Autor hosta:Monica Rathbun (@SQLEspresso)
Někdy se problémy s výkonem hardwaru, jako je latence vstupu/výstupu disku, sníží spíše na neoptimalizovanou zátěž než na nedostatečně výkonný hardware. Mnoho správců databáze, včetně mě, chce okamžitě obviňovat úložiště z pomalosti. Než se vydáte a utratíte spoustu peněz za nový hardware, měli byste vždy zkontrolovat, zda vaše pracovní zátěž neobsahuje zbytečné I/O.
Co je třeba prověřit
| Položka | Dopad I/O | Možná řešení |
|---|---|---|
| Nepoužité indexy | Extra zápisy | Odebrat / deaktivovat index |
| Chybějící indexy | Další čtení | Přidat rejstřík / krycí rejstříky |
| Implicitní konverze | Čtení a zápisy navíc | Před vyhodnocením hodnoty skrýt nebo přenést pole u zdroje |
| Funkce | Čtení a zápisy navíc | Odstranili je, převeďte data před vyhodnocením |
| ETL | Čtení a zápisy navíc | Použít SSIS, replikaci, změnit sběr dat, skupiny dostupnosti |
| Objednávky a skupiny | Čtení a zápisy navíc | Pokud je to možné, odstraňte je |
Nepoužité indexy
Všichni známe sílu indexu. Správné indexy mohou způsobit světelné roky rozdíl v rychlosti dotazů. Kolik z nás však neustále udržuje své indexy nad rámec přestavby indexu a reorganizací? Je důležité pravidelně spouštět indexový skript k vyhodnocení, které indexy se skutečně používají. Osobně k tomu používám diagnostické dotazy Glenna Berryho.
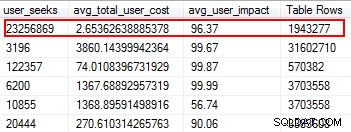
Budete překvapeni, když zjistíte, že některé vaše indexy nebyly vůbec přečteny. Tyto indexy zatěžují zdroje, zejména u vysoce transakční tabulky. Při pohledu na výsledky věnujte pozornost těm indexům, které mají vysoký počet zápisů v kombinaci s nízkým počtem čtení. V tomto příkladu můžete vidět, že plýtvám psaním. Neshlukovaný index byl zapsán 11 milionůkrát, ale byl přečten pouze dvakrát.

Začnu tím, že zakážu indexy, které spadají do této kategorie, a poté, co potvrdím, že nenastaly žádné problémy, je zruším. Pravidelným prováděním tohoto cvičení můžete výrazně omezit zbytečné vstupně-výstupní zápisy do vašeho systému, ale mějte na paměti, že statistiky využití vašich indexů jsou jen tak dobré jako při posledním restartu, takže se před odepsáním ujistěte, že jste shromažďovali data za celý obchodní cyklus. index jako „zbytečný“.
Chybějící indexy
Chybějící indexy jsou jednou z nejjednodušších věcí na opravu; koneckonců, když spustíte plán provádění, řekne vám, zda nebyly nalezeny nějaké indexy, ale to by bylo užitečné. Ale počkejte, doufám, že nepřidáváte pouze svévolně indexy na základě tohoto návrhu. Tímto způsobem můžete vytvořit duplicitní indexy a indexy, které mohou mít minimální využití, a tudíž plýtvat I/O. Znovu, zpět ke Glennovým skriptům, nám poskytuje skvělý nástroj k vyhodnocení užitečnosti indexu tím, že poskytuje vyhledávání uživatelů, dopad na uživatele a počet řádků. Věnujte pozornost těm, které mají vysoké čtení spolu s nízkou cenou a dopadem. Toto je skvělé místo pro začátek a pomůže vám snížit I/O čtení.
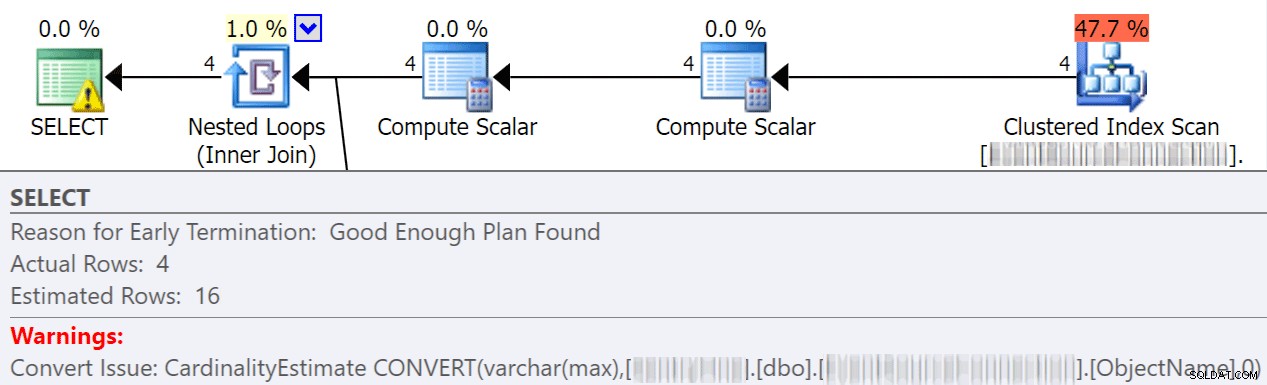
Implicitní konverze
K implicitním převodům často dochází, když dotaz porovnává dva nebo více sloupců s různými datovými typy. V níže uvedeném příkladu musí systém provést extra I/O, aby mohl porovnat sloupec varchar(max) se sloupcem nvarchar(4000), což vede k implicitní konverzi a nakonec ke skenování namísto hledání. Opravením tabulek tak, aby měly odpovídající datové typy, nebo jednoduše převedením této hodnoty před vyhodnocením můžete výrazně snížit I/O a zlepšit mohutnost (odhadované řádky, které by měl optimalizátor očekávat).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayias jde v tomto skvělém příspěvku mnohem podrobněji:„Jak drahé jsou implicitní konverze na straně sloupců?“
Funkce
Jednou z věcí, kterým se lze nejlépe vyhnout a které lze snadno opravit a které šetří náklady na vstupy a výstupy, je odstranění klauzulí z funkcí. Dokonalým příkladem je porovnání dat, jak je uvedeno níže.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Ať už je to v příkazu JOIN nebo v klauzuli WHERE, způsobí to převedení každého sloupce před jeho vyhodnocením. Pouhým převedením těchto sloupců před vyhodnocením na dočasnou tabulku můžete odstranit spoustu zbytečných I/O.
Nebo, ještě lépe, neprovádějte vůbec žádné převody (pro tento konkrétní případ zde Aaron Bertrand mluví o vyhýbání se funkcím v klauzuli where a povšimněte si, že to může být stále špatné, i když převod na datum lze protrhnout).
ETL
Udělejte si čas a prozkoumejte, jak se vaše data načítají. Ořezáváte a znovu načítáte tabulky? Můžete implementovat replikaci, repliku AG pouze pro čtení, nebo místo toho zaznamenat zásilku? Jsou všechny zapisované tabulky skutečně čteny? Jak načítáte data? Je to prostřednictvím uložených procedur nebo SSIS