Přemýšlíte o něčem, když vytváříte novou databázi? Myslím, že většina z vás by řekla ne, protože všichni používáme výchozí parametry, i když zdaleka nejsou optimální. Existuje však spousta nastavení disku a skutečně pomáhají zvýšit spolehlivost a výkon systému.
Nebudeme hovořit o důležitosti souborového systému NTFS pro spolehlivost dat, i když tento souborový systém umožňuje MS SQL Server využívat disk tím nejefektivnějším způsobem.
Pokud máte nedostatek zdrojů a něco začíná fungovat pomalu, první věc, která vás napadne, je upgrade. Upgrade však není vyžadován ve všech případech. Můžete se zbavit ladění, i když by se nemělo provádět, když server začíná pomalu běžet, ale ve fázi návrhu a instalace.
Optimalizace je složitý proces a často souvisí nejen s určitým programem (v našem případě s určitou databází), ale také s OS a hardwarem. I když budeme většinou mluvit o databázích, nemůžeme ignorovat vnější věci.
Architektura dat
SQL Server ukládá, čte a zapisuje data po blocích po 8 KB. Tyto bloky se nazývají stránky. Databáze může uložit 128 stránek na megabajt (1 megabajt nebo 1048576 bajtů děleno 8 kilobajty nebo 8192 bajty). Všechny stránky jsou uloženy v rozsahu. Rozsah je posledních 8 po sobě jdoucích stránek nebo 64 kB. 1 megabajt tedy ukládá 16 oblastí.
Stránky a rozsahy jsou základem struktury fyzické databáze SQL Serveru. MS SQL Server používá různé typy stránek, některé sledují přidělený prostor, některé obsahují uživatelská data a indexy. Stránky, které sledují přidělený prostor, obsahují hustě komprimovaná data. Umožňuje MS SQL Server efektivně je uložit do paměti pro snadné čtení.
SQL Server používá dva druhy rozsahů:
- Rozsahy, které ukládají stránky dvou až mnoha objektů, se nazývají smíšené rozsahy. Každá tabulka začíná jako smíšený rozsah. Smíšený rozsah používáte hlavně pro stránky, které ukládají prostor a obsahují malé objekty.
- Rozsahy, které mají všech 8 stránek přidělených jednomu objektu, se nazývají jednotné oblasti. Používají se, když tabulka nebo index vyžaduje více než 64 kB.
První rozsah pro každý soubor je jednotný a obsahuje stránky hlavičky souboru, další rozsahy obsahují každý 3 přidělené stránky. Server přiděluje tyto smíšené rozsahy při vytváření základního datového souboru a používá tyto stránky pro své interní úlohy. Stránka záhlaví souboru obsahuje atributy souboru, jako je název databáze uložené v souboru, skupina souborů, minimální velikost, velikost přírůstku. Toto je první stránka každého souboru (strana 0).
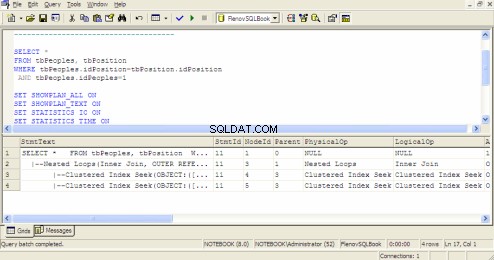
Plán provádění dotazů v SQL Query Analyzer
Místo volného místa (PFS ) na přidělené stránce, která obsahuje informace o volném místě dostupném v souboru. Tyto informace jsou uloženy na stránce 1. Každá taková stránka může mít až 8000 po sobě jdoucích stránek, což je přibližně 64 Mb dat.
Transakční protokol shromažďuje všechny informace o změnách probíhajících na serveru za účelem obnovení databáze v okamžiku systémové chyby a zajištění integrity dat.
Všimněte si, že všechna čísla jsou násobky 8 nebo 16. Je to proto, že řadič pevného disku čte data této velikosti snadněji. Data se z disku čtou po stránkách, tedy po 8 kilobajtech, což je celkem optimální hodnota.
Ochrana stránky
Od MS SQL Server 2005 nabízí databázový server novou možnost – řízení dat na úrovni stránky. Pokud AGE_VERIFY_CHECKSUM je povolen (ve výchozím nastavení povolen), server bude kontrolovat kontrolní součty stránek. Pokud se podíváme do manuálu pro tento parametr, uvidíme, že kontrolní součet umožňuje sledování vstupních/výstupních chyb, které OS není schopen sledovat. O jaké chyby se jedná? Zdá se, že jde o interní problémy databázového serveru.
Kontrola integrity dat nikdy neproběhne špatně, takže je lepší ji povolit. K tomu musíme provést následující příkaz:
ALTER DATABASE имя базы SET PAGE_VERIFY
Pokud je na stránce chyba, server nás na to upozorní. Ale jak to můžeme rychle napravit? K tomu existuje možnost obnovit data na úrovni stránky.
