Zjistěte, jak používat nástroje OCR, Apache Spark a další komponenty Apache Hadoop ke zpracování obrázků PDF ve velkém měřítku.
Technologie optického rozpoznávání znaků (OCR) za posledních 20 let výrazně pokročily. Během této doby však bylo vynaloženo jen malé nebo žádné úsilí o spojení OCR s distribuovanými architekturami, jako je Apache Hadoop, pro zpracování velkého množství obrázků v téměř reálném čase.
V tomto příspěvku se dozvíte, jak používat standardní nástroje s otevřeným zdrojovým kódem spolu s komponentami Hadoop, jako jsou Apache Spark, Apache Solr a Apache HBase, abyste to udělali pro případ použití informací o zdravotnických zařízeních. Konkrétně použijete veřejnou datovou sadu k převodu narativního textu na pole s možností vyhledávání.
Ačkoli se tento příklad soustředí na informace o zdravotnických pomůckách, lze jej použít v mnoha jiných scénářích, kde je vyžadováno zpracování a uchování snímků. Pojišťovny mohou například zpřístupnit všechny své naskenované dokumenty v kartotékách škod pro lepší řešení škod. Podobně by oddělení dodavatelského řetězce ve výrobním závodě mohlo naskenovat všechny technické listy od dodavatelů dílů a umožnit jejich vyhledávání pro analytiky.
Případ použití:Registrace zdravotnického zařízení
V posledních letech došlo v oblasti elektronické registrace léčivých přípravků k řadě změn. ISO norma IDMP (Identification of medical products) je jedním z takových formátů zpráv pro registraci produktů a látek v nich obsažených, přičemž ID léčivého přípravku, ID balení a ID šarže se používají ke sledování produktů v případě nežádoucích účinků, nezákonné. dovoz, padělání a další otázky farmakovigilance. Norma požaduje, aby se nové produkty nejen registrovaly, ale aby starší/archivovaná evidence každého produktu, kterému by mohla být veřejnost vystavena, byla poskytnuta v elektronické podobě.
Aby byly v souladu se standardy IDMP v různých společnostech, musí být společnosti schopny získávat a zpracovávat data z různých zdrojů dat, jako je RDBMS, a v některých případech také ze starších produktových listů. I když je dobře známo, jak ingestovat data z RDBMS pomocí technologií jako Apache Sqoop, starší zpracování dokumentů vyžaduje trochu více práce. Z velké části je třeba dokumenty zpracovat a příslušný text je třeba programově extrahovat ve velkém měřítku pomocí stávajících technologií OCR.
Soubor dat
Použijeme soubor dat od FDA, který obsahuje všechny záznamy 510(k), které kdy výrobci zdravotnických prostředků předložili od roku 1976. Sekce 510(k) zákona o potravinách, léčivech a kosmetice vyžaduje, aby výrobci zařízení, kteří se musí registrovat, informovali FDA o jejich záměru uvést na trh zdravotnický prostředek alespoň 90 dní předem.
Tato datová sada je v tomto případě užitečná z několika důvodů:
- Data jsou zdarma a ve veřejné doméně.
- Údaje přesně zapadají do evropského nařízení, které vstoupí v platnost v červenci 2016 (kde musí výrobci splňovat nové datové standardy). Výplně FDA obsahují důležité informace důležité pro odvození úplného pohledu na IDMP.
- Formát dokumentů (PDF) nám umožňuje demonstrovat jednoduché, ale účinné techniky OCR při práci s dokumenty různých formátů.
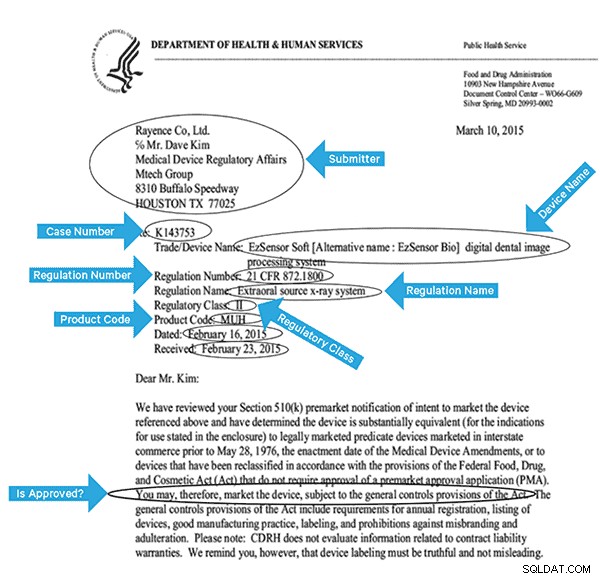
Abychom tato data efektivně indexovali, musíme z obrázků extrahovat některá pole. Níže je ukázkový dokument s potenciálními poli, která lze extrahovat.
