V předchozím blogu jsme oznámili novou funkci ClusterControl 1.7.4 nazvanou Cluster-to-Cluster Replication. Automatizuje celý proces nastavení clusteru DR mimo váš primární cluster s replikací mezi tím. Podrobnější informace naleznete ve výše uvedeném příspěvku na blogu.
Nyní v tomto blogu se podíváme na to, jak nakonfigurovat tuto novou funkci pro existující cluster. Pro tento úkol budeme předpokládat, že máte nainstalovaný ClusterControl a že byl Master Cluster nasazen pomocí něj.
Požadavky na hlavní cluster
Aby Master Cluster fungoval, existují určité požadavky:
- Percona XtraDB Cluster verze 5.6.xa novější nebo MariaDB Galera Cluster verze 10.xa novější.
- GTID povoleno.
- Binární protokolování povoleno alespoň na jednom databázovém uzlu.
- Pověřovací údaje pro zálohování musí být stejné v celém hlavním clusteru a podřízeném clusteru.
Příprava hlavního clusteru
Master Cluster musí být připraven na použití této nové funkce. Vyžaduje konfiguraci ze strany ClusterControl i Database.
Konfigurace ClusterControl
V uzlu databáze zkontrolujte přihlašovací údaje uživatele záloh uložené v /etc/my.cnf.d/secrets-backup.cnf (pro operační systém RedHat) nebo v /etc/mysql/secrets-backup .cnf (pro OS založený na Debianu).
$ cat /etc/my.cnf.d/secrets-backup.cnf
# Security credentials for backup.
[mysqldump]
user=backupuser
password=cYj0GFBEdqdreZEl
[xtrabackup]
user=backupuser
password=cYj0GFBEdqdreZEl
[mysqld]
wsrep_sst_auth=backupuser:cYj0GFBEdqdreZElV uzlu ClusterControl upravte konfigurační soubor /etc/cmon.d/cmon_ID.cnf (kde ID je ID clusteru) a ujistěte se, že obsahuje stejná pověření jako u secrets-backup. cnf.
$ cat /etc/cmon.d/cmon_8.cnf
backup_user=backupuser
backup_user_password=cYj0GFBEdqdreZEl
basedir=/usr
cdt_path=/
cluster_id=8
...Jakákoli změna v tomto souboru vyžaduje restart služby cmon:
$ service cmon restartZkontrolujte parametry replikace databáze a ujistěte se, že máte povoleno GTID a binární protokolování.
Konfigurace databáze
V databázovém uzlu zkontrolujte soubor /etc/my.cnf (pro OS založený na RedHat) nebo /etc/mysql/my.cnf (pro OS založený na Debianu), abyste viděli konfiguraci související s proces replikace.
Percona XtraDB:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=4002
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-log
expire_logs_days = 7Cluster MariaDB Galera:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=9000
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
relay_log = relay-log
wsrep_gtid_domain_id=9000
wsrep_gtid_mode=ON
gtid_domain_id=9000
gtid_strict_mode=ON
gtid_ignore_duplicates=ON
expire_logs_days = 7Namísto kontroly konfiguračních souborů můžete ověřit, zda je povoleno v uživatelském rozhraní ClusterControl. Přejděte do ClusterControl -> Vybrat cluster -> Uzly. Zde byste měli mít něco takového:

Role „Master“ přidaná do prvního uzlu znamená, že binární protokolování je povoleno.
Povolení binárního protokolování
Pokud nemáte povoleno binární protokolování, přejděte na ClusterControl -> Vyberte Cluster -> Uzly -> Akce uzlů -> Povolit binární protokolování.
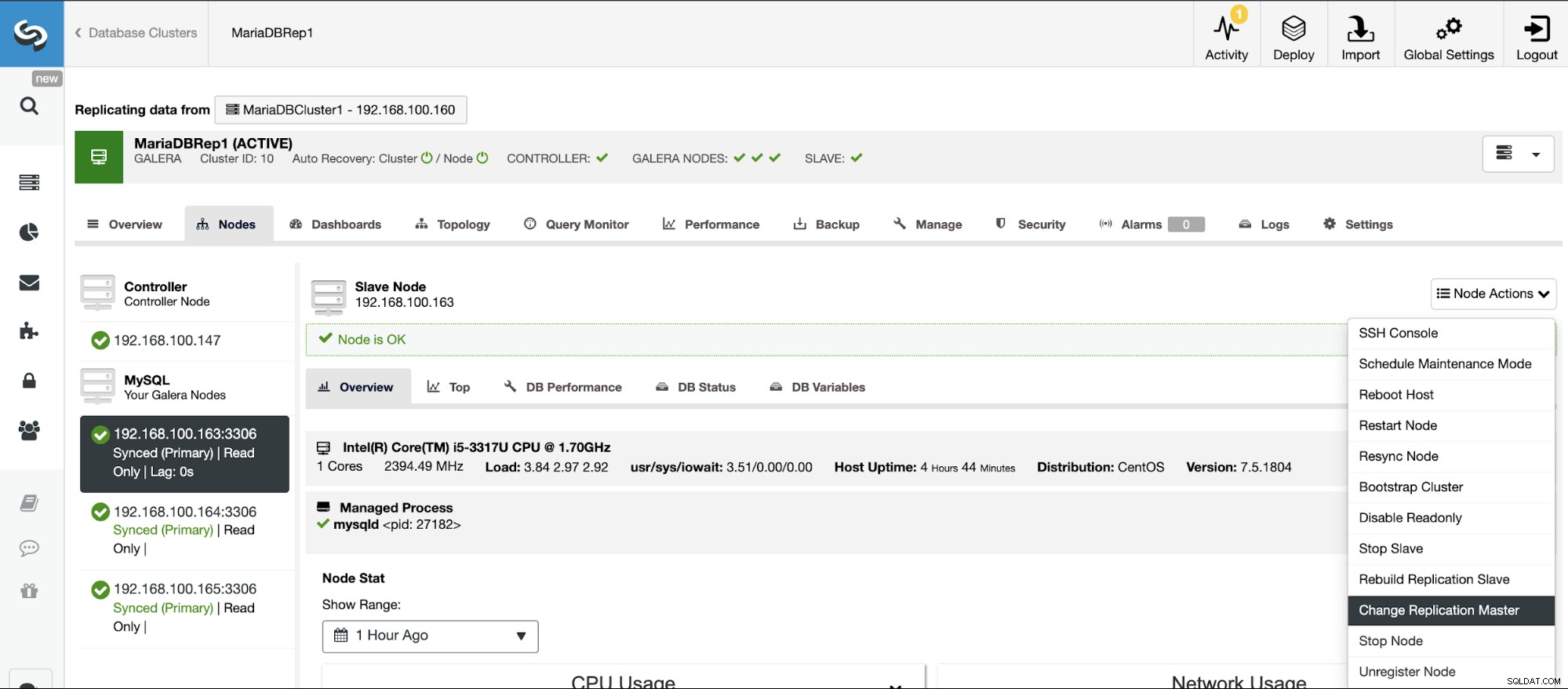
Potom musíte zadat uchování binárního protokolu a cestu k uložení to. Měli byste také určit, zda chcete, aby ClusterControl restartoval databázový uzel po jeho konfiguraci, nebo zda jej chcete restartovat sami.