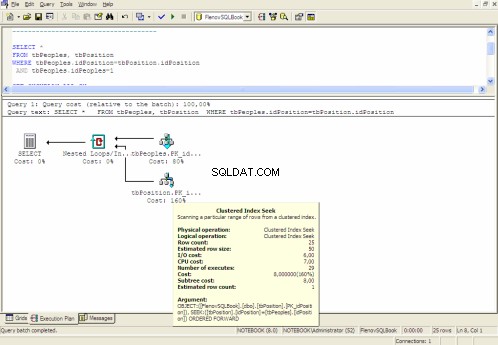
Grafický plán provádění
Růst souborů
Když vytváříme databázi, jsme vyzváni k výběru počáteční velikosti a metody přírůstku. Když máme nedostatek aktuálního prostoru, server jej rozšíří v souladu s přednastavenou metodou přírůstku.
Existují tři způsoby zvyšování souborů:
- Růst v megabajtech.
- Růst o procenta.
- Ruční růst.
První dvě metody se provádějí automaticky, ale doporučují se pouze pro testovací databáze, protože administrátor nemá kontrolu nad velikostí souboru.
Pokud je soubor navýšen o určité množství megabajtů, může se v určitém okamžiku zvýšit rychlost vkládání dat a růst souboru může být příliš častý, což představuje dodatečné náklady. Růst souborů v procentech je také nerentabilní. Doporučuje se použít 10% nárůst souboru a to je v pořádku pro malé a střední databáze. Ale když dosáhne 1000 gigabajtů, bude vyžadovat 100 gigabajtů při každém růstu. Povede to ke zbytečnému plýtvání místem na disku.
Vždy kontrolujte změny velikosti souborů a protokolů transakcí. Umožní vám využívat zdroje disku nejefektivnějším způsobem.
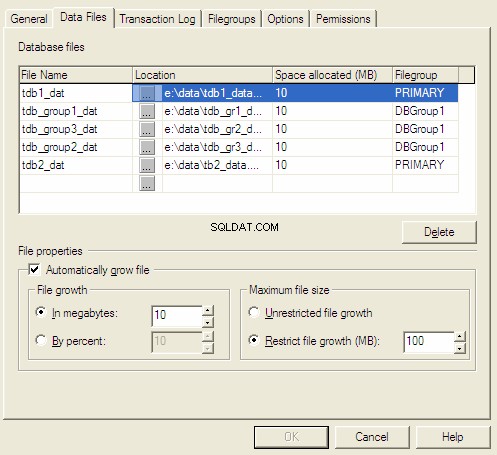
Vlastnosti databáze MS SQL Server
Komprese dat
Pevný disk zůstává rozumným místem počítače. Výkon procesorů strmě roste, zatímco pevné disky nemohou nabídnout něco nového. Chcete-li ušetřit počet operací vstupu/výstupu a snížit objem dat uložených na pevném disku, můžete použít disky s kompresí. Pouze takové disky jsou vhodné pro ukládání skupin souborů pouze pro čtení. Možná je to proto, že pro zápisy je vyžadována komprese a vyžaduje dodatečné náklady na procesor.
Komprese dat a stav pouze pro čtení jsou dobré pro archivní data. Například účetní data za minulé roky nejsou pro zápis potřeba a mohou zabírat příliš mnoho místa. Umístěním dat do archivní části disku výrazně ušetříte místo.
Disky pro spolehlivost
Následující metoda umožňuje zvýšení spolehlivosti a výkonu zároveň a opět se týká pevných disků. No, tady to je, mechanika je nejen nejpomalejší, ale také nejspolehlivější. Co se týče spolehlivosti, statistiky jsem nesbíral, ale doma i v práci se zabývám převážně pevnými disky.
Pro zvýšení výkonu a spolehlivosti tedy můžete jednoduše použít dva nebo více pevných disků místo jednoho. Ještě lepší bude, když budou připojeny k samostatným ovladačům. Databázi můžete uložit na jeden disk a protokoly transakcí na jiný. Pokud existuje třetí disk, může uložit systém.
Ukládání dat a logu na samostatné disky umožňuje výrazně zvýšit spolehlivost. Předpokládejme, že máte vše na jednom disku a spadne. Co dělat? Můžete oslovit firmu, která se pokusí vše vymoci nebo se o totéž pokusí na vlastní pěst, ale šance na vymáhání zdaleka není 100 %. Kromě toho může návrat serveru zpět do práce zabrat značné množství času. Rychlé obnovení lze provést pouze do okamžiku poslední záložní kopie. Zbytek je sporný.
A nyní předpokládejme, že máte data a protokol transakcí na různých discích. Pokud se disk s logem vypne, data tam budou stále. Jediná věc je, že nemůžete přidávat nová data, ale pokud vytvoříte nový protokol, můžete pokračovat v práci.
Pokud dojde k výpadku disku s daty, stále můžeme rezervovat transakční protokol, abychom zabránili nejmenší ztrátě dat. Poté obnovíme data z kompletní zálohy (to by mělo být provedeno vždy předem, dobrý správce to dělá alespoň jednou denně) a přidáme změny ze záložní kopie protokolu.
Disky pro výkon
Pokud jsou data a protokol umístěny na samostatných discích, znamená to nejen bezpečnost, ale i růst výkonu. Jde o to, že databázový server může současně zapisovat data do logu a datového souboru.
