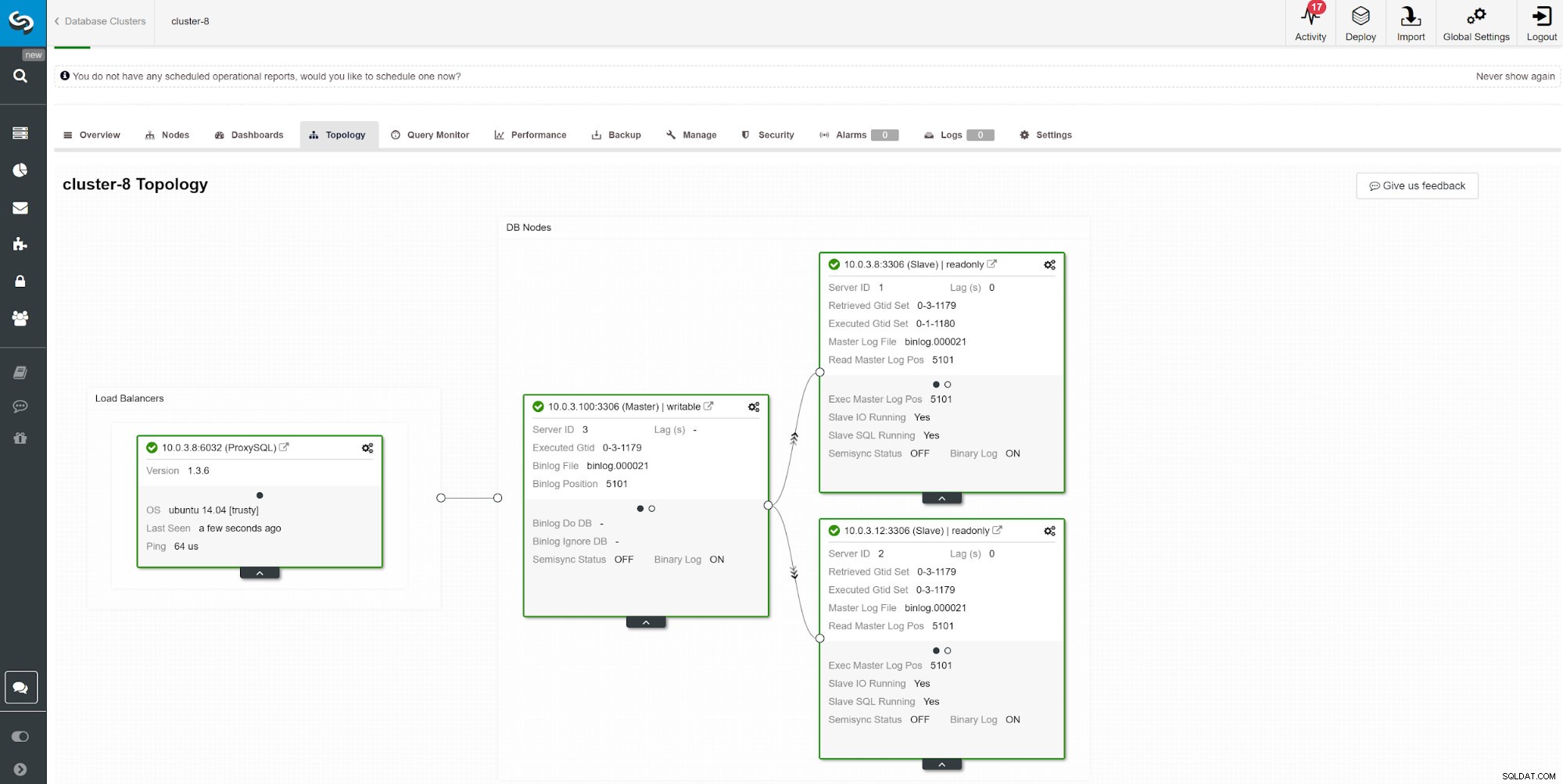 Dalším způsobem, jak monitorovat zpoždění slave, je použití monitorování replikace ClusterControl. Na tomto snímku obrazovky můžeme vidět stav replikace asymchoronního Master-Slave (2x) Clusteru s ProxySQL.
