Systém správy databází je schránkou informací. Pokusíme se navrhnout Systém správy databází tak, aby databáze zůstala dobře spravovaná a plnila své účely.
V tomto článku se budeme zabývat návrhem a správou rozsáhlých databázových systémů. Použijeme několik konstitucí, které budou zahrnovat databázové technologie, úložiště, distribuci dat, serverové prostředky, architekturu a některé další.
Přednostně bychom měli hledat rozsáhlou databázi v oblasti Telco, eCommerce platforem, Pojišťovnictví, Bankovní systém, Zdravotnictví, Energetický systém atd. Před výběrem správné databázové technologie musíme mít na paměti několik parametrů. tj. provoz, TPS (Transactions Per Second), odhadované úložiště za den, HA a DR.
Návrh velké databáze
Při konstrukci naší databáze musíme věnovat pozornost několika parametrům, protože výměna databáze za náhradu je často velmi problematická. Pojďme je nyní zvážit.
Technologie databáze
Databázová technologie je primárním faktorem. Pokud zvolíte správný systém správy databází, pomůže vašemu podnikání efektivně a bez námahy.
Existují různé databázové technologie s mnoha funkcemi. Při práci s open source databázovými technologiemi však nemusíte získat přístup k některým explicitním funkcím předdefinovaných řešení. Poskytovaly by je podnikové databázové technologie jako Microsoft SQL Server, Oracle atd.
Mnoho podnikových databázových technologií implementuje HA (High Availability), DR (Disaster Recovery), zrcadlení, replikaci dat, sekundární čtení repliky a podstatně pohodlnější a připravenější konfigurovatelná obchodní řešení. Mohou nebo nemusí být přítomny v databázích s otevřeným zdrojovým kódem.
Důvodů je spousta. Někdy například zjistíme, že stávající architektura je narušena, protože výše uvedené faktory nefungují tak, jak bychom je potřebovali.
Úložiště
Úložiště drasticky ovlivňuje výkon obchodního řešení. Podniková řešení vyžadují prvotřídní úložiště nebo SSD s určitým IOPS. Nicméně, je tomu tak? On-premise nebo Cloud, velikost a typ úložiště určují náklady na infrastrukturu.
Při zvažování výkonu úložiště musíme věnovat pozornost typu dat a chování při zpracování dat. Musíme se rozhodnout pro výběr úložiště podle údajů uživatele a jejich zpracování. Pokud uživatel bude používat více databází, musíme pro různé databáze poskytnout výběr úložiště přes SAN pro typy dat a chování při zpracování dat.
Databázový inženýr poskytne lepší retrospektivu různých databází potřebných pro výpočet IOPS, pokud uživatelé vůbec nepotřebují prémiové úložiště.
Distribuce dat
Většina současných databázových technologií (SQL nebo NoSQL) nabízí funkce dělení nebo sdílení.
- Oddíl přerozděluje data v systému souborů, který je založen na klíči oddílu.
- Sharding distribuuje informace mezi uzly databáze a data by byla uložena na stejném nebo jiném počítači.
Každá databázová služba nebo databázová tabulka v zásadě nebude vyžadovat funkce dělení/sharding dat. Je třeba je aplikovat pouze na databáze obsahující objekty větší velikosti. To zvýší výkon.
Prostředky serveru
Různé stroje vyžadují různé typy a velikosti paměti a CPU. Musíte vzít v úvahu aktiva na úrovni hardwaru, jako je paměť, procesor atd. Například stroj, který musí zpracovávat větší databáze nebo více databází, bude potřebovat více paměti a CPU. Kvalita paměti a procesoru je tedy důležitá. Bude pracovat s různými typy procesorů dostupných na trhu s různými mezipaměti CPU.
Mnohokrát narazíme na problémy, o kterých nemusíme vědět. Nevěnovali jsme pozornost využití a roli CPU cache hardwaru. Je však zásadní pro výběr a splnění hardwarových požadavků u větších databázových systémů.
Vzor architektury
Při navrhování databází má vzor architektury vždy příkladnou roli. Dříve byly databázové systémy navrhovány extrémně monolitickým způsobem. Nyní používáme Micro-Service based nebo Hybrid (Monolithic + Micro).
Výkon, rozšiřitelnost a nulové prostoje velmi závisí na vzoru architektury a návrhu databáze. Každá aplikace může mít samostatnou databázi a všechny databáze mohou být vzájemně volně propojeny. V případě výpadku jakékoli aplikace nebo databáze nebude narušena další část produktu. Všechny mikroslužby by byly nezávislé a volně propojené.
Mikroslužba
Níže uvedený diagram vysvětluje, jak se všechny aplikace nasazují a komunikují pomocí svých databází, které jsou zároveň volně propojené. S daty můžeme manipulovat pomocí T-SQL. Informace budou shromažďovány nebo shromažďovány různými aplikacemi a klient bude mít k datům přístup. Podívejte se na diagram s počtem škálovaných aplikací a jejich integrovanou databází.