Můžeme jít dále a přidělit jeden pevný disk protokolu transakcí a několik pevných disků datům. Server pracuje s daty častěji, proto vyžaduje několik úložišť, se kterými můžete pracovat současně. A pokud jsou tato úložiště připojena k různým ovladačům, je zaručena současná práce.
Nejrychlejší a nejspolehlivější variantou je použití RAID . Ne však každý RAID je spolehlivý a rychlý zároveň. Pro skupiny souborů se doporučuje zvolit RAID10 , protože obsahuje dobře vyvážené funkce, ale v závislosti na datech databáze si můžete vybrat jinou variantu.
Jako RAID můžete použít softwarové nebo hardwarové řešení . Softwarové řešení je levnější, ale vyžaduje další zdroje CPU. A procesor nemá náhradní zdroje. Proto je lepší používat hardwarová řešení, kde je za RAID zodpovědný dedikovaný čip .
Indexy
Každý ví, že indexy pomáhají zvýšit rychlost vyhledávání dat. Většina z nás chápe, že indexy negativně ovlivňují vkládání a aktualizaci dat, takže čím více indexů máte, tím je pro server těžší je udržovat. Mnoho z nich si přitom ani nemyslí, že indexy vyžadují údržbu. Databázové stránky obsahující data indexu mohou přetékat a nakonec se stát nevyváženými.
Ano, můžeme ignorovat různé parametry a jednoduše znovu vytvořit indexy jednou za měsíc, což je podobné údržbě. SQL Server obsahuje dva parametry, které zabraňují tomu, aby indexy zastaraly do půl hodiny po jejich vytvoření:FILLFACTOR a PAD_INDEX .
Pomocí volby FILLFACTOR můžete optimalizovat výkon operací vkládání a aktualizace, které obsahují klastrovaný nebo neklastrovaný index. Indexová data mohou být uložena na mnoha datových stránkách. Jak jsem uvedl výše, každá stránka má 8 KB. Když je stránka indexu plná, server vytvoří novou stránku a rozdělí stránku pro vložení dat na dvě.
Server potřebuje čas na rozdělení stránky a vytvoření nové stránky. Chcete-li optimalizovat rozdělení stránky, použijte FILLFACTOR možnost určit procento volného místa na všech listech stránky indexu. Čím větší místo na disku mají stránky na úrovni listu, tím méně často budete muset indexové stránky dělit. V tomto případě bude strom indexu příliš velký a jeho obejití bude trvat déle.
PAD_INDEX volba udává procento naplnění nelistových stránek. Můžete použít PAD_INDEX pouze při FILLFACTOR možnost je zadaná, protože procentuální hodnota PAD_INDEX závisí na procentu zadaném v FILLFACTOR .
Statistiky
Statistiky umožňují serveru učinit správné rozhodnutí mezi použitím indexu a úplným skenováním tabulky. Předpokládejme, že máte seznam zaměstnanců slévárny. Takový seznam bude tvořit přibližně 90 % mužů.
Předpokládejme, že musíme najít všechny ženy. Vzhledem k tomu, že jich není mnoho, bude nejúčinnější možností použití indexu. Ale pokud potřebujeme najít všechny muže, účinnost indexu se zpomalí. Počet vybraných záznamů je příliš velký a obcházení indexového stromu pro každý z nich bude představovat režii. Je mnohem jednodušší skenovat celou tabulku – provádění bude mnohem rychlejší, protože server bude muset jednou přečíst všechny nízkoúrovňové listy indexu, aniž by potřeboval vícenásobné čtení všech úrovní.
SQL Server shromažďuje statistiky čtením všech hodnot polí nebo pomocí šablony pro vytvoření jednotně distribuovaného a setříděného seznamu hodnot. SQL Server dynamicky zjišťuje procento řádků, které je třeba testovat, na základě počtu řádků v tabulce. Při shromažďování statistik optimalizátor dotazů provede buď úplné skenování, nebo šablony řádků.
Aby statistiky fungovaly, musí být vytvořeny. V případě masivní aktualizace dat mohou statistiky obsahovat nesprávná data a server učiní chybné rozhodnutí. Ale vše se dá napravit, – je potřeba sledovat statistiky. Podrobnější informace naleznete v knihách o Transact-SQL nebo MS SQL Server.
Shrnutí
Výchozí nastavení neumožňuje využít veškerý potenciál hardwaru a pracovat s nejrůznějšími servery. Odpovědnost za nastavení spočívá na správcích. Skutečnost, že produkty Microsoftu mají jednoduché instalační programy, grafické administrační nástroje a možnost práce offline, neznamená, že se jedná o optimální variantu.
Takové možnosti ladění databáze nepovažujeme za hardwarovou akceleraci. Pokud jsou vyčerpány všechny možnosti ladění, je lepší přemýšlet o upgradu, protože hardwarová akcelerace negativně ovlivňuje spolehlivost systému.
Nejdůležitější je, že žádná optimalizace databázového serveru nebo upgrade nepomůže, pokud dotazy nebudou optimalizovány.