Minulý rok jsem zveřejnil tip nazvaný Zlepšit efektivitu serveru SQL přechodem na spouštěče.
Velký důvod, proč mám tendenci upřednostňovat místo spouštěče, zejména v případech, kdy očekávám mnoho porušení obchodní logiky, je ten, že se zdá intuitivní, že by bylo levnější akci zabránit úplně, než ji provést (a log it!), pouze k použití spouštěče AFTER k odstranění problematických řádků (nebo vrácení celé operace zpět). Výsledky uvedené v tomto tipu ukázaly, že tomu tak ve skutečnosti bylo – a mám podezření, že by byly ještě výraznější s více neseskupenými indexy ovlivněnými operací.
Bylo to však na pomalém disku a na raném CTP serveru SQL Server 2014. Při přípravě snímku pro novou prezentaci, kterou budu letos dělat o spouštěčích, jsem zjistil, že na novějším sestavení SQL Server 2014 – v kombinaci s aktualizovaným hardwarem – bylo trochu složitější demonstrovat stejný rozdíl ve výkonu mezi spouštěčem AFTER a MÍSTO spouště. Tak jsem se vydal zjistit proč, i když jsem okamžitě věděl, že to bude více práce, než jsem kdy udělal pro jeden snímek.
Jedna věc, kterou chci zmínit, je, že spouštěče mohou používat tempdb různými způsoby, a to může vysvětlovat některé z těchto rozdílů. Spouštěč AFTER používá úložiště verzí pro vložené a odstraněné pseudotabulky, zatímco spouštěč NAMÍSTO OF vytvoří kopii těchto dat v interní pracovní tabulce. Rozdíl je nepatrný, ale stojí za zmínku.
Proměnné
Budu testovat různé scénáře, včetně:
- Tři různé spouštěče:
- Spouštěč AFTER, který odstraní konkrétní řádky, které selžou
- Spouštěč AFTER, který vrátí celou transakci zpět, pokud některý řádek selže
- MÍSTO spouštěče, který vloží pouze řádky, které projdou
- Různé modely obnovy a nastavení izolace snímků:
- FULL s povoleným SNAPSHOT
- FULL s deaktivovaným SNAPSHOT
- JEDNODUCHÉ s povoleným SNAPSHOT
- JEDNODUCHÉ s deaktivovaným SNAPSHOT
- Různá rozložení disku*:
- Data na SSD, přihlášení na HDD 7200 RPM
- Data na SSD, přihlášení na SSD
- Data na 7200 RPM HDD, přihlaste se na SSD
- Data na 7200 RPM HDD, přihlášení na 7200 RPM HDD
- Různá míra selhání:
- 10%, 25% a 50% míra selhání v:
- Vložení jedné dávky o 20 000 řádcích
- 10 dávek po 2 000 řádcích
- 100 dávek po 200 řádcích
- 1 000 dávek po 20 řádcích
- 20 000 samostatných vložek
*
tempdbje jeden datový soubor na pomalém disku se 7200 otáčkami za minutu. Toto je záměrné a má za cíl umocnit případná úzká hrdla způsobená různými způsoby použitítempdb. Plánuji znovu navštívit tento test v určitém okamžiku, kdytempdbje na rychlejším SSD. - 10%, 25% a 50% míra selhání v:
Dobře, TL;DR již!
Pokud chcete znát výsledky, přeskočte dolů. Vše uprostřed je pouze pozadí a vysvětlení toho, jak jsem nastavil a provedl testy. Není mi smutno z toho, že ne všechny budou zajímat všechny detaily.
Scénář
Pro tuto konkrétní sadu testů je scénář v reálném životě takový, kdy si uživatel vybere přezdívku a spouštěč je navržen tak, aby zachytil případy, kdy zvolené jméno porušuje některá pravidla. Například to nemůže být žádná variace "ninny-muggins" (tady jistě můžete zapojit svou fantazii).