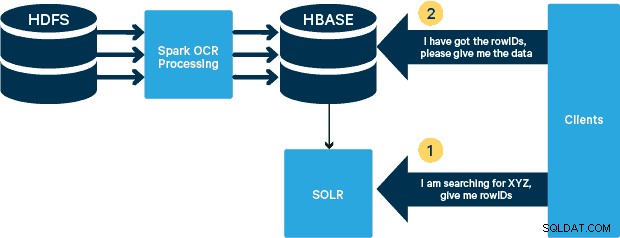
Architektura na vysoké úrovni
Pro tento případ použití jsou soubory PDF uloženy v HDFS a zpracovány pomocí knihoven Spark a OCR. (Krok příjmu je mimo rozsah tohoto příspěvku, ale mohl by být stejně jednoduchý jako spuštění hdfs -dfs -put nebo pomocí rozhraní webhdfs.) Spark umožňuje použití téměř identického kódu v aplikaci Spark Streaming pro streamování téměř v reálném čase a HBase je perfektní úložné médium pro náhodný přístup s nízkou latencí – a dobře se hodí pro ukládání obrázků s nová funkce MOB, zavést. Cloudera Search (který je postaven na Apache Solr) je jediným vyhledávacím řešením, které se nativně integruje s HBase, což vám umožňuje vytvářet sekundární indexy.
Nastavení tabulky zdravotnických prostředků v HBase
Schéma pro náš případ použití ponecháme jednoduché. rowID bude název souboru a budou existovat dvě rodiny sloupců:„info“ a „obj“. Rodina sloupců „info“ bude obsahovat všechna pole, která jsme z obrázků extrahovali. Rodina sloupců „obj“ bude obsahovat bajty skutečného binárního objektu, v tomto případě PDF. Název tabulky v našem případě bude „mdds.“
Využijeme funkcionalitu HBase MOB (střední objekt) zavedenou v HBASE-11339. Chcete-li nastavit HBase pro práci s MOB, je vyžadováno několik dalších kroků, ale pokyny najdete na tomto odkazu.
Existuje mnoho způsobů, jak vytvořit tabulku v HBase programově (Java API, REST API nebo podobná metoda). Zde použijeme shell HBase k vytvoření tabulky „mdds“ (záměrně použijeme popisný název rodiny sloupců, aby se věci lépe sledovaly). Chceme mít rodinu sloupců „info“ replikovanou do Solr, ale ne data MOB.
Níže uvedený příkaz vytvoří tabulku a umožní replikaci v rodině sloupců s názvem „info“. Je důležité zadat volbu REPLICATION_SCOPE => '1' , jinak HBase Lily Indexer nebude dostávat žádné aktualizace od HBase. Chceme použít cestu MOB v HBase pro objekty větší než 10 MB. Abychom toho dosáhli, vytvoříme také další rodinu sloupců nazvanou „obj“ s použitím následujících parametrů pro MOB:
IS_MOB => true, MOB_THRESHOLD => 10240000
IS_MOB parametr určuje, zda tato rodina sloupců může ukládat MOB, zatímco MOB_THRESHOLD určuje, jak velký musí být objekt, aby mohl být považován za MOB. Pojďme tedy vytvořit tabulku:
create 'mdds', {NAME => 'info', DATA_BLOCK_ENCODING => 'FAST_DIFF',REPLICATION_SCOPE => '1'}, {NAME => 'obj', IS_MOB => true, MOB_THRESHOLD => 10240000}
Chcete-li potvrdit, že tabulka byla vytvořena správně, spusťte v prostředí HBase následující příkaz:
hbase(main):001:0> description 'mdds'Table mdds is ENABLEDmddsCOLUMN FAMILIES DESCRIPTION{NAME => 'info', DATA_BLOCK_ENCODING => 'FAST_DIFF', BLOOMFILTER => 'ROW_SCOPE', REPLICATION , VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}{NAME => 'obj', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', COMPRESSION => 'NONE', VERSIONS => '1', MIN_VERSIONS => '0', TTL => 'FOREVER', MOB_THRESHOLD => '10240000', IS_MOB => 'true', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536 => IN_MEMORY', IN_MEMORY => 'true'}2 řádky za 0,3440 sekund Zpracování naskenovaných obrázků pomocí Tesseract
OCR urazilo dlouhou cestu, pokud jde o řešení problémů s variacemi písem, obrazovým šumem a zarovnáním. Zde použijeme open source OCR engine Tesseract, který byl původně vyvinut jako proprietární software v laboratořích HP. Vývoj Tesseract byl od té doby vydán jako software s otevřeným zdrojovým kódem a od roku 2006 je sponzorován společností Google.
