IRI nyní také poskytuje funkce fuzzy vyhledávání, a to jak ve svých bezplatných databázích a nástrojích pro profilování plochých souborů, tak jako dostupné knihovny funkcí v poli v IRI CoSort, FieldShield a Voracity pro zvýšení kvality dat, zabezpečení a možností MDM. Toto je první ze série článků o fuzzy vyhledávacích řešeních IRI, které pokrývají jejich aplikaci na zlepšování kvality dat.
Úvod
Pravdivost nebo spolehlivost dat jednoho z velkých slov „V“ (spolu s objemem, rozmanitostí, rychlostí a hodnotou), o kterých IRI a další mluví v kontextu správy dat a podnikových informací. Obecně IRI definuje pochybná data jako data s jedním nebo více z těchto atributů:
- Nízká kvalita, protože je nekonzistentní, nepřesná nebo neúplná
- Nejednoznačné (předpokládejme MDM), nepřesné (nestrukturované) nebo klamavé (sociální média)
- Zaujaté (otázka v průzkumu), hlučné (nadbytečné nebo kontaminované) nebo abnormální (odlehlé hodnoty)
- Neplatné z jakéhokoli jiného důvodu (jsou údaje správné a přesné pro zamýšlené použití?)
- Nebezpečné – obsahuje PII nebo tajemství a je to správně maskované, vratné atd.?
Tento článek se zaměřuje pouze na nová řešení fuzzy hledání prvního problému, kvality dat. Jiné články v tomto blogu pojednávají o tom, jak software IRI řeší další čtyři problémy s pravdivostí; pokud nemůžete, požádejte o pomoc při jejich nalezení.
O Fuzzy Search
Fuzzy vyhledávání najde slova nebo fráze (hodnoty), které jsou podobné, ale ne nutně totožné s jinými slovy nebo frázemi (hodnotami). Tento typ vyhledávání má mnoho využití, jako je hledání sekvenčních chyb, pravopisných chyb, transponovaných znaků a další, kterým se budeme věnovat později.
Provádění fuzzy vyhledávání přibližných slov nebo frází může pomoci najít data, která mohou být duplikáty dříve uložených dat. Uživatelský vstup nebo automatická oprava však mohla data nějakým způsobem pozměnit, aby záznamy vypadaly nezávisle.
Zbytek článku se bude zabývat čtyřmi funkcemi fuzzy vyhledávání, které IRI nyní podporuje, jak je používat k prohledávání dat a vracet tyto záznamy přibližně s hodnotou vyhledávání.
1. Levenshteina
Levenshteinův algoritmus funguje tak, že vezme dvě slova nebo fráze a počítá, kolik kroků úprav bude potřeba k přeměně jednoho slova nebo fráze na druhé. Čím méně kroků bude potřeba, tím pravděpodobnější bude shoda slova nebo fráze. Kroky, které může funkce Levenshtein provést, jsou:
- Vložení znaku do slova nebo fráze
- Odstranění znaku ze slova nebo fráze
- Nahrazení jednoho znaku ve slově nebo frázi jiným
Následuje program CoSort SortCL (skript úlohy), který ukazuje, jak používat Levenshteinovu funkci fuzzy vyhledávání:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
K vytvoření požadovaného výstupu je třeba použít dvě části.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Tento řádek volá funkci fs_levenshtein a ukládá výsledek do pole FS_RESULT. Funkce přebírá dva vstupní parametry:
- Pole pro spuštění fuzzy vyhledávání (v našem příkladu NAME)
- Řetězec, se kterým bude vstupní pole porovnáno (v našem příkladu „Barney Oakley“)
/INCLUDE WHERE FS_RESULT GT 50
Tento řádek porovnává pole FS_RESULT a zkontroluje, zda je větší než 50, pak jsou na výstupu pouze záznamy s FS_RESULT větším než 50. Následující text ukazuje výstup z našeho příkladu.

Jak ukazuje výstup, tento typ vyhledávání je užitečný pro nalezení:
- Zřetězená jména
- Hluk
- Pravopisné chyby
- Transponované znaky
- Chyby v přepisu
- Typové chyby
Funkce Levenshtein je tedy užitečná také pro identifikaci běžných chyb při zadávání dat. Provedení ze čtyř algoritmů však trvá nejdéle, protože porovnává každý znak v jednom řetězci s každým znakem v druhém.
2. Koeficient kostky
Koeficient kostky, neboli algoritmus kostky, rozděluje slova nebo fráze do dvojic znaků, porovnává tyto dvojice a počítá shody. Čím více se slova shodují, tím je pravděpodobnější, že se slovo shoduje.
Následující skript SortCL demonstruje funkci fuzzy vyhledávání koeficientu kostky.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
K získání požadovaného výstupu je třeba použít dvě části.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Tento řádek volá funkci fs_dice a ukládá výsledek do pole FS_RESULT. Funkce přebírá dva vstupní parametry:
- Pole, na kterém se má spustit fuzzy vyhledávání (v našem příkladu NAME).
- Řetězec, se kterým bude vstupní pole porovnáno (v našem příkladu „Robert Thomas Smith“).
/INCLUDE WHERE FS_RESULT GT 50
Tento řádek porovnává pole FS_RESULT a zkontroluje, zda je větší než 50, pak jsou na výstupu pouze záznamy s FS_RESULT větším než 50. Následující text ukazuje výstup z našeho příkladu.
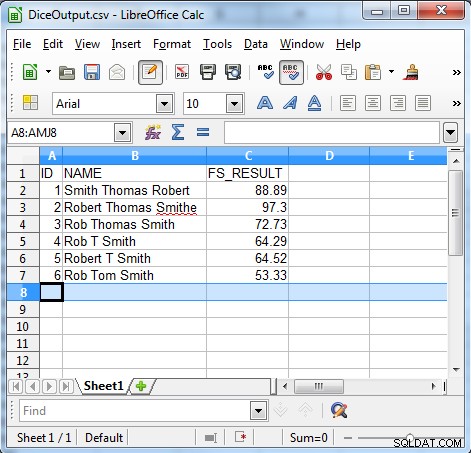
Jak ukazuje výstup, algoritmus koeficientu kostek je užitečný pro hledání nekonzistentních dat, jako jsou:
- Chyby sekvence
- Nedobrovolné opravy
- Přezdívky
- Iniciály a přezdívky
- Nepředvídatelné použití iniciál
- Lokalizace
Algoritmus kostek je rychlejší než Levenshtein, ale může být méně přesný, pokud se vyskytuje mnoho jednoduchých chyb, jako jsou překlepy.
3. Metafon a 4. Soundex
Algoritmy Metaphone a Soundex porovnávají slova nebo fráze na základě jejich fonetických zvuků. Soundex to dělá tak, že čte slovo nebo frázi a dívá se na jednotlivé postavy, zatímco Metaphone se dívá na jednotlivé postavy i skupiny postav. Oba pak poskytnou kódy na základě pravopisu a výslovnosti slova.
Následující skript SortCL demonstruje funkce vyhledávání Soundex a Metasphone:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
V každém případě existují tři části, které musí být použity, abychom získali požadovaný výstup.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
Řádek zavolá funkci a uloží výsledek do pole VÝSLEDEK. Obě funkce mají dva vstupní parametry:
- Pole pro spuštění fuzzy vyhledávání (v našem příkladu NAME)
- Xtring, se kterým bude vstupní pole porovnáno (v našem příkladu „Jan“)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Tento řádek porovnává pole SE_RESULT a MP_RESULT a zkontroluje a vrátí řádek, pokud je kterýkoli z nich větší než 0.
Soundex vrátí buď 100 pro shodu, nebo 0, pokud se nejedná o shodu. Metaphone má konkrétnější výsledky a vrací 100 pro silnou shodu, 66 pro normální shodu a 33 pro menší shodu.
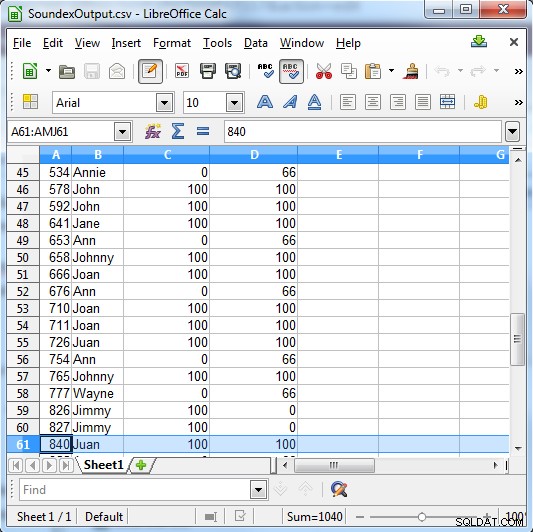
Sloupec C ukazuje výsledky Soundex. Csloupec D zobrazuje výsledky Metaphone
Jak ukazuje výstup, tento typ vyhledávání je užitečný pro nalezení:
- Fonetické chyby
Odešlete zpětnou vazbu k tomuto článku níže a pokud máte zájem o používání těchto funkcí, kontaktujte svého zástupce IRI. Viz náš další článek o použití těchto algoritmů v průvodci konsolidací dat (kvalita) IRI Workbench.