Vytvořil jsem tabulku s 20 000 jedinečnými uživatelskými jmény:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Pak jsem vytvořil tabulku, která by byla zdrojem mých „zlobivých jmen“, s nimiž je lze porovnávat. V tomto případě je to jen ninny-muggins-00001 přes ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Tyto tabulky jsem vytvořil v model databáze, takže pokaždé, když vytvořím databázi, bude existovat lokálně a plánuji vytvořit spoustu databází k testování výše uvedené matice scénářů (spíše než jen změnit nastavení databáze, vymazat protokol atd.). Upozorňujeme, že pokud v modelu vytváříte objekty pro testovací účely, ujistěte se, že jste je po dokončení odstranili.
Kromě toho z toho úmyslně vynechám porušování klíčů a další zpracování chyb, čímž vycházím z naivního předpokladu, že jedinečnost zvoleného názvu je zkontrolována dlouho předtím, než dojde k pokusu o vložení, ale v rámci stejné transakce (stejně jako kontrola proti neposlušné tabulce jmen mohla být provedena předem).
Abych to podpořil, vytvořil jsem také následující tři téměř identické tabulky v model , pro účely izolace testu:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
A následující tři spouštěče, jeden pro každou tabulku:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Pravděpodobně budete chtít zvážit další manipulaci, abyste uživatele upozornili, že jeho volba byla vrácena zpět nebo ignorována – ale i to je pro zjednodušení vynecháno.
Nastavení testu
Vytvořil jsem ukázková data představující tři míry selhání, které jsem chtěl otestovat, změnil jsem 10 procent na 25 a poté na 50 a přidal jsem tyto tabulky také do model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Každá tabulka má 20 000 řádků s různým mixem názvů, které projdou a neuspějí, a sloupec s číslem řádku usnadňuje rozdělení dat do různých velikostí dávek pro různé testy, ale s opakovatelnou mírou selhání pro všechny testy.
Samozřejmě potřebujeme místo pro zachycení výsledků. Rozhodl jsem se k tomu použít samostatnou databázi, každý test jsem spustil vícekrát, jednoduše zachytil dobu trvání.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Vyplnil jsem dbo.Tests tabulku s následujícím skriptem, abych mohl spustit různé části pro nastavení čtyř databází tak, aby odpovídaly aktuálním testovacím parametrům. Všimněte si, že D:\ je SSD, zatímco G:\ je disk 7200 RPM:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Pak bylo jednoduché spustit všechny testy vícekrát:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
Na mém systému to trvalo téměř 6 hodin, takže buďte připraveni nechat to běžet bez přerušení. Také se ujistěte, že proti model nemáte otevřená žádná aktivní připojení nebo okna dotazů databáze, jinak se při pokusu skriptu o vytvoření databáze může zobrazit tato chyba:
Nelze získat exkluzivní zámek na databázi 'model'. Opakujte operaci později.
Výsledky
Existuje mnoho datových bodů, na které se můžete podívat (a všechny dotazy použité k odvození dat jsou uvedeny v příloze). Mějte na paměti, že každé zde uvedené průměrné trvání je více než 10 testů a vkládá do cílové tabulky celkem 100 000 řádků.
Graf 1 – Celkové souhrny
První graf ukazuje celkové agregace (průměrnou dobu trvání) pro různé proměnné izolovaně (takže *všechny* testy používají spouštěč AFTER, který smaže, *všechny* testy používají spouštěč AFTER, který se vrací atd.).