Tesseract je vysoce přenosná softwarová knihovna. Využívá knihovnu pro zpracování obrázků Leptonica ke generování binárního obrázku pomocí adaptivního prahování na šedém nebo barevném obrázku.
Zpracování probíhá tradičním způsobem krok za krokem. Následuje hrubý postup kroků:
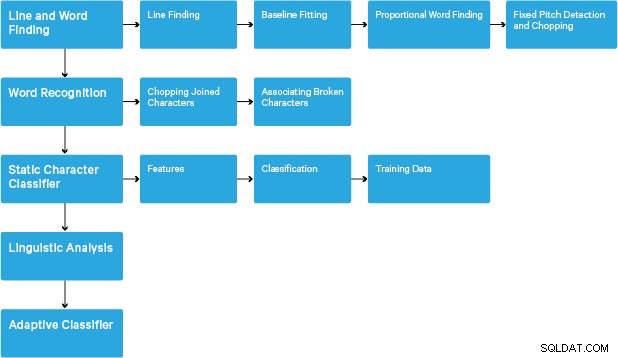
Zpracování začíná analýzou připojených komponent, jejímž výsledkem je uložení nalezených komponent. Tento krok pomáhá při kontrole vnoření obrysů a počtu obrysů dítěte a vnuka.
V této fázi se obrysy shromažďují dohromady, čistě vnořením, do binárních velkých objektů (BLOB). Objekty BLOB jsou organizovány do textových řádků a řádky a oblasti jsou analyzovány na pevnou rozteč nebo proporcionální text. Řádky textu jsou rozděleny na slova odlišně podle druhu mezer mezi znaky. Text s pevnou výškou je okamžitě sekán buňkami znaků. Proporcionální text je rozdělen na slova pomocí určitých mezer a fuzzy mezer.
Rozpoznávání pak probíhá jako dvouprůchodový proces. V prvním průchodu se postupně pokusí rozpoznat každé slovo. Každé slovo, které je vyhovující, je předáno adaptivnímu klasifikátoru jako trénovací data. Adaptivní klasifikátor pak dostane šanci přesněji rozpoznat text níže na stránce. Protože se adaptivní klasifikátor mohl naučit něco užitečného příliš pozdě na to, aby mohl přispět v horní části stránky, je přes stránku spuštěn druhý průchod, ve kterém jsou slova, která nebyla dostatečně rozpoznána, znovu rozpoznána. Poslední fáze řeší fuzzy mezery a kontroluje alternativní hypotézy pro výšku x, aby se našel text s malými písmeny.
Tesseract ve své současné podobě je plně schopný unicode a trénován pro několik jazyků. Na základě našeho výzkumu je to jedna z nejpřesnějších open source knihoven dostupných pro OCR. Jak již bylo zmíněno dříve, Tesseract používá Leptonicu. K rozdělení souborů PDF na obrázky využíváme také Ghostscript. (Můžete se rozdělit do formátu komprese obrázků dle vašeho výběru; my jsme vybrali PNG.) Tyto tři knihovny jsou napsány v C++ a abychom je mohli vyvolat z programů Java/Scala, musíme použít implementace odpovídajících Java Native Interfaces. V naší práci používáme vazby JNI z JavaPresets. (Pokyny k sestavení naleznete níže.) K napsání ovladače Spark jsme použili Scala.
val renderer :SimpleRenderer =nové SimpleRenderer( )renderer.setResolution( 300 )val images:List[Image] =renderer.render( document )
Leptonica čte rozdělené obrázky z předchozího kroku.