Mějte na paměti, že povolení binárního protokolování vždy vyžaduje restartování databázové služby .
Vytvoření Slave Clusteru z GUI ClusterControl
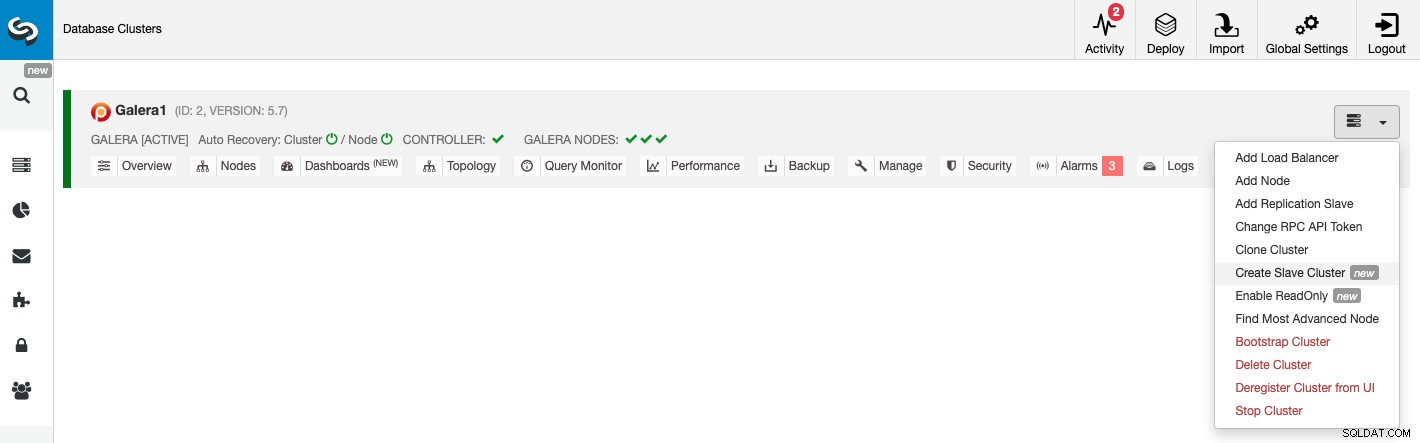
Chcete-li vytvořit nový Slave Cluster, přejděte na ClusterControl -> Vyberte Cluster -> Akce clusteru -> Vytvořit Slave Cluster.
Podřízený cluster lze vytvořit streamováním dat z aktuálního hlavního clusteru nebo pomocí existující zálohy.
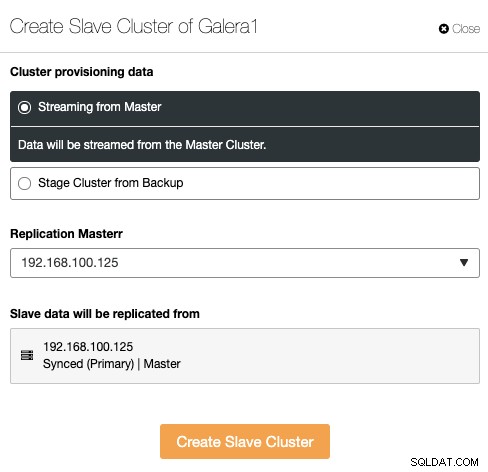
V této části musíte také vybrat hlavní uzel aktuálního clusteru ze kterého budou data replikována.
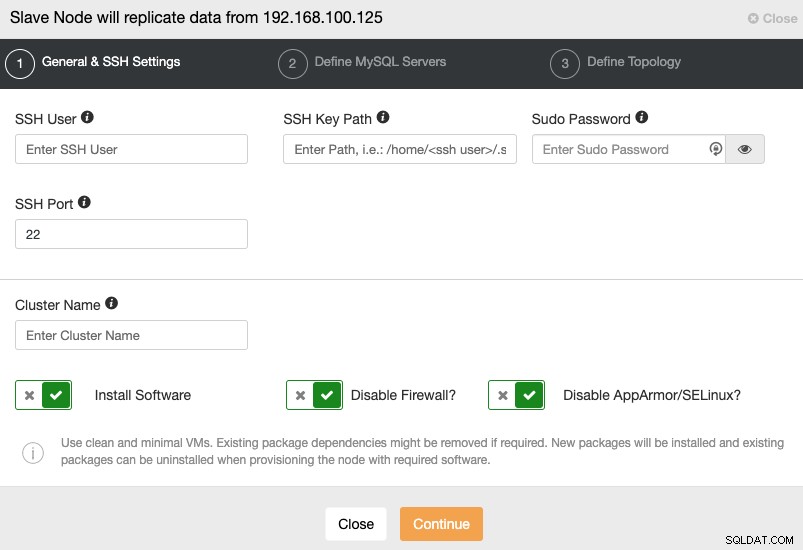
Když přejdete k dalšímu kroku, musíte zadat uživatele, klíč nebo Heslo a port pro připojení pomocí SSH k vašim serverům. Potřebujete také název svého Slave Clusteru a pokud chcete, aby ClusterControl nainstaloval odpovídající software a konfigurace za vás.