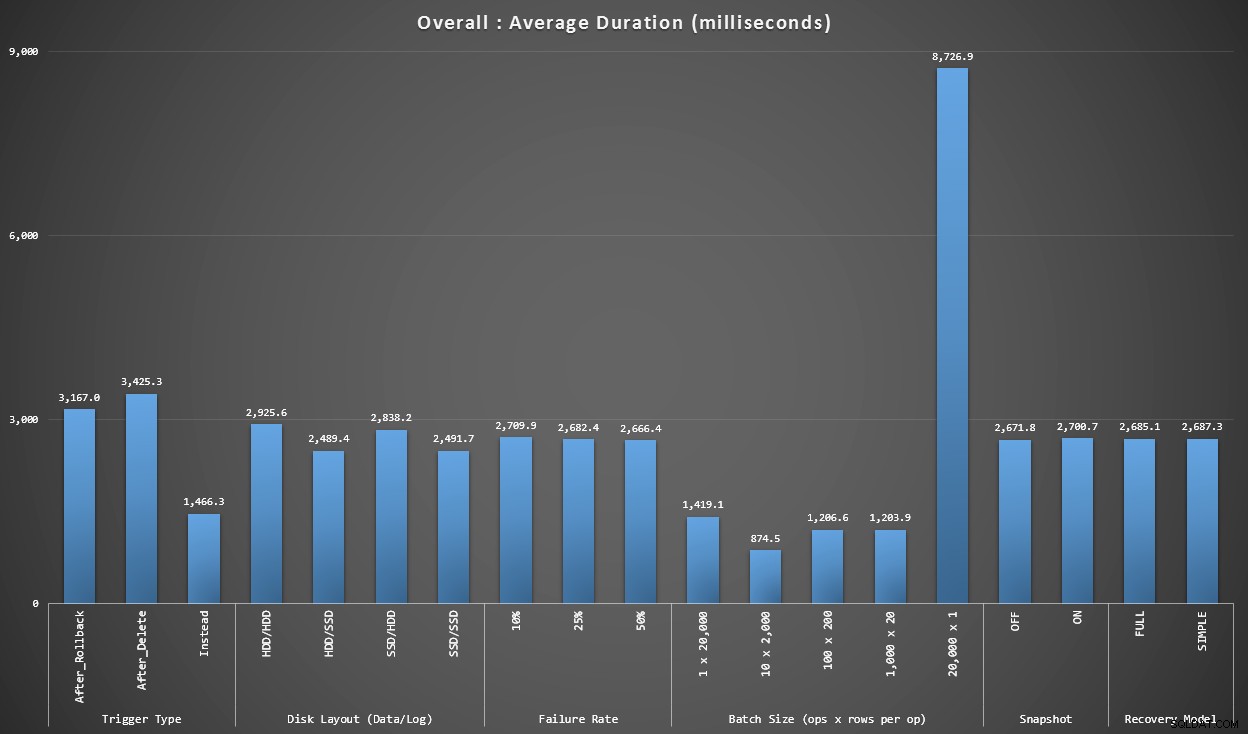
Průměrná doba trvání v milisekundách pro každou proměnnou izolovaně
Okamžitě nám vyskočí několik věcí:
- Spouštěč NAMÍSTO OF je zde dvakrát rychlejší než oba spouštěče PO.
- Mít protokol transakcí na SSD trochu změnilo. Umístění datového souboru mnohem méně.
- Šarže 20 000 samostatných vložek byla 7–8x pomalejší než jakákoli jiná distribuce šarží.
- Jedna dávková vložka o 20 000 řádcích byla pomalejší než kterákoli z distribucí bez jediného typu.
- Četnost selhání, izolace snímku a model obnovy měly malý, pokud vůbec žádný dopad na výkon.
Graf 2 – 10 nejlepších celkově
Tento graf ukazuje 10 nejrychlejších výsledků, když se vezme v úvahu každá proměnná. To vše jsou MÍSTO spouštěčů, kde selže největší procento řádků (50 %). Překvapivě ten nejrychlejší (i když ne o moc) měl data i přihlášení na stejném HDD (ne SSD). Je zde směs rozvržení disků a modelů obnovy, ale všech 10 mělo povolenou izolaci snímků a všech 7 nejlepších výsledků zahrnovalo velikost dávky 10 x 2 000 řádků.