ImageIO.write( x.asInstanceOf[RenderedImage], "png", imageByteStream)val pix:PIX =pixReadMem ( ByteBuffer.wrap( imageByteStream.toByteArray( ) ).array( ), ByteBuffer.wrap( imagetoByteStream. ) ).kapacita( ))
K extrakci textu pak použijeme volání Tesseract API. Předpokládáme, že dokumenty jsou zde v angličtině, proto druhý parametr metody Init je „eng.“
val api:TessBaseAPI =new TessBaseAPI( )api.Init( null, "eng" )api.SetImage(pix)api.GetUTF8Text().getString()
Po zpracování obrázků vyjmeme některá pole z textu a odešleme je do HBase.
def populateHbase ( fileName:String, lines:String, pdf:org.apache.spark.input.PortableDataStream) :Unit ={ /** Konfigurace a otevření připojení HBase */ val mddsTbl =_conn.getTable( TableName. valueOf( "mdds" )); val cf ="info" val put =new Put( Bytes.toBytes( název_souboru )) /** * Zde rozbalte pole pomocí regexů * Vytvořte objekty Put a odešlete do HBase */ val aAndCP ="""(?s)(? m).*\d\d\d\d\d-\d\d\d\d(.*)\nRe:(\w\d\d\d\d\d\d).*"" ".r …….. řádky odpovídají { case aAndCP( addr, casenum ) => put.add( Bytes.toBytes( cf ),Bytes.toBytes( "submitter_info" ),Bytes.toBytes( addr ) ).add( Bytes .toBytes( cf ),Bytes.toBytes( "číslo_případu" ), Bytes.toBytes(číslo_případu)) případ _ => println( "neodpovídá regulárnímu výrazu" ) } ……. lines.split("\n").foreach { val regNumRegex ="""Číslo předpisu:\s+(.+)""".r val regNameRegex ="""Název předpisu:\s+(.+)""" .r ……………. _ match { case regNumRegex( regNum ) => put.add( Bytes.toBytes( cf ),Bytes.toBytes( "reg_num" ), ……. ….. case _ => print( "" ) } } put.add ( Bytes.toBytes( cf ), Bytes.toBytes( "text" ), Bytes.toBytes( řádky)) val pdfBytes =pdf.toArray.clone put.add(Bytes.toBytes( "obj" ), Bytes.toBytes( " pdf" ), pdfBytes ) mddsTbl.put( put ) …….}
Pokud se podíváte pozorně na výše uvedený kód, těsně předtím, než odešleme objekt Put do HBase, vložíme nezpracované bajty PDF do rodiny sloupců „obj“ tabulky. HBase používáme jako úložnou vrstvu pro extrahovaná pole i nezpracovaný obraz. Díky tomu je aplikace extrahovat původní obrázek v případě potřeby rychle a pohodlně. Celý kód naleznete zde. (Stojí za zmínku, že zatímco jsme k vytváření objektů Put pro HBase používali standardní HBase API, ve skutečném produkčním systému by bylo moudré zvážit použití SparkOnHBase API, která umožňují dávkové aktualizace HBase z Spark RDD.)
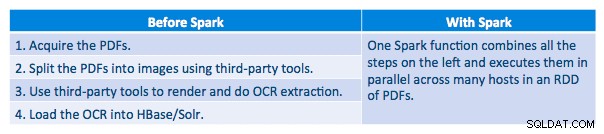
Prováděcí kanál
Dokázali jsme zpracovat každé PDF v sériovém rámci. Abychom škálovali zpracování, rozhodli jsme se zpracovat tyto PDF distribuovaným způsobem pomocí Spark. Následující graf ukazuje, jak kombinujeme různé fáze tohoto zpracování, abychom z pracovního postupu udělali jednoduché volání makra ze Sparku a načetli data do HBase.
Pokusili jsme se také provést srovnání mezi metodami serializace, ale s naší datovou sadou jsme nezaznamenali významný rozdíl ve výkonu.
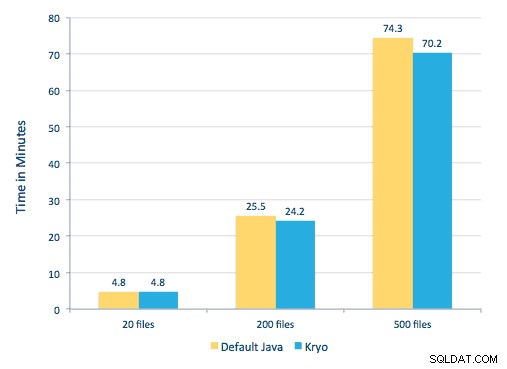
Nastavení prostředí
Použitý hardware:Pětiuzlový cluster s 15GB pamětí, 4 vCPU a 2x40GB SSD
Protože jsme pro zpracování používali knihovny C++, použili jsme vazby JNI, které lze nalézt zde.