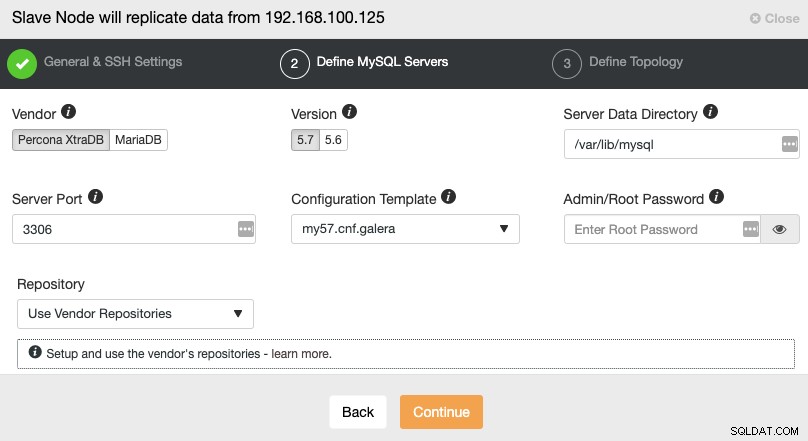
Po nastavení informací o přístupu SSH musíte definovat dodavatele databáze a verze, datadir, databázový port a heslo správce. Ujistěte se, že používáte stejného dodavatele/verzi a přihlašovací údaje, jaké používá hlavní cluster. Můžete také určit, které úložiště použít.
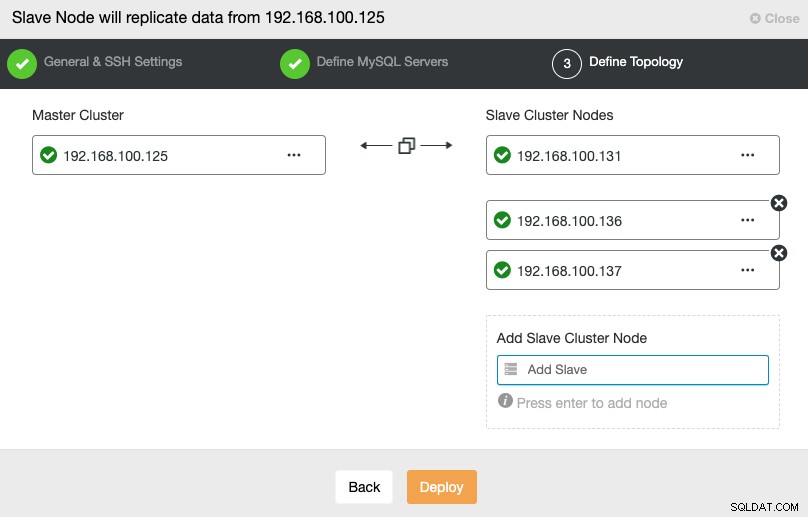
V tomto kroku je třeba přidat servery do nového Slave Clusteru. Pro tento úkol můžete zadat IP adresu nebo název hostitele každého databázového uzlu.
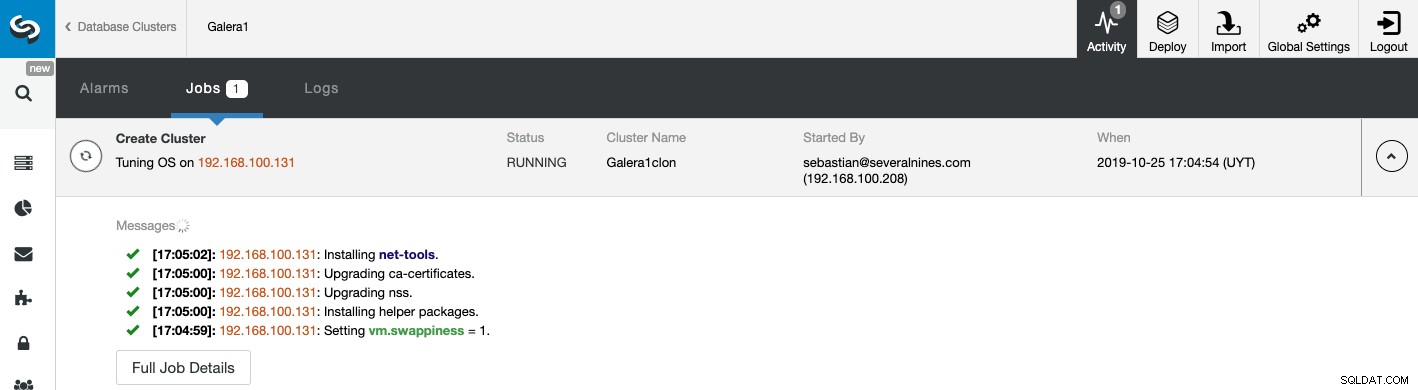
Stav vytváření vašeho nového Slave Clusteru můžete sledovat na Monitor aktivity ClusterControl. Po dokončení úlohy můžete vidět cluster na hlavní obrazovce ClusterControl.