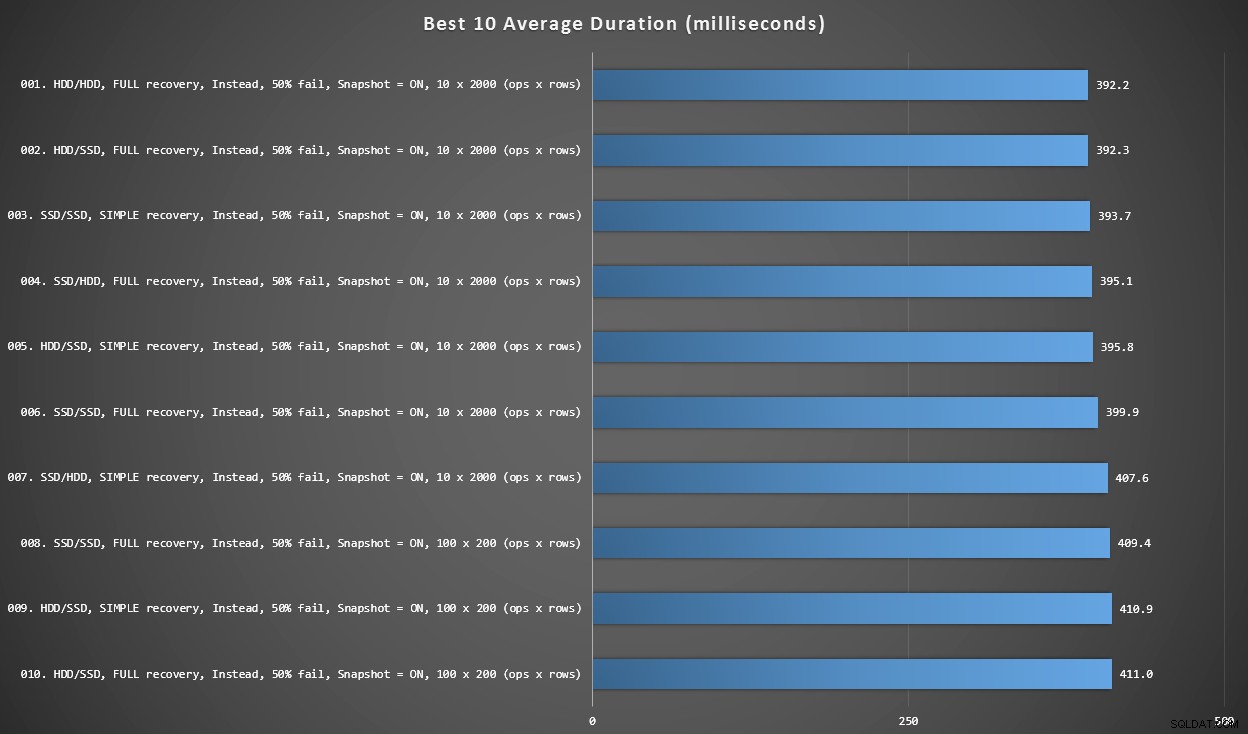
Nejlepších 10 trvání, v milisekundách, s ohledem na každou proměnnou
Nejrychlejší spoušť AFTER – varianta ROLLBACK s 10% chybovostí ve velikosti dávky 100 x 200 řádků – byla na pozici #144 (806 ms).
Graf 3 – celkově nejhorších 10
Tento graf ukazuje 10 nejpomalejších výsledků, když se vezme v úvahu každá proměnná; všechny jsou varianty AFTER, všechny zahrnují 20 000 singletonových vložek a všechny mají data a přihlášení na stejném pomalém HDD.