Dalším způsobem, jak monitorovat zpoždění slave, je použití monitorování replikace ClusterControl. Na tomto snímku obrazovky můžeme vidět stav replikace asymchoronního Master-Slave (2x) Clusteru s ProxySQL. Existuje řada věcí, které mohou ovlivnit dobu replikace. Nejviditelnější je propustnost sítě a množství dat, které můžete přenést. MySQL přichází s více možnostmi konfigurace pro optimalizaci procesu replikace. Základní parametry související s replikací jsou:
- Paralelní použití
- Algoritmus logických hodin
- Komprese
- Selektivní replikace master-slave
- Režim replikace
Paralelní použití
Není neobvyklé zahájit ladění replikace povolením paralelního procesu. Důvodem je ve výchozím nastavení MySQL se sekvenčním binárním logem a typický databázový server je dodáván s několika CPU, které lze použít.
Aby bylo možné obejít použití sekvenčního protokolu, nabízí MariaDB i MySQL paralelní replikaci. Implementace se může lišit podle dodavatele a verze. Např. MySQL 5.6 nabízí paralelní replikaci, pokud schéma odděluje dotazy, zatímco MariaDB (od verze 10.0) a MySQL 5.7 zvládnou paralelní replikaci napříč schématy. Různí dodavatelé a verze přicházejí se svými omezeními a funkcemi, takže vždy zkontrolujte dokumentaci.
Provádění dotazů prostřednictvím paralelních podřízených vláken může urychlit váš replikační proud, pokud máte náročný zápis. Pokud však nejste, bylo by nejlepší držet se tradiční jednovláknové replikace. Chcete-li povolit paralelní zpracování, změňte slave_parallel_workers na počet vláken CPU, která chcete do procesu zapojit. Doporučuje se ponechat hodnotu nižší než počet dostupných vláken CPU.
Paralelní replikace funguje nejlépe se skupinovými potvrzeními. Chcete-li zkontrolovat, zda dochází ke skupinovým potvrzením, spusťte následující dotaz.
show global status like 'binlog_%commits';Čím větší je poměr mezi těmito dvěma hodnotami, tím lépe.
Logické hodiny
Slave_parallel_type=LOGICAL_CLOCK je implementací Lamportova hodinového algoritmu. Při použití vícevláknového slave zařízení tato proměnná určuje metodu použitou k rozhodování o tom, které transakce se mohou na slave zařízení provádět paralelně. Proměnná nemá žádný vliv na podřízené jednotky, pro které není povoleno vícevláknové zpracování, takže se ujistěte, že je parametr slave_parallel_workers nastaven na hodnotu vyšší než 0.
Uživatelé MariaDB by také měli zkontrolovat optimistický režim představený ve verzi 10.1.3, protože vám také může poskytnout lepší výsledky.
GTID
MariaDB přichází s vlastní implementací GTID. Sekvence MariaDB se skládá z domény, serveru a transakce. Domény umožňují replikaci z více zdrojů s odlišným ID. K replikaci části dat mimo pořadí (paralelně) lze použít různá ID domén. Pokud je to pro vaši aplikaci v pořádku, může to snížit latenci replikace.
Podobná technika platí pro MySQL 5.7, která může také používat vícezdrojové hlavní a nezávislé replikační kanály.
Komprese
Výkon procesoru je postupem času stále levnější, takže jeho použití pro kompresi binlog by mohlo být dobrou volbou pro mnoho databázových prostředí. Parametr slave_compressed_protocol říká MySQL, aby použila kompresi, pokud ji podporuje master i slave. Ve výchozím nastavení je tento parametr zakázán.
Počínaje MariaDB 10.2.3 lze vybrané události v binárním protokolu volitelně komprimovat, aby se ušetřily síťové přenosy.
Formáty replikace
MySQL nabízí několik režimů replikace. Výběr správného formátu replikace pomáhá minimalizovat čas předávání dat mezi uzly clusteru.
Multimaster replikace pro vysokou dostupnost
Některé aplikace si nemohou dovolit pracovat se zastaralými daty.
V takových případech můžete chtít vynutit konzistenci napříč uzly pomocí synchronní replikace. Udržování synchronních dat vyžaduje další plugin a pro některé je nejlepším řešením na trhu Galera Cluster.
Cluster Galera přichází s wsrep API, které je zodpovědné za přenos transakcí do všech uzlů a jejich provádění podle uspořádání v celém clusteru. To zablokuje provádění následných dotazů, dokud uzel nepoužije všechny sady zápisu ze své aplikační fronty. I když je to dobré řešení pro konzistenci, můžete narazit na některá architektonická omezení. Běžné problémy s latencí mohou souviset s:
- Nejpomalejší uzel v clusteru
- Horizontální škálování a operace zápisu
- Geolokované shluky
- Vysoký ping
- Velikost transakce
Nejpomalejší uzel v clusteru
Podle návrhu nemůže být výkon zápisu clusteru vyšší než výkon nejpomalejšího uzlu v clusteru. Začněte kontrolu clusteru kontrolou prostředků počítače a ověřením konfiguračních souborů, abyste se ujistili, že všechny běží se stejným nastavením výkonu.