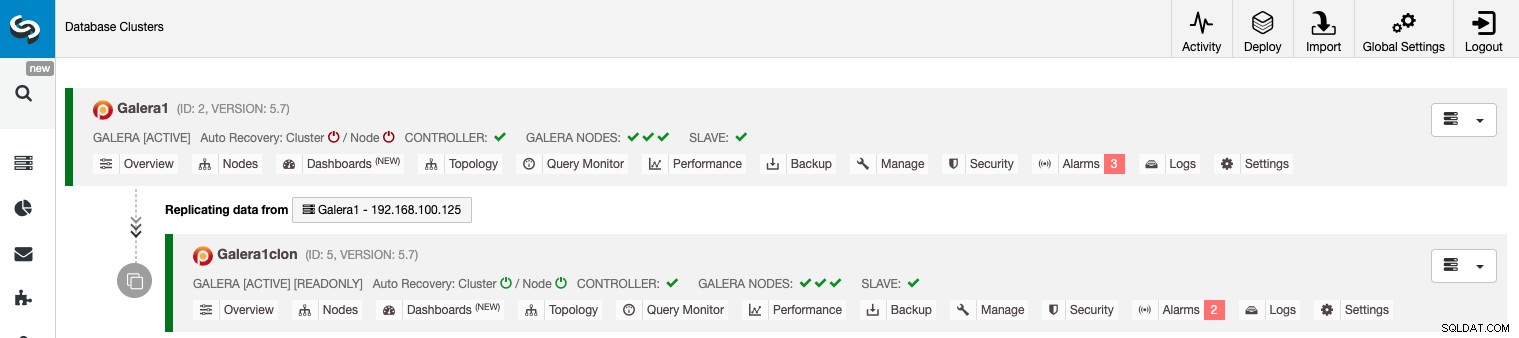
Správa replikace Cluster-to-Cluster pomocí GUI ClusterControl
Nyní máte svou replikaci Cluster-to-Cluster v provozu a pomocí ClusterControl lze v této topologii provádět různé akce.
Konfigurace aktivních a aktivních clusterů
Jak vidíte, ve výchozím nastavení je Slave Cluster nastaven v režimu Pouze pro čtení. Je možné deaktivovat příznak Pouze pro čtení na uzlech jeden po druhém z uživatelského rozhraní ClusterControl, ale mějte na paměti, že klastrování Active-Active se doporučuje pouze v případě, že se aplikace dotýkají pouze nesouvislých datových sad v jednom z clusterů, protože MySQL/MariaDB to nedělá. nabídnout jakoukoli detekci nebo řešení konfliktů.
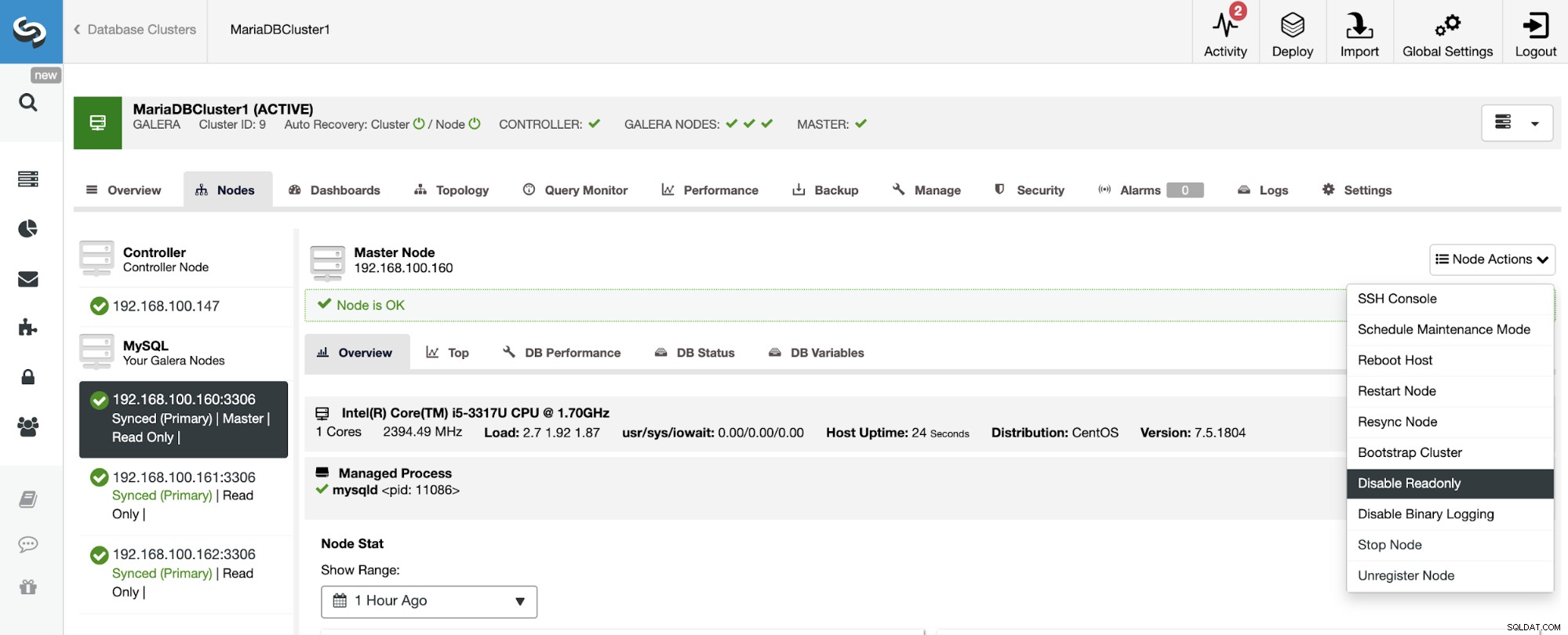
Chcete-li deaktivovat režim pouze pro čtení, přejděte na ClusterControl -> Select Slave Cluster -> Nodes. V této části vyberte každý uzel a použijte možnost Zakázat pouze pro čtení.
Přebudování klastru Slave
Chcete-li znovu sestavit Slave Cluster, musí to být cluster pouze pro čtení, což znamená, že všechny uzly musí být v režimu pouze pro čtení, aby se předešlo nesrovnalostem.