Sestavte vazby JNI pro Tesseract a Leptonica z předvoleb javaCPP:
-
- Na všech uzlech:
yum -y install automake autoconf libtool zlib-devel libjpeg-devel giflib libtiff-devel libwebp libwebp-devel libicu-devel openjpeg-devel cairo-devel
git clone https://github.com/bytedeco/javacpp-presets.git cd javacpp-presets - Sestavit Leptonica.
cd leptonica./cppbuild.sh nainstalovat leptonicacd cppbuild/linux-x86_64/leptonica-1.72/LDFLAGS="-Wl,-rpath -Wl,/usr/local/lib" ./configuremake &&sudo make installcd ../../../mvn clean installcd ..
- Sestavte Tesseract.
cd tesseract./cppbuild.sh nainstalovat tesseractcd tesseract/cppbuild/linux-x86_64/tesseract-3.03LDFLAGS="-Wl,-rpath -Wl,/usr/local/lib" ./configuremake &&make installcd ./. ../../mvn clean installcd ..
- Vytvořte předvolby javaCPP.
mvn čistá instalace --projects leptonica,tesseract
K extrahování obrázků z PDF používáme Ghostscript. Pokyny pro sestavení Ghostscriptu, odpovídající zde použitým verzím Tesseract a Leptonica, jsou následující. (Ujistěte se, že Ghostscript není nainstalován v systému prostřednictvím správce balíčků.)
wget https://downloads.ghostscript.com/public/ghostscript-9.16.tar.gztar zxvf ghostscript-9.16.tar.gzcd ghostscript-9.16./autogen.sh &&./configure --prefix=/usr - -disable-compile-inits --enable-dynamicsudo make &&make soinstall &&install -v -m644 base/*.h /usr/include/ghostscript &&ln -v -s ghostscript /usr/include/ps(v závislosti na vaší ldpath nastavení, možná budete muset udělat):sudo ln -sf /usr/lib/libgs.so /usr/local/lib/libgs.so
Ujistěte se, že všechny potřebné knihovny jsou v cestě třídy. Všechny relevantní nádoby jsme umístili do adresáře s názvem lib. Níže je důležitá čárka:
$ for i v `ls lib/*`; do export MY_JARS=./$i,$MY_JARS; donetesseract.jar, tesseract-linux-x86_64.jar, javacpp.jar, ghost4j-1.0.0.jar, leptonica.jar, leptonica-1.72-1.0.jar, leptonica-linux-x86_64.jar
Program Spark vyvoláme následovně. Potřebujeme zadat extraLibraryPath pro nativní knihovny Ghostscript; druhý conf je potřeba pro Tesseract.
spark-submit --jars $MY_JARS --num-executors 12 --executor-memory 4G --executor-cores 1 --conf spark.executor.extraLibraryPath=/usr/local/lib --confspark.executorEnv. TESSDATA_PREFIX=/home/vsingh/javacpp-presets/tesseract/cppbuild/1-x86_64/share/tessdata/ --confspark.executor.extraClassPath=/etc/hbase/conf:/opt/cloudera/parcels/CDH/lib/hbase /lib/htrace-core-3.1.0-incubating.jar --driver-class-path/etc/hbase/conf:/opt/cloudera/parcels/CDH/lib/hbase/lib/htrace-core-3.1.0 -incubating.jar --conf spark.serializer=org.apache.spark.serializer.KryoSerializer--conf spark.kryoserializer.buffer.mb=24 --class com.cloudera.sa.OCR.IdmpExtraction
Vytvoření kolekce Solr
Solr se celkem hladce integruje s HBase přes Lily HBase Indexer. Chcete-li porozumět tomu, jak se provádí integrace Lily Indexer integrace s HBase, můžete si oprášit náš předchozí příspěvek v sekci „Porozumění replikaci HBase a Lily HBase Indexer“.
Níže uvádíme kroky, které je třeba provést k vytvoření indexů:
- Vygenerujte ukázkový konfigurační soubor schema.xml:
solrctl --zk localhost:2181 instancedir --generate $HOME/solrcfg
- Upravte soubor schema.xml v
$HOME/solrcfg , s uvedením polí, která potřebujeme pro naši kolekci. Celý soubor naleznete zde.
- Nahrajte konfigurace Solr do ZooKeeper:
solrctl --zk localhost:2181/solr instancedir --create mdds_collection $HOME/solrcfg
- Vygenerujte kolekci Solr se 2 střepy (-s 2) a 2 replikami (-r 2):
solrctl --zk localhost:2181/solr --solr localhost:8983/solr collection --create mdds_collection -s 2 -r 2
Ve výše uvedeném příkazu jsme vytvořili kolekci Solr se dvěma parametry (-s 2) a dvěma replikami (-r 2). Parametry byly pro náš korpus dostačující, ale ve skutečném nasazení by bylo nutné číslo nastavit na základě jiných úvah, které jsou mimo rozsah naší diskuse zde.