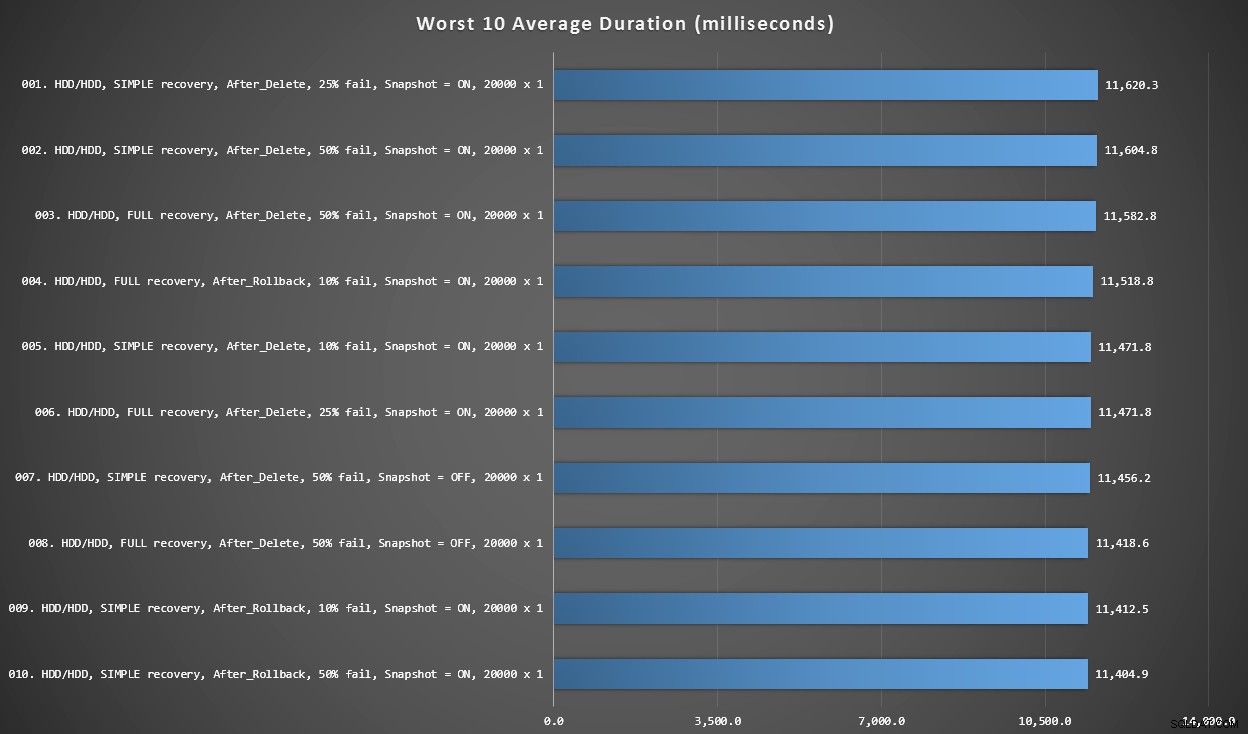
Nejhorších 10 trvání, v milisekundách, s ohledem na každou proměnnou
Nejpomalejší test MÍSTO byl na pozici #97, při 5 680 ms – test 20 000 singletonových vložek, kde 10 % selhalo. Je také zajímavé pozorovat, že ani jeden spouštěč AFTER s použitím velikosti dávky 20 000 singletonových vložek nedopadl lépe – ve skutečnosti 96. nejhorším výsledkem byl test AFTER (delete), který přišel za 10 219 ms – téměř dvojnásobek dalšího nejpomalejšího výsledku.
Graf 4 – Typ disku protokolu, jednotlivé vložky
Výše uvedené grafy nám dávají přibližnou představu o největších bolestivých bodech, ale buď jsou příliš přiblížené, nebo nejsou přiblíženy dostatečně. Tento graf se filtruje až na data založená na skutečnosti:ve většině případů bude tento typ operace představovat singletonovou vložku. Myslel jsem, že to rozdělím podle poruchovosti a typu disku, na kterém je protokol, ale podívejte se pouze na řádky, kde je dávka tvořena 20 000 jednotlivými vložkami.