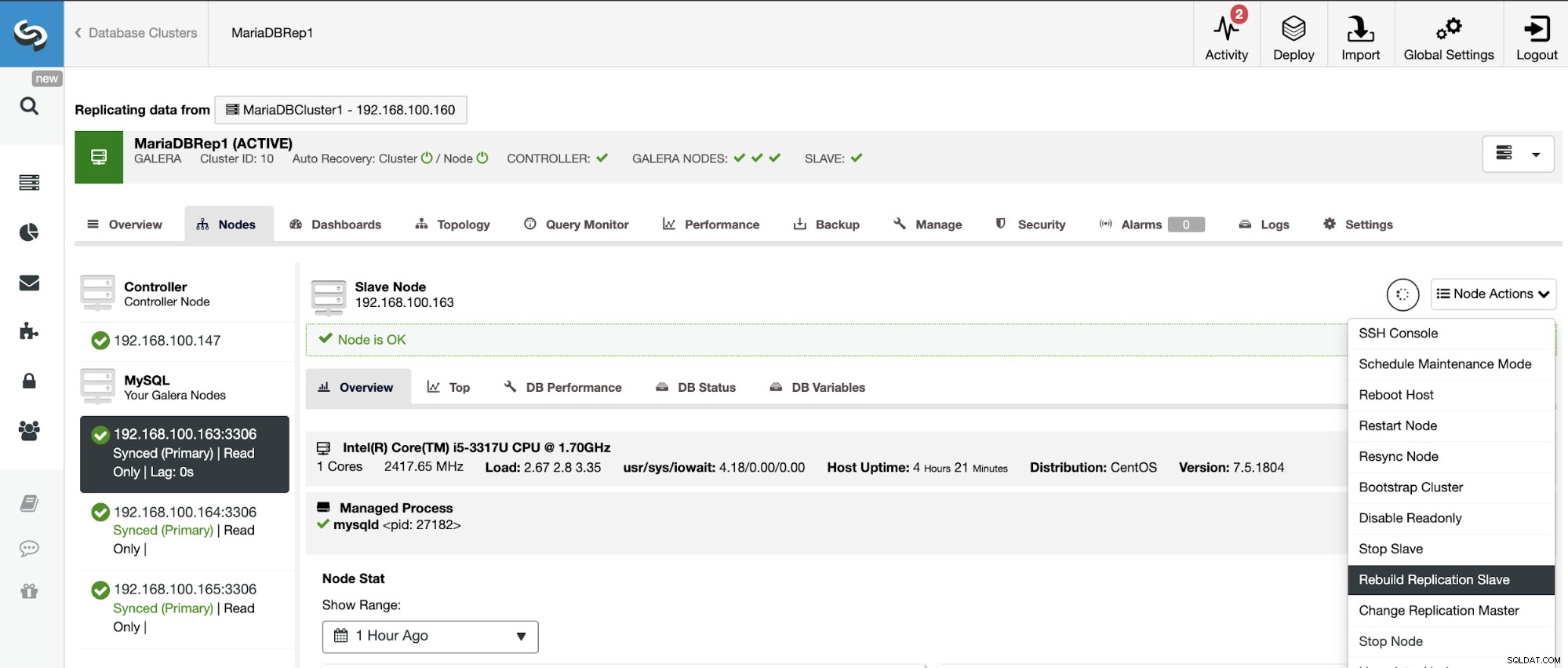
Přejděte na ClusterControl -> Vyberte podřízený cluster -> Uzly -> Vyberte Uzel připojený k hlavnímu clusteru -> Akce uzlů -> Znovu sestavit slave replikace.
Změny topologie
Pokud máte následující topologii:
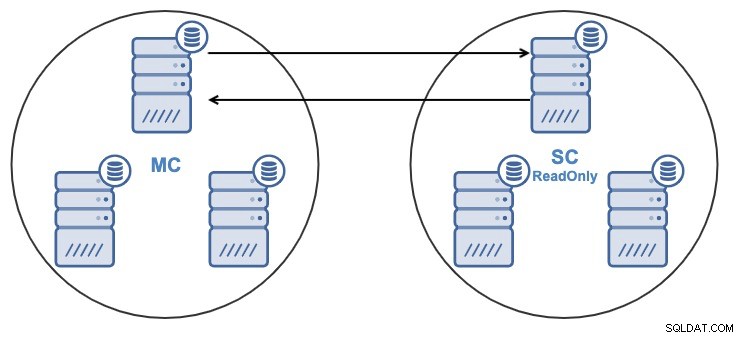
A z nějakého důvodu chcete změnit uzel replikace v hlavním Cluster. Je možné změnit hlavní uzel používaný podřízeným clusterem na jiný hlavní uzel v hlavním clusteru.
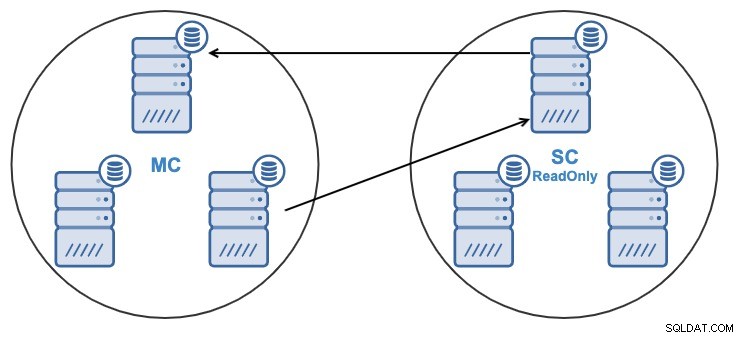
Aby mohl být považován za hlavní uzel, musí mít povoleno binární protokolování .
Přejděte na ClusterControl -> Vyberte podřízený cluster -> Uzly -> Vyberte Uzel připojený k hlavnímu clusteru -> Akce uzlů -> Zastavit Slave/Spustit Slave.
Zastavit/Spustit podřízenou replikaci
Replikaci slave můžete jednoduše zastavit a spustit pomocí ClusterControl.