Registrace indexátoru
Tento krok je nutný k přidání a konfiguraci indexátoru a replikace HBase. Níže uvedený příkaz aktualizuje ZooKeeper a přidá mdds_indexer jako replikačního partnera pro HBase. Také vloží konfigurace do ZooKeeper, který Lily HBase Indexer použije k nasměrování na správnou kolekci v Solr. |
hbase-indexer add-indexer -n mdds_indexer -c indexer-config.xml -cp solr.zk=localhost:2181/solr -cp solr.collection=mdds_collection.
Argumenty:
-n mdds_indexer– určuje název indexátoru, který bude registrován v ZooKeeper-c indexer-config.xml– konfigurační soubor, který bude specifikovat chování indexeru-cp solr.zk=localhost:2181/solr– určuje umístění konfigurace ZooKeeper a Solr. Toto by mělo být aktualizováno s umístěním ZooKeeper pro konkrétní prostředí.-cp solr.collection=mdds_collection– určuje, která kolekce se má aktualizovat. Připomeňme si krok Konfigurace Solr, kde jsme vytvořili kolekci1.
Soubor index-config.xml soubor je v tomto případě poměrně jednoduchý; vše, co dělá, je specifikovat indexátoru, na kterou tabulku se má podívat, třídu, která bude použita jako mapovač (com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper ) a umístění konfiguračního souboru Morphline. Ve výchozím nastavení je typ mapování nastaven na řádek , v takovém případě se dokument Solr stane celým řádkem. Param name="morphlineFile" určuje umístění konfiguračního souboru Morphlines. Umístěním může být absolutní cesta vašeho souboru Morphlines, ale protože používáte Cloudera Manager, zadejte relativní cestu jako morphlines.conf.
Obsah konfiguračního souboru hbase-indexer naleznete zde.
Konfigurace a spuštění Lily HBase Indexer
Když povolíte Lily HBase Indexer, musíte zadat logiku transformace Morphlines, která umožní tomuto indexátoru analyzovat aktualizace tabulky Medical Device a extrahovat všechna relevantní pole. Přejděte na Služby a vyberte Lily HBase Indexer, který jste přidali dříve. Vyberte Konfigurace->Zobrazit a upravit->Široká služba->Morphlines . Zkopírujte a vložte soubor Morphlines.
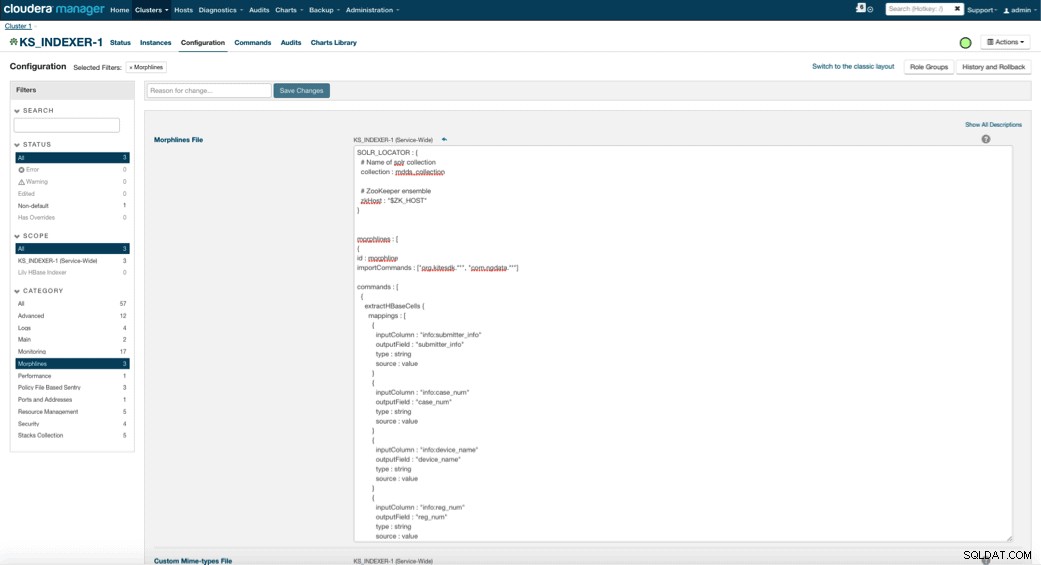
Knihovna morflinek lékařských přístrojů provede následující akce:
- Přečtěte si e-mailové události HBase pomocí
extractHBaseCellspříkaz - Převeďte data/časová razítka do pole, kterému bude Solr rozumět, pomocí
convertTimestamppříkazy - Zrušte všechna nadbytečná pole, která jsme nezadali ve schema.xml, pomocí
sanitizeUknownSolrFieldspříkaz
Stáhněte si kopii tohoto souboru Morphlines odtud.