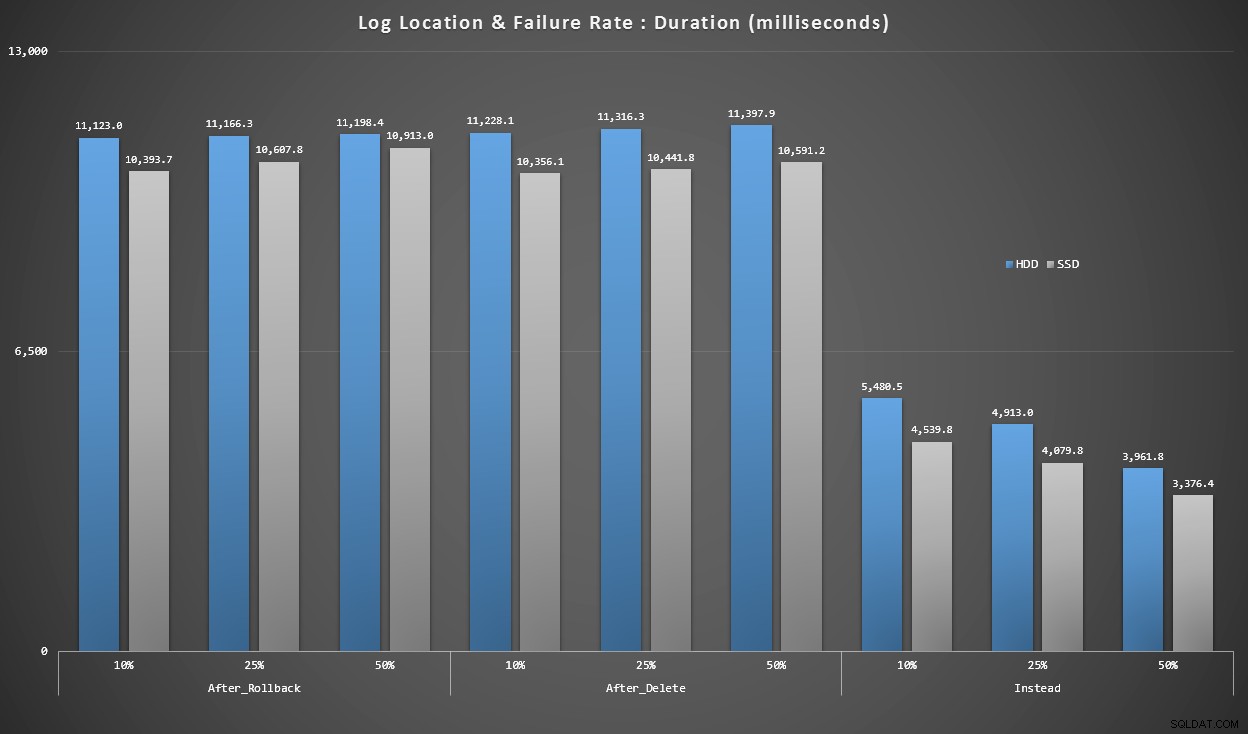
Trvání v milisekundách, seskupené podle míry selhání a umístění protokolu, za 20 000 jednotlivých vložkí
Zde vidíme, že všechny spouštěče AFTER jsou v průměru v rozsahu 10-11 sekund (v závislosti na umístění protokolu), zatímco všechny spouštěče NAMÍSTO OF jsou hluboko pod značkou 6 sekund.
Závěr
Zatím se mi zdá jasné, že MÍSTO spouště je ve většině případů vítězem – v některých případech více než v jiných (například když se zvyšuje poruchovost). Zdá se, že další faktory, jako je model obnovy, mají mnohem menší dopad na celkový výkon.
Pokud máte další nápady, jak data rozdělit, nebo byste chtěli kopii dat pro vlastní krájení a krájení, dejte mi prosím vědět. Pokud byste chtěli pomoci s nastavením tohoto prostředí, abyste mohli spouštět své vlastní testy, mohu vám pomoci i s tím.
I když tento test ukazuje, že MÍSTO spouštěčů rozhodně stojí za zvážení, není to všechno. Doslova jsem tyto spouštěče spojil dohromady pomocí logiky, o které jsem si myslel, že dává pro každý scénář největší smysl, ale spouštěcí kód – jako každý příkaz T-SQL – lze vyladit pro optimální plány. V následném příspěvku se podívám na potenciální optimalizaci, díky které bude spouštěč AFTER konkurenceschopnější.
Příloha
Dotazy použité pro sekci Výsledky:
Graf 1 – Celkové souhrny
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Graf 2 a 3 – Nejlepší a nejhorší 10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Graf 4 – Typ disku protokolu, jednotlivé vložky
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;