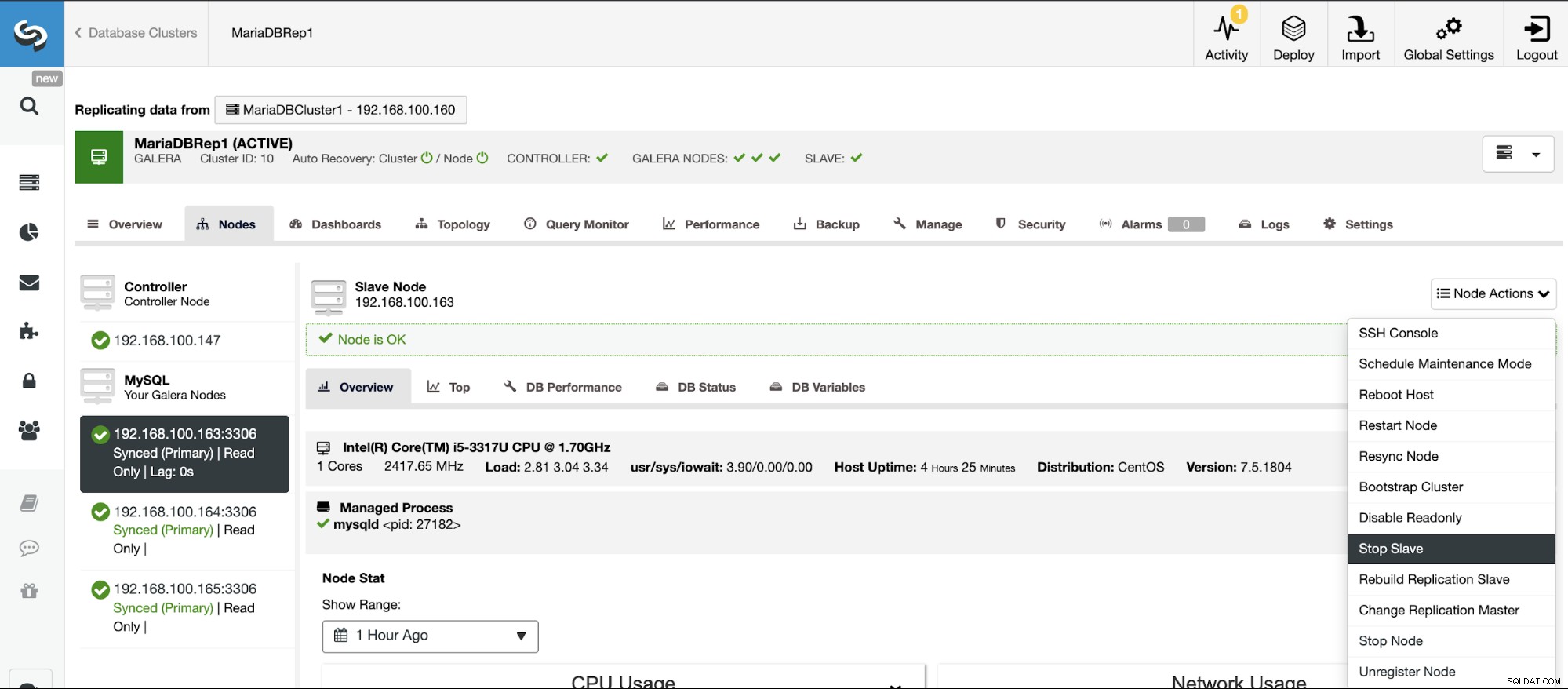
Přejděte na ClusterControl -> Vyberte podřízený cluster -> Uzly -> Vyberte Uzel připojený k hlavnímu clusteru -> Akce uzlů -> Zastavit Slave/Spustit Slave.
Resetovat podřízenou replikaci
Pomocí této akce můžete resetovat proces replikace pomocí RESET SLAVE nebo RESET SLAVE ALL. Rozdíl mezi nimi je ten, že RESET SLAVE nemění žádný parametr replikace, jako je hlavní hostitel, port a přihlašovací údaje. Chcete-li tyto informace odstranit, musíte použít RESET SLAVE ALL, který odstraní veškerou konfiguraci replikace, takže použitím tohoto příkazu bude zničeno propojení replikace mezi clustery.
Před použitím této funkce musíte zastavit proces replikace (viz předchozí funkce).