Jedna důležitá poznámka je, že pole id bude automaticky generováno Lily HBase Indexer. Toto nastavení lze konfigurovat v souboru index-config.xml výše zadáním atributu unique-key-field. Osvědčeným postupem je ponechat výchozí název id – protože nebylo uvedeno ve výše uvedeném souboru xml, bylo vygenerováno výchozí pole id a bude kombinací RowID.
Přístup k datům
Pro přístup k indexovaným obrázkům máte na výběr z mnoha vizuálních nástrojů. HUE a Solr GUI jsou oba velmi dobré možnosti. HBase také umožňuje řadu přístupových technik, a to nejen z GUI, ale také přes HBase shell, API a dokonce i jednoduché techniky skriptování.
Integrace s Solr vám poskytuje velkou flexibilitu a může také poskytnout velmi jednoduché i pokročilé možnosti vyhledávání vašich dat. Například konfigurace souboru Solr schema.xml tak, aby všechna pole v rámci e-mailového objektu byla uložena v Solr, umožňuje uživatelům přístup k celému tělu zpráv pomocí jednoduchého vyhledávání s kompromisem mezi úložným prostorem a složitostí výpočtu. Alternativně můžete nakonfigurovat Solr tak, aby ukládal pouze omezený počet polí, jako je id. Pomocí těchto prvků mohou uživatelé rychle prohledat Solr a získat rowID, které lze zase použít k načtení jednotlivých polí nebo celého obrázku ze samotného HBase.
Výše uvedený příklad ukládá pouze rowID v Solr, ale indexuje všechna pole extrahovaná z obrázku. Hledání Solr v tomto scénáři načte ID řádků HBase, které pak můžete použít k dotazu na HBase. Tento typ nastavení je pro Solr ideální, protože udržuje nízké náklady na úložiště a plně využívá možnosti indexování Solr.
Ukázkové dotazy
Níže jsou uvedeny některé příklady dotazů, které lze provést z aplikace do Solr. Myšlenka je, že klient bude zpočátku dotazovat Solr indexy a vrátí rowID z HBase. Poté se dotazujte HBase na zbývající pole a/nebo původní nezpracovaný obraz.
- Dejte mi všechny dokumenty, které byly podány mezi následujícími daty:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=received:[2010-01 -06T23:59:59.999Z DO 2010-02-06T23:59:59.999Z]
- Dejte mi dokumenty, které byly podány pod regulačním názvem mobilních rentgenových systémů:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=reg_name:Mobile rentgenový systém
- Dejte mi všechny dokumenty, které byly podány od čínských výrobců:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=submitter_info:*Čína*
ID z dokumentů Solr jsou ID řádků v HBase; druhá část dotazu bude na HBase pro extrakci dat (včetně nezpracovaného PDF, je-li to požadováno).