Paralelizace
Paralelní vlákna nezaručují lepší výkon, ale mohou urychlit synchronizaci nových uzlů s clusterem. Stav wsrep_cert_deps_distance nám říká možný stupeň paralelizace. Je to hodnota průměrné vzdálenosti mezi nejvyšší a nejnižší hodnotou seqno, kterou lze případně aplikovat paralelně. Pro určení maximálního možného počtu podřízených vláken můžete použít stavovou proměnnou wsrep_cert_deps_distance.
Horizontální měřítko
Přidáním více uzlů do clusteru máme méně bodů, které by mohly selhat; informace však musí projít více instancemi, dokud nejsou potvrzeny, což znásobuje dobu odezvy. Pokud potřebujete škálovatelné zápisy, zvažte architekturu založenou na shardingu. Dobrým řešením může být úložiště Spider.
V některých případech, chcete-li omezit informace sdílené mezi uzly clusteru, můžete zvážit použití jednoho zapisovače najednou. Při použití nástroje pro vyrovnávání zatížení je poměrně snadné jej implementovat. Když to uděláte ručně, ujistěte se, že máte postup pro změnu hodnoty DNS, když váš zapisovací uzel selže.
Geolokované shluky
Přestože je Galera Cluster synchronní, je možné nasadit Galera Cluster napříč datovými centry. Synchronní replikace jako MySQL Cluster (NDB) implementuje dvoufázový odevzdání, kde jsou zprávy odesílány všem uzlům v clusteru ve fázi „přípravy“ a další sada zpráv je odesílána ve fázi „potvrzení“. Tento přístup obvykle není vhodný pro geograficky odlišné uzly kvůli latenci při odesílání zpráv mezi uzly.
Vysoký ping
Galera Cluster s výchozím nastavením nezvládá dobře vysokou latenci sítě. Pokud máte síť s uzlem, který vykazuje vysokou dobu pingu, zvažte změnu parametrů evs.send_window a evs.user_send_window. Tyto proměnné definují maximální počet datových paketů v replikaci najednou. U nastavení WAN lze proměnnou nastavit na podstatně vyšší hodnotu, než je výchozí hodnota 2. Běžně se nastavuje na 512. Tyto parametry jsou součástí wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Velikost transakce
Jednou z věcí, kterou musíte při spuštění Galera Cluster zvážit, je velikost transakce. Nalezení rovnováhy mezi velikostí transakce, výkonem a certifikačním procesem Galera je něco, co musíte ve své aplikaci odhadnout. Více informací o tom najdete v článku Jak zlepšit výkon Galera Cluster pro MySQL nebo MariaDB od Ashrafa Sharifa.
Čtení příčinné konzistence nástroje Load Balancer
I při minimalizovaném riziku problémů s latencí dat nemůže standardní asynchronní replikace MySQL zaručit konzistenci. Stále je možné, že data ještě nejsou replikována na podřízenou jednotku, zatímco vaše aplikace je odtud čte. Synchronní replikace může tento problém vyřešit, ale má omezení architektury a nemusí vyhovovat požadavkům vaší aplikace (např. intenzivní hromadné zápisy). Jak to tedy překonat?
Prvním krokem, jak se vyhnout zastaralému čtení dat, je upozornit aplikaci na zpoždění replikace. Obvykle je naprogramován v kódu aplikace. Naštěstí existují moderní databázové load balancery s podporou adaptivního směrování dotazů na základě GTID trackingu. Nejoblíbenější jsou ProxySQL a Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader umožňuje ProxySQL v reálném čase vědět, které GTID bylo spuštěno na každém serveru MySQL, podřízených a masterech. Díky tomu, když klient provádí čtení, které potřebuje zajistit kauzální konzistenci čtení, ProxySQL okamžitě ví, na kterém serveru lze dotaz provést. Pokud z jakéhokoli důvodu ještě nebyly provedeny zápisy na žádném podřízeném zařízení, ProxySQL bude vědět, že zapisovač byl proveden na hlavním serveru, a odešle čtení tam.
Maximální měřítko 2.3
MariaDB představila příležitostné čtení v Maxscale 2.3.0. Způsob, jakým to funguje, je podobný ProxySQL 2.0. V zásadě, když je povoleno causal_reads, jakékoli následné čtení prováděné na podřízených serverech bude provedeno způsobem, který zabrání ovlivnění výsledků zpožděním replikace. Pokud se slave zařízení během nastavené doby nedohoní k masteru, bude dotaz zopakován na masteru.