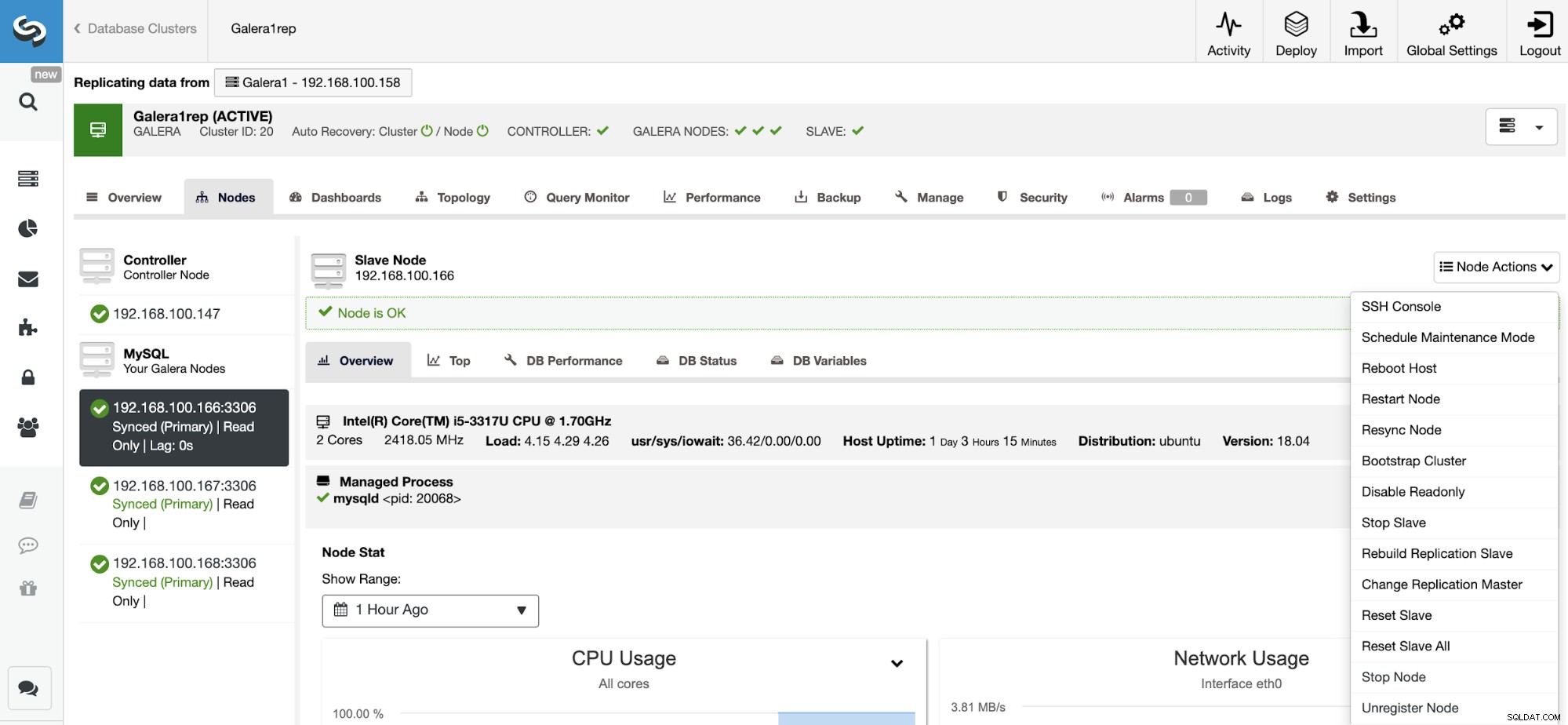
Přejděte na ClusterControl -> Vyberte podřízený cluster -> Uzly -> Vyberte Uzel připojený k Master Clusteru -> Akce uzlu -> Reset Slave/Reset Slave All.
Správa replikace Cluster-to-Cluster pomocí rozhraní CLI ClusterControl
V předchozí části jste mohli vidět, jak spravovat replikaci clusteru do clusteru pomocí uživatelského rozhraní ClusterControl. Nyní se podívejme, jak to udělat pomocí příkazového řádku.
Poznámka:Jak jsme zmínili na začátku tohoto blogu, budeme předpokládat, že máte nainstalovaný ClusterControl a že jste pomocí něj nasadili Master Cluster.
Vytvořte cluster Slave
Nejprve se podívejme na příklad příkazu k vytvoření klastru Slave pomocí CLI ClusterControl:
$ s9s cluster --create --cluster-name=Galera1rep --cluster-type=galera --provider-version=10.4 --nodes="192.168.100.166;192.168.100.167;192.168.100.168" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=root --db-admin-passwd=xxxxxxxx --vendor=mariadb --remote-cluster-id=11 --logNyní máte spuštěný proces vytvoření podřízeného zařízení, podívejme se na každý použitý parametr:
- Cluster:Seznam a manipulace se shluky.
- Vytvořit:Vytvořte a nainstalujte nový cluster.
- Cluster-name:Název nového Slave Clusteru.
- Typ clusteru:Typ clusteru, který se má nainstalovat.
- Verze poskytovatele:Verze softwaru.
- Uzly:Seznam nových uzlů v clusteru Slave.
- Os-user:Uživatelské jméno pro příkazy SSH.
- Os-key-file:Soubor klíče, který se má použít pro připojení SSH.
- Db-admin:Uživatelské jméno správce databáze.
- Db-admin-passwd:Heslo pro správce databáze.
- Remote-cluster-id:ID hlavního clusteru pro replikaci clusteru do clusteru.
- Protokol:Čekejte a sledujte zprávy úloh.
Pomocí příznaku --log budete moci vidět protokoly v reálném čase:
Verifying job parameters.
Checking ssh/sudo on 3 hosts.
All 3 hosts are accessible by SSH.
192.168.100.166: Checking if host already exists in another cluster.
192.168.100.167: Checking if host already exists in another cluster.
192.168.100.168: Checking if host already exists in another cluster.
192.168.100.157:3306: Binary logging is enabled.
192.168.100.158:3306: Binary logging is enabled.
Creating the cluster with the following:
wsrep_cluster_address = 'gcomm://192.168.100.166,192.168.100.167,192.168.100.168'
Calling job: setupServer(192.168.100.166).
192.168.100.166: Checking OS information.
…
Caching config files.
Job finished, all the nodes have been added successfully.Konfigurace aktivních a aktivních clusterů
Jak jste mohli vidět dříve, v novém clusteru můžete deaktivovat režim pouze pro čtení jeho zakázáním v každém uzlu, takže se podívejme, jak to udělat z příkazového řádku.
$ s9s node --set-read-write --nodes="192.168.100.166" --cluster-id=16 --logPodívejme se na jednotlivé parametry:
- Uzel:Ke zpracování uzlů.
- Nastavit čtení-zápis:Nastavte uzel do režimu čtení-zápis.
- Uzel:Uzel, kde to změnit.
- Cluster-id:ID clusteru, ve kterém je uzel.
Potom uvidíte:
192.168.100.166:3306: Setting read_only=OFF.Přebudování klastru Slave
Můžete znovu sestavit Slave Cluster pomocí následujícího příkazu:
$ s9s replication --stage --master="192.168.100.157:3306" --slave="192.168.100.166:3306" --cluster-id=19 --remote-cluster-id=11 --logParametry jsou:
- Replikace:Sledování a řízení replikace dat.
- Fáze:Stage/Rebuild Replication Slave.
- Hlavní:Hlavní replikační server v hlavním clusteru.