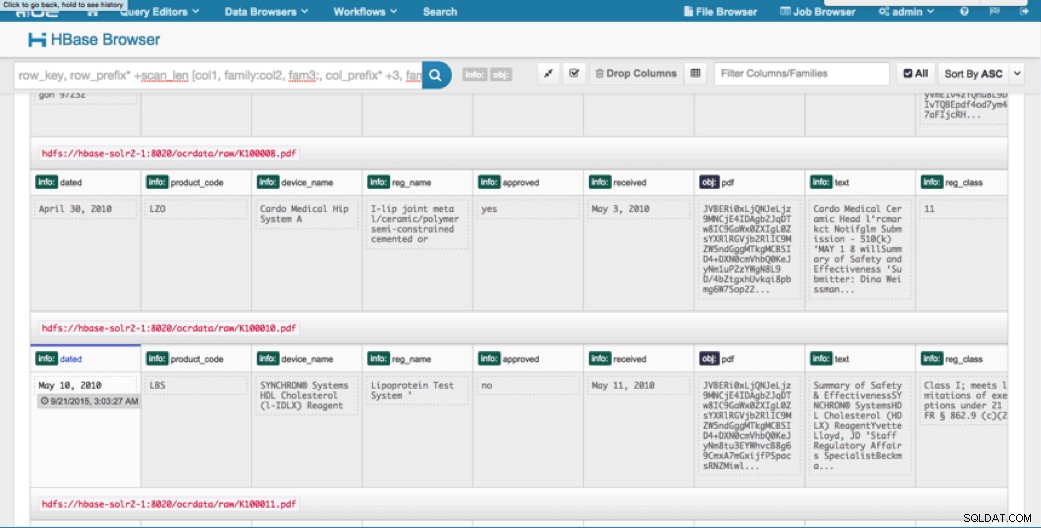
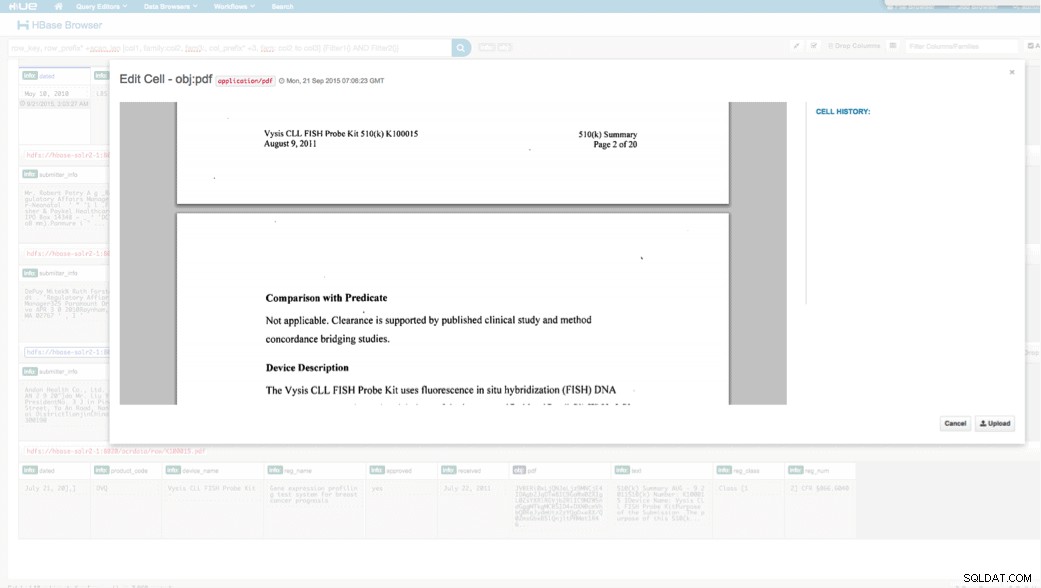
Přístup přes HUE
Nahraná data si můžeme prohlédnout přes HBase Browser v HUE. Jedna skvělá věc na HUE je, že dokáže detekovat binární soubory pro PDF a vykreslit je, když na ně kliknete.
Níže je snímek zobrazení analyzovaných polí v řádcích HBase a také vykreslený pohled na jeden z objektů PDF uložených jako MOB v rodině sloupců obj.
Závěr
V tomto příspěvku jsme ukázali, jak používat standardní technologie open source k provádění OCR na naskenovaných dokumentech pomocí škálovatelného programu Spark, ukládání do HBase pro rychlé vyhledávání a indexování extrahovaných informací v Solr. Mělo by být zřejmé, že:
- Vzhledem k formátu specifikace zprávy můžeme extrahovat pole a páry hodnot a umožnit jejich vyhledávání přes Solr.
- Tato pole dat mohou splňovat požadavky IDMP na elektronické zpracování starších dat, které vstoupí v platnost někdy v příštím roce.
- Pole i nezpracované obrázky lze uchovat v HBase a přistupovat k nim prostřednictvím standardních rozhraní API.
Pokud zjistíte, že potřebujete zpracovat naskenované dokumenty a zkombinovat data s různými dalšími zdroji ve vašem podniku, zvažte použití kombinace Spark, HBase, Solr spolu s Tesseract a Leptonica. Může vám to ušetřit značné množství času a peněz!
Jeff Shmain je senior Solution Architect ve společnosti Cloudera. Má více než 16 let zkušeností ve finančním odvětví se silnými znalostmi obchodování s cennými papíry, rizik a předpisů. Během několika posledních let pracoval na různých implementacích use case v 8 z 10 největších světových investičních bank.
Vartika Singh je Senior Solution Consultant ve společnosti Cloudera. Má více než 12 let zkušeností s aplikovaným strojovým učením a vývojem softwaru.