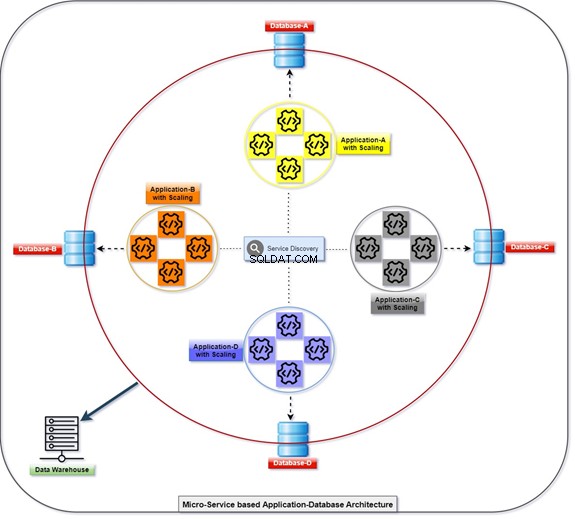
Monolitický
Které RDBMS bychom měli použít? Může to být Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB nebo jakákoli jiná databáze. Konvenční způsob zacházení se všemi tabulkami nebo objekty spravovanými v jedné nebo více databázích na jediném serveru se nazývá monolitický.
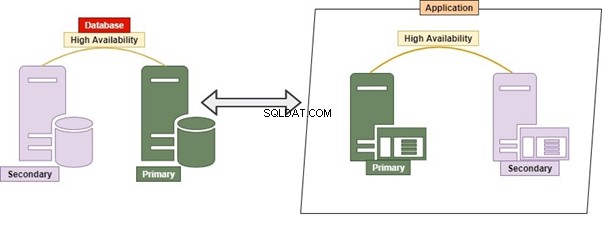
Hybridní
Hybrid je permutací Monolithic a Micro Service. Je to docela běžná praxe, protože umožňuje mnoho aplikací, mnoho databází a databázových serverů. Četné databáze a databázové servery by mohly být vzájemně těsně propojeny.
Například dotazování pomocí JOIN mezi tabulkami, které patří ke dvěma nebo více databázím na stejném databázovém serveru nebo různým. Vzdálený dotaz používaný pro získávání dat/manipulaci s jiným databázovým serverem.
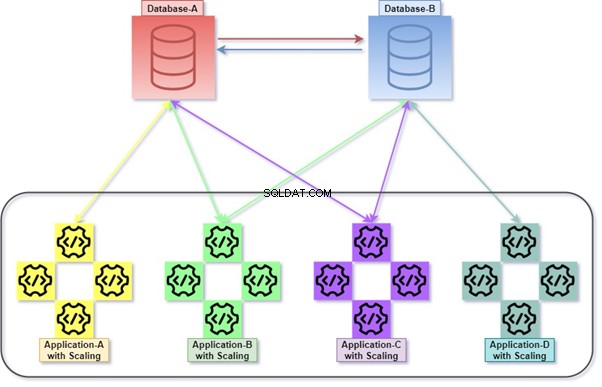
Vše je o architektuře SQL Serveru. Hovoříme však o manipulaci s daty mezi různými tabulkami ve stejné databázi nebo různými databázemi, které by mohly být umístěny na stejném serveru nebo na různých serverech.
Buď v hybridní nebo monolitické architektuře používáme JOINy mezi různými tabulkami v rámci stejné nebo různých databází. Je to docela složité, když se řídíme základními standardy Micro-Service, protože distribuce tabulek může být mezi databázovými službami (Dbas).
V rámci podnikových databázových technologií, jako je Microsoft SQL Server, Oracle atd., mohl uživatel dotazovat tabulky distribuované databáze pomocí Linked Server Joins. Není však k dispozici ve všech open-source databázových technologiích. Je známý jako přístup v těsném spojení, který nemusí fungovat, když služba vzdálené databáze není dostupná.
Nyní pojďme diskutovat o tom, jak to udělat volně spojené. Proč potřebujeme manipulaci s daty mezi vzdálenými databázemi?
Proč vyžadujeme manipulaci s daty mezi vzdálenými databázemi?
Uživatelé budou vyžadovat, aby byla data načtena z více než jedné databázové služby, pokud je systém navržen s pomocí Micro nebo Hybrid Services. Celý proces je vidět z backendu, který dokáže zpracovat množství dat manipulovaných aplikací.
Když se podíváme na dotazování napříč databázemi v reálném čase, vždy spojujeme hlavní tabulky entit, nikoli tabulky metadat. Hlavní tabulky nebudou větší než tabulky metadat. Pro účely reportování vždy používáme datový sklad, abychom získali všechny informace dohromady. Ale to není snadné spravovat a udržovat pro každý produkt. Pokud navrhneme podnikové řešení, můžeme si dovolit sklad. Ale nemůžeme si to dovolit u malých nebo středně velkých produktů.
Potřebujeme například sestavu s daty z několika tabulek umístěných v různých databázích. Není to snadný úkol, protože shromažďuje data pomocí různých mikroslužeb a spojuje je do sestavy. Potřebná data je proto třeba synchronizovat.
Co můžeme použít jako standardní řešení provést synchronizaci dat volně vázané tabulky mezi dvěma databázemi?
Replikace tabulky by se měla používat pro jednoduchou synchronizaci dat mezi více databázemi. Příkladem je transakční replikace pro Simplexní synchronizaci dat a Merge Replication pro Duplexní synchronizaci dat poskytovaná SQL Serverem.
Existuje několik placených řešení třetích stran a open-source řešení, která dokážou synchronizovat data mezi více databázemi. Dokonce i volně propojená řešení s pomocí front zpráv, jako je SQL Server Transaction Replication, mohou uživatelé vyvíjet sami.
Závěr
DBA navrhují databáze svým způsobem. Při navrhování databáze a výběru systému správy databáze musí mít na paměti mnoho aspektů. Uvedli jsme nejdůležitější faktory pro návrh databáze, zejména u databází větší velikosti. Zůstaňte naladěni na další materiály!