- Slave:Replikační slave v podřízeném clusteru.
- Cluster-id:The Slave Cluster ID.
- Remote-cluster-id:ID hlavního clusteru.
- Protokol:Čekejte a sledujte zprávy úloh.
Protokol úlohy by měl být podobný tomuto:
Rebuild replication slave 192.168.100.166:3306 from master 192.168.100.157:3306.
Remote cluster id = 11
Shutting down Galera Cluster.
192.168.100.166:3306: Stopping node.
192.168.100.166:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.166: Stopping MySQL service.
192.168.100.166: All processes stopped.
192.168.100.166:3306: Stopped node.
192.168.100.167:3306: Stopping node.
192.168.100.167:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.167: Stopping MySQL service.
192.168.100.167: All processes stopped.
…
192.168.100.157:3306: Changing master to 192.168.100.166:3306.
192.168.100.157:3306: Changed master to 192.168.100.166:3306
192.168.100.157:3306: Starting slave.
192.168.100.157:3306: Collecting replication statistics.
192.168.100.157:3306: Started slave successfully.
192.168.100.166:3306: Starting node
Writing file '192.168.100.167:/etc/mysql/my.cnf'.
Writing file '192.168.100.167:/etc/mysql/secrets-backup.cnf'.
Writing file '192.168.100.168:/etc/mysql/my.cnf'.Změny topologie
Svou topologii můžete změnit pomocí jiného uzlu v hlavním clusteru, ze kterého replikujete data, takže můžete například spustit:
$ s9s replication --failover --master="192.168.100.161:3306" --slave="192.168.100.163:3306" --cluster-id=10 --remote-cluster-id=9 --logPodívejme se na použité parametry.
- Replikace:Sledování a řízení replikace dat.
- Failover:Převezměte roli mistra z neúspěšného/starého mistra.
- Hlavní:Nový hlavní replikační server v hlavním clusteru.
- Slave:Replikační otrok v clusteru Slave.
- Cluster-id:ID klastru Slave.
- Remote-Cluster-id:ID hlavního clusteru.
- Protokol:Čekejte a sledujte zprávy úloh.
Uvidíte tento protokol:
192.168.100.161:3306 belongs to cluster id 9.
192.168.100.163:3306: Changing master to 192.168.100.161:3306
192.168.100.163:3306: My master is 192.168.100.160:3306.
192.168.100.161:3306: Sanity checking replication master '192.168.100.161:3306[cid:9]' to be used by '192.168.100.163[cid:139814070386698]'.
192.168.100.161:3306: Executing GRANT REPLICATION SLAVE ON *.* TO 'cmon_replication'@'192.168.100.163'.
Setting up link between 192.168.100.161:3306 and 192.168.100.163:3306
192.168.100.163:3306: Stopping slave.
192.168.100.163:3306: Successfully stopped slave.
192.168.100.163:3306: Setting up replication using MariaDB GTID: 192.168.100.161:3306->192.168.100.163:3306.
192.168.100.163:3306: Changing Master using master_use_gtid=slave_pos.
192.168.100.163:3306: Changing master to 192.168.100.161:3306.
192.168.100.163:3306: Changed master to 192.168.100.161:3306
192.168.100.163:3306: Starting slave.
192.168.100.163:3306: Collecting replication statistics.
192.168.100.163:3306: Started slave successfully.
192.168.100.160:3306: Flushing logs to update 'SHOW SLAVE HOSTS'Zastavit/Spustit podřízenou replikaci
Můžete zastavit replikaci dat z Master Clusteru tímto způsobem:
$ s9s replication --stop --slave="192.168.100.166:3306" --cluster-id=19 --logUvidíte toto:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Stopping slave.
192.168.100.166:3306: Successfully stopped slave.A teď to můžete začít znovu:
$ s9s replication --start --slave="192.168.100.166:3306" --cluster-id=19 --logUvidíte tedy:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Starting slave.
192.168.100.166:3306: Collecting replication statistics.
192.168.100.166:3306: Started slave successfully.Nyní se podíváme na použité parametry.
- Replikace:Sledování a řízení replikace dat.
- Stop/Start:Chcete-li, aby se slave zastavil/spustil replikaci.
- Slave:Podřízený uzel replikace.
- Cluster-id:ID clusteru, ve kterém je podřízený uzel.
- Protokol:Čekejte a sledujte zprávy úloh.
Resetovat podřízenou replikaci
Pomocí tohoto příkazu můžete resetovat proces replikace pomocí RESET SLAVE nebo RESET SLAVE ALL. Další informace o tomto příkazu naleznete v předchozí části uživatelského rozhraní ClusterControl.
Před použitím této funkce musíte zastavit proces replikace (viz předchozí příkaz).
RESETOVAT SLAVE:
$ s9s replication --reset --slave="192.168.100.166:3306" --cluster-id=19 --logProtokol by měl vypadat takto:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE'.
192.168.100.166:3306: Command 'RESET SLAVE' succeeded.RESETOVAT SLAVE VŠE:
$ s9s replication --reset --force --slave="192.168.100.166:3306" --cluster-id=19 --logA tento protokol by měl být:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
192.168.100.166:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.Podívejme se na použité parametry pro RESET SLAVE a RESET SLAVE ALL.
- Replikace:Sledování a řízení replikace dat.
- Resetovat:Resetuje podřízený uzel.
- Vynutit:Pomocí tohoto příznaku použijete příkaz RESET SLAVE ALL na podřízeném uzlu.
- Slave:Podřízený uzel replikace.
- Cluster-id:The Slave Cluster ID.
- Protokol:Čekejte a sledujte zprávy úloh.
Závěr
Tato nová funkce ClusterControl vám umožní rychle vytvářet replikaci mezi clustery a spravovat ji snadným a přátelským způsobem. Toto prostředí vylepší topologii vaší databáze/klastru a bylo by užitečné pro plán obnovy po havárii, testovací prostředí a ještě další možnosti uvedené v přehledovém blogu.