Spark začal žít v roce 2009 jako projekt v rámci AMPLab na University of California, Berkeley. Přesněji řečeno, zrodil se z nutnosti dokázat koncept Mesos, který byl také vytvořen v AMPLab. Spark byl poprvé diskutován v bílé knize Mesos s názvem Mesos:Platforma pro jemné sdílení zdrojů v datovém centru, kterou napsali především Benjamin Hindman a Matei Zaharia.
Ukázalo se to jako rychlé a pohodlné řešení pro provádění komplexní analýzy rozsáhlých dat. Spark se vyvinul jako nový rámec pro zpracování velkých dat, který řeší mnoho nedostatků v modelu MapReduce. Podporuje analýzu dat ve velkém měřítku a data mohou pocházet z různých zdrojů, jako je reálný čas, dávkové zpracování v různých formátech, jako jsou obrázky, texty, grafy a mnoho dalších. Kromě jádra Apache Spark poskytuje také užitečnou sadu knihoven pro analýzu velkých dat.
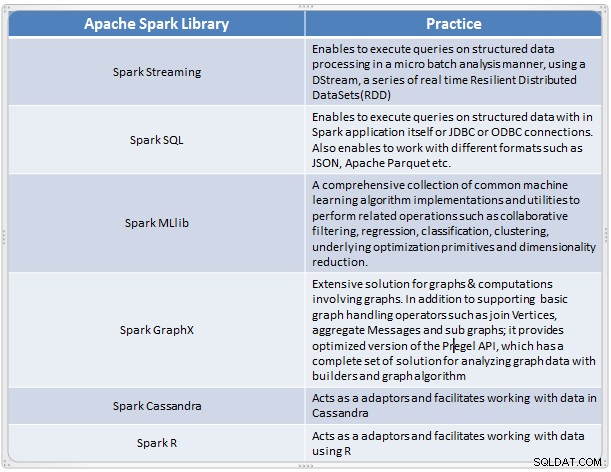
Přehled komponent Spark
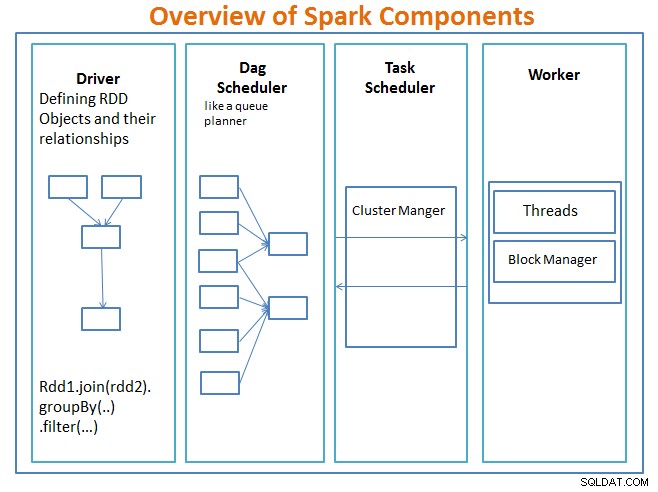
Řidič je kód, který obsahuje hlavní funkci a definuje odolné distribuované datové sady (RDD) a jejich transformace. RDD jsou hlavní datové struktury, které budou použity v našich programech Spark.
Paralelní operace na RDD jsou odesílány do Plánovače DAG , která optimalizuje kód a dospěje k efektivnímu DAG, který představuje kroky zpracování dat v aplikaci.
Výsledný DAG je odeslán do správce clusteru a správce clusteru má informace o pracovnících, přiřazených vláknech a umístění datových bloků a je zodpovědný za přiřazení konkrétních úloh zpracování pracovníkům. Zvládá také paly zpět v případě selhání pracovníka. Správcem clusteru může být YARN, Mesos, správce clusteru Spark.
pracovník přijímá jednotky práce a data ke správě a pracovník provádí svůj konkrétní úkol bez znalosti celého DAG a jeho výsledky jsou odesílány zpět do aplikací ovladače.
Spark, stejně jako ostatní nástroje pro velká data, je výkonný, schopný a dobře se hodí k řešení řady problémů s daty. Spark, stejně jako jiné technologie velkých dat, není nutně tou nejlepší volbou pro každý úkol zpracování dat.
V části 2 – budeme diskutovat o základech konceptů Spark, jako jsou odolné distribuované datové sady, sdílené proměnné, SparkContext, transformace, akce , a výhody použití Spark spolu s příklady a kdy použít Spark.
Odkaz:
Naučte se jiskru za den od Acodemy &Hadoop Applications Architectures.