Vývojář Oracle, který v kódu často používá regulární výrazy, dříve nebo později může čelit fenoménu, který je vskutku mystický. Dlouhodobé pátrání po kořenech problému může vést ke ztrátě hmotnosti, chuti k jídlu a vyvolat různé druhy psychosomatických poruch – tomu všemu lze předejít pomocí funkce regexp_replace. Může mít až 6 argumentů:
REGEXP_REPLACE (
- zdrojový_řetězec,
- šablonu,
- substituting_string,
- počáteční pozice vyhledávání shody se šablonou (výchozí 1),
- umístění výskytu šablony ve zdrojovém řetězci (ve výchozím nastavení se 0 rovná všem výskytům),
- modifikátor (zatím je to černý kůň)
)
Vrátí upravený zdrojový_řetězec, ve kterém jsou všechny výskyty šablony nahrazeny hodnotou předanou v parametru substituting_string. Často se používá krátká verze funkce, kde jsou uvedeny první 3 argumenty, což stačí k vyřešení mnoha problémů. Udělám to samé. Předpokládejme, že potřebujeme maskovat všechny znaky řetězce hvězdičkami v řetězci ‚MASK:malá písmena‘. Pro určení rozsahu malých písmen by měl vyhovovat vzor „[a-z]“.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Očekávání
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Realita
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Pokud tato událost nebyla reprodukována ve vaší databázi, pak máte zatím štěstí. Ale častěji se začnete vrtat v kódu, převádět řetězce z jedné sady znaků na jinou a nakonec přijde zoufalství.
Definování problému
Vyvstává otázka – co je na písmenu „A“ tak zvláštního, že nebylo nahrazeno, protože se nemělo nahradit ani zbývající velká písmena. Možná existují jiná správná písmena kromě tohoto. Je nutné se podívat na celou abecedu velkých písmen.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Nicméně
Pokud 6. argument funkce není výslovně uveden, například 'i' nerozlišuje malá a velká písmena nebo 'c' nerozlišuje malá a velká písmena při porovnávání zdrojového řetězce se šablonou, regulární výraz standardně používá parametr NLS_SORT relace/databáze. Například:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Tento parametr určuje způsob řazení v ORDER BY. Pokud mluvíme o řazení jednoduchých jednotlivých znaků, pak každému z nich odpovídá určité binární číslo (NLSSORT-kód) a řazení vlastně probíhá podle hodnoty těchto čísel.
Abychom to ilustrovali, vezměme prvních a posledních několik znaků abecedy, jak malá, tak velká písmena, a vložíme je do podmíněně neuspořádané tabulky a nazvěme ji ABC. Poté tuto sadu seřaďme podle pole SYMBOL a zobrazme její kód NLSSORT v HEX formátu vedle každého symbolu.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
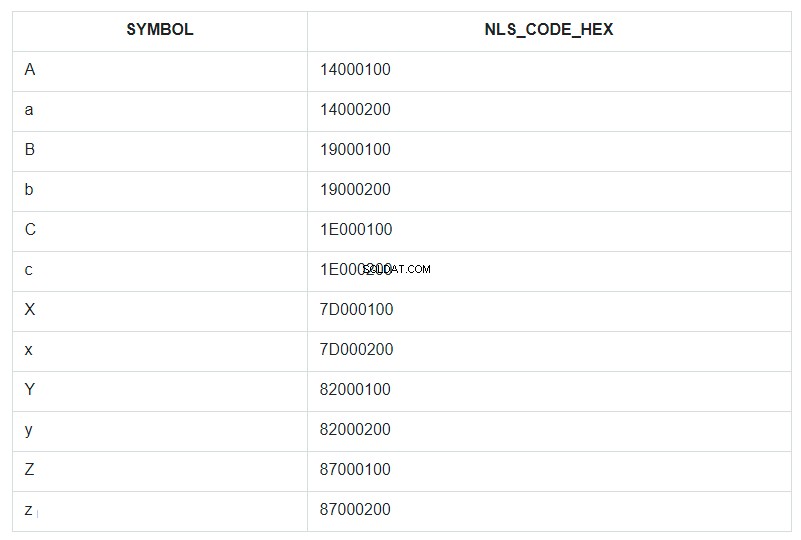
V dotazu je pro pole SYMBOL uvedeno ORDER BY, ale ve skutečnosti v databázi probíhalo řazení podle hodnot z pole NLS_CODE_HEX.
Nyní se vraťte k rozsahu ze šablony a podívejte se na tabulku – co je svisle mezi symbolem „a“ (kód 14000200) a „z“ (kód 87000200)? Vše kromě velkého písmene „A“. To je vše, co bylo nahrazeno hvězdičkou. A kód 14000100 písmene „A“ není zahrnut v rozsahu náhrady od 14000200 do 87000200.
Vyléčit
Explicitně specifikujte modifikátor rozlišování malých a velkých písmen
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Některé zdroje říkají, že modifikátor „c“ je nastaven jako výchozí, ale právě jsme viděli, že to není tak docela pravda. A pokud to někdo neviděl, pak je parametr NLS_SORT jeho relace/databáze s největší pravděpodobností nastaven na BINARY a řazení se provádí v souladu se skutečnými kódy znaků. Pokud změníte parametr relace, problém bude vyřešen.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Testy byly provedeny v Oracle 12c.
Neváhejte zanechat své komentáře a opatrujte se.