Pozadí
Jedna z prvních věcí, na kterou se dívám, když řeším problém s výkonem, je statistika čekání prostřednictvím sys.dm_os_wait_stats DMV. Abych zjistil, na co SQL Server čeká, používám dotaz z aktuální sady diagnostických dotazů SQL Server od Glenna Berryho. V závislosti na výstupu začnu kopat do konkrétních oblastí v rámci SQL Server.
Například, pokud vidím vysoké čekání CXPACKET, zkontroluji počet jader na serveru, počet uzlů NUMA a hodnoty pro maximální stupeň paralelismu a prahovou hodnotu nákladů pro paralelismus. Toto jsou základní informace, které používám k pochopení konfigurace. Než vůbec uvažuji o provedení jakýchkoli změn, shromáždím další kvantitativní data, protože systém s čekáním CXPACKET nemusí mít nutně nesprávné nastavení maximálního stupně paralelismu.
Podobně systém, který má vysoké čekání na typy čekání související s I/O, jako jsou PAGEIOLATCH_XX, WRITELOG a IO_COMPLETION, nemusí mít nutně horší úložný subsystém. Když vidím typy čekání související s I/O jako horní čekání, okamžitě chci porozumět více o základním úložišti. Je to přímo připojené úložiště nebo SAN? Jaká je úroveň RAID, kolik disků je v poli a jaká je rychlost disků? Také chci vědět, zda úložiště sdílejí jiné soubory nebo databáze. A i když je důležité porozumět konfiguraci, dalším logickým krokem je podívat se na statistiky virtuálních souborů prostřednictvím DMV sys.dm_io_virtual_file_stats.
Tento DMV, představený v SQL Server 2005, je náhradou za funkci fn_virtualfilestats, kterou ti z vás, kteří používali SQL Server 2000 a starší, pravděpodobně znají a milují. DMV obsahuje kumulativní I/O informace pro každý databázový soubor, ale data se resetují při restartu instance, když je databáze uzavřena, přepnuta do režimu offline, odpojena a znovu připojena atd. Je důležité pochopit, že data statistik virtuálních souborů nepředstavují aktuální performance – je to snímek, který je agregací I/O dat od posledního vymazání jednou z výše uvedených událostí. I když data nejsou v určitém okamžiku, mohou být stále užitečná. Pokud nejvyšší čekání na instanci souvisí s I/O, ale průměrná doba čekání je menší než 10 ms, úložiště pravděpodobně nepředstavuje problém – ale korelace výstupu s tím, co vidíte v sys.dm_io_virtual_stats, stále stojí za potvrzení nízké hodnoty. latence. Navíc, i když v sys.dm_io_virtual_stats vidíte vysoké latence, stále jste neprokázali, že úložiště je problém.
Nastavení
Abych se podíval na statistiky virtuálních souborů, nastavil jsem dvě kopie databáze AdventureWorks2012, kterou si můžete stáhnout z Codeplex. Pro první kopii, dále známou jako EX_AdventureWorks2012, jsem spustil skript Jonathana Kehayiase, abych rozšířil tabulky Sales.SalesOrderHeader a Sales.SalesOrderDetail na 1,2 milionu, respektive 4,9 milionu řádků. Pro druhou databázi, BIG_AdventureWorks2012, jsem použil skript z mého předchozího rozdělovacího příspěvku k vytvoření kopie tabulky Sales.SalesOrderHeader se 123 miliony řádků. Obě databáze byly uloženy na externím USB disku (Seagate Slim 500 GB) s tempdb na mém místním disku (SSD).
Před testováním jsem v každé databázi vytvořil čtyři vlastní uložené procedury (Create_Custom_SPs.zip), které by mi sloužily jako „běžná“ zátěž. Můj testovací proces byl pro každou databázi následující:
- Restartujte instanci.
- Zachyťte statistiky virtuálních souborů.
- Spusťte „normální“ zátěž po dobu dvou minut (postupy se opakovaně volají prostřednictvím skriptu PowerShell).
- Zachyťte statistiky virtuálních souborů.
- Znovu vytvořte všechny indexy pro příslušné tabulky SalesOrder.
- Zachyťte statistiky virtuálních souborů.
Data
Abych zachytil statistiky virtuálních souborů, vytvořil jsem tabulku s historickými informacemi a poté jsem pro snímek použil variantu dotazu Jimmyho Maye z jeho skriptu DMV All-Stars:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Restartoval jsem instanci a poté okamžitě zachytil statistiky souborů. Když jsem filtroval výstup, abych zobrazil pouze databázové soubory EX_AdventureWorks2012 a tempdb, byla zachycena pouze data tempdb, protože z databáze EX_AdventureWorks2012 nebyla požadována žádná data:

Výstup z počátečního zachycení sys.dm_os_virtual_file_stats
Poté jsem na dvě minuty spustil „normální“ pracovní zatížení (počet spuštění každé uložené procedury se mírně lišil) a poté znovu dokončil statistiky zachycených souborů:

Výstup ze sys.dm_os_virtual_file_stats po normální zátěži
U datového souboru EX_AdventureWorks2012 vidíme latenci 57 ms. Ne ideální, ale časem by se to při mém běžném vytížení asi srovnalo. Pro tempdb je minimální latence, což se očekává, protože pracovní zátěž, kterou jsem spustil, negeneruje mnoho aktivity tempdb. Dále jsem přestavěl všechny indexy pro tabulky Sales.SalesOrderHeaderEnlarged a Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Přestavby trvaly méně než minutu a všimněte si prudkého nárůstu latence čtení u datového souboru EX_AdventureWorks2012 a prudkého nárůstu latence zápisu u dat EX_AdventureWorks2012 a soubory protokolu:

Výstup ze sys.dm_os_virtual_file_stats po opětovném sestavení indexu
Podle toho snímku statistik souborů je latence hrozná; více než 600 ms pro zápisy! Pokud bych viděl tuto hodnotu pro produkční systém, bylo by snadné okamžitě podezřívat problémy s úložištěm. Je však také třeba poznamenat, že AvgBPerWrite se také zvýšil a dokončení zápisů větších bloků trvá déle. Zvýšení AvgBPerWrite se očekává u úlohy obnovy indexu.
Pochopte, že když se podíváte na tato data, nezískáte úplný obrázek. Lepším způsobem, jak se podívat na latence pomocí statistik virtuálních souborů, je pořídit snímky a poté vypočítat latenci za uplynulé časové období. Skript níže například používá dva snímky (aktuální a předchozí) a poté vypočítá počet přečtení a zápisů v daném časovém období, rozdíl hodnot io_stall_read_ms a io_stall_write_ms a poté vydělí rozdíl io_stall_read_ms počtem přečtení a rozdíl io_stall_write_ms počet zápisů. Pomocí této metody vypočítáme dobu, po kterou SQL Server čekal na I/O na čtení nebo zápis, a poté ji vydělíme počtem čtení nebo zápisů, abychom určili latenci.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Když to provedeme pro výpočet latence během přestavby indexu, dostaneme následující:

Latence vypočtená ze sys.dm_io_virtual_file_stats během přestavby indexu pro EX2_Adventure em>
Nyní vidíme, že skutečná latence během té doby byla vysoká – což bychom očekávali. A pokud bychom se poté vrátili k běžné zátěži a několik hodin ji spustili, průměrné hodnoty vypočítané ze statistik virtuálních souborů by se časem snižovaly. Ve skutečnosti, když se podíváme na data PerfMon, která byla zachycena během testu (a poté zpracována prostřednictvím PAL), vidíme výrazné skoky v prům. Disk s/čtení a prům. Disk sec/Write, která koreluje s časem, kdy probíhalo nové sestavení indexu. Ale jindy jsou hodnoty latence hluboko pod přijatelnými hodnotami:
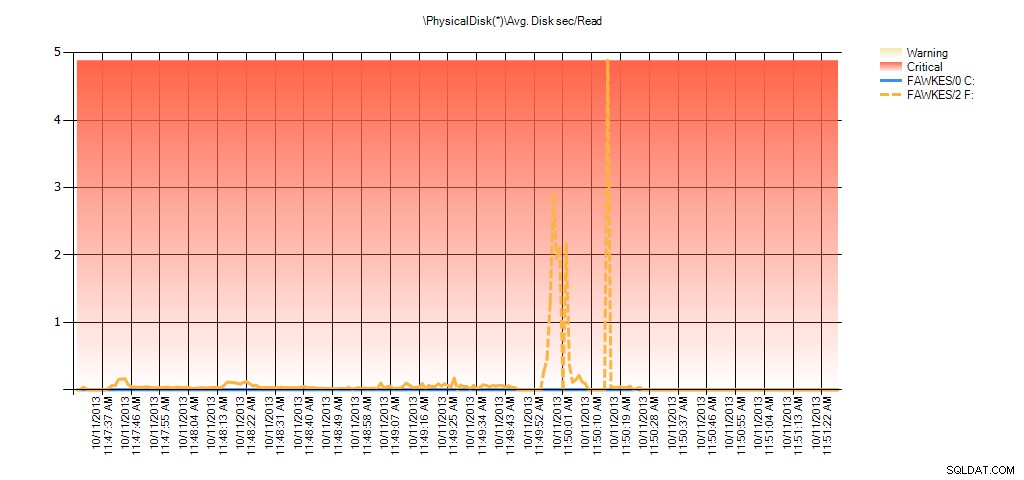
Shrnutí prům. diskových sekund/čtení z PAL pro EX_AdventureWorks2012 během testování
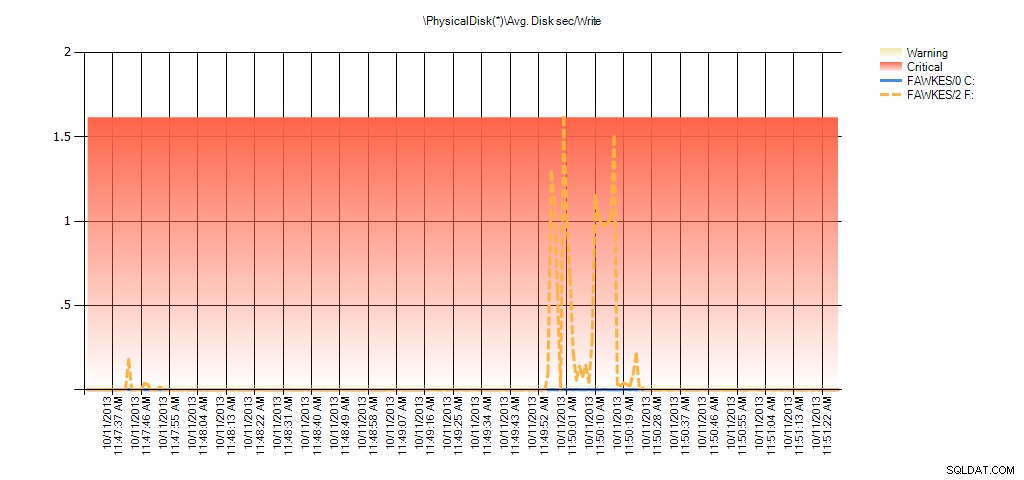
Shrnutí průměrného disku Sec/zápis z PAL pro EX_AdventureWorks2012 během testování
Stejné chování můžete vidět u databáze BIG_AdventureWorks 2012. Zde jsou informace o latenci založené na snímku statistik virtuálních souborů před přestavbou indexu a po:

Latence vypočtená ze sys.dm_io_virtual_file_stats během přestavby indexu pro BIGs212 em>
A data sledování výkonu ukazují stejné špičky během přestavby:
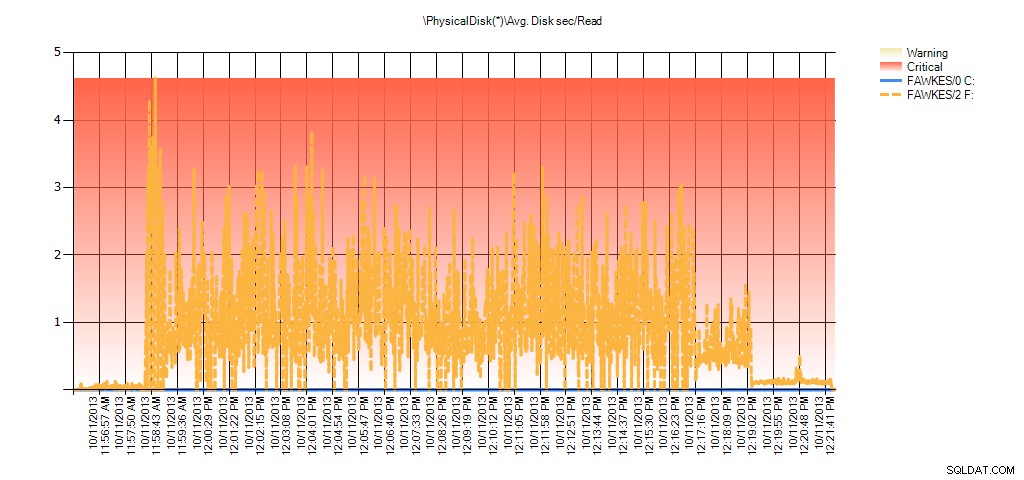
Shrnutí průměrného disku Sec/přečtení z PAL pro BIG_AdventureWorks2012 během testování
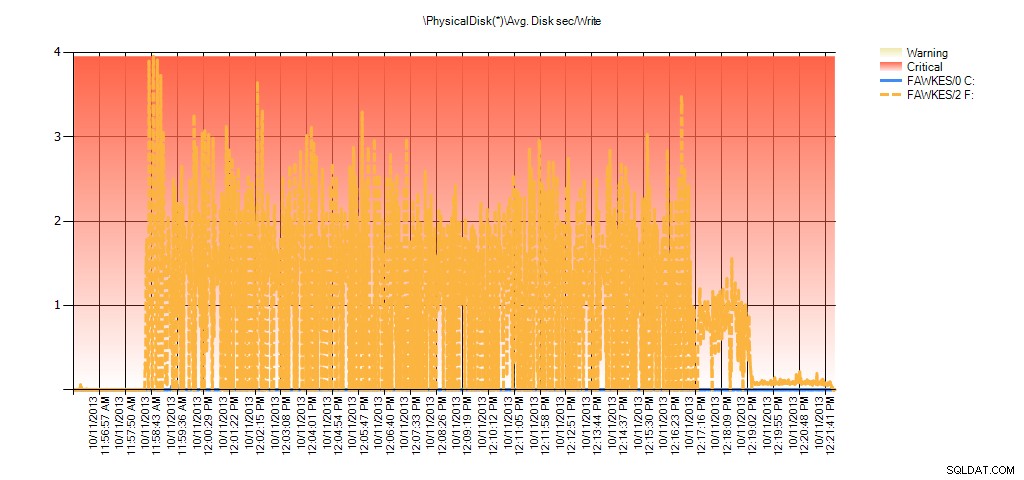
Shrnutí prům. disk Sec/zápis z PAL pro BIG_AdventureWorks2012 během testování
Závěr
Statistiky virtuálních souborů jsou skvělým výchozím bodem, když chcete pochopit výkon I/O pro instanci SQL Server. Pokud při pohledu na statistiku čekání vidíte čekání související s I/O, je logickým dalším krokem pohled na sys.dm_io_virtual_file_stats. Mějte však na paměti, že data, která si prohlížíte, jsou agregáty od posledního vymazání statistik jednou z přidružených událostí (restart instance, offline databáze atd.). Pokud vidíte nízké latence, pak I/O subsystém drží krok s výkonnostní zátěží. Pokud však vidíte vysoké latence, není samozřejmé, že úložiště je problém. Chcete-li skutečně vědět, co se děje, můžete začít snímat statistiky souborů, jak je znázorněno zde, nebo můžete jednoduše použít nástroj Performance Monitor a podívat se na latenci v reálném čase. Je velmi snadné vytvořit sadu kolekcí dat v PerfMon, která zachycuje čítače fyzického disku Avg. Sek./čtení disku a prům. Disk Sec/Read pro všechny disky, které hostí databázové soubory. Naplánujte pravidelné spouštění a zastavování sběrače dat a vzorkujte každé n sekund (např. 15), a jakmile zachytíte data PerfMon na vhodnou dobu, spusťte je přes PAL, abyste prozkoumali latenci v průběhu času.
Pokud zjistíte, že k latenci I/O dochází během vaší běžné pracovní zátěže, a nejen během úkolů údržby, které pohánějí I/O, stále nemůže ukazovat na úložiště jako základní problém. Latence úložiště může existovat z různých důvodů, například:
- SQL Server musí číst příliš mnoho dat v důsledku neefektivních plánů dotazů nebo chybějících indexů
- Instanci je přiděleno příliš málo paměti a stejná data se čtou z disku znovu a znovu, protože nemohou zůstat v paměti
- Implicitní převody způsobují prohledávání indexů nebo tabulek
- Pokud nejsou vyžadovány všechny sloupce, dotazy provádějí SELECT *.
- Problémy s předávaným záznamem v haldách způsobují další I/O
- Nízká hustota stránek způsobená fragmentací indexu, rozdělením stránek nebo nesprávným nastavením faktoru vyplnění způsobuje další I/O
Bez ohledu na hlavní příčinu je důležité pochopit výkon – zejména pokud jde o I/O –, že jen zřídka existuje jeden datový bod, který můžete použít k určení problému. Nalezení skutečného problému vyžaduje několik faktů, které vám po poskládání pomohou problém odhalit.
Nakonec si uvědomte, že v některých případech může být latence úložiště zcela přijatelná. Než budete požadovat rychlejší úložiště nebo změny kódu, prohlédněte si vzory zátěže a smlouvu o úrovni služeb (SLA) pro databázi. V případě datového skladu, který poskytuje zprávy uživatelům, není SLA pro dotazy pravděpodobně stejné hodnoty za sekundu, jaké byste očekávali u velkoobjemového systému OLTP. V řešení DW mohou být I/O latence větší než jedna sekunda naprosto přijatelné a očekávané. Pochopte očekávání firmy a jejích uživatelů a poté určete, jaké kroky, pokud vůbec nějaké, podniknout. A pokud jsou nutné změny, shromážděte kvantitativní data, která potřebujete k podpoře svého argumentu, konkrétně statistiky čekání, statistiky virtuálních souborů a latence z nástroje Performance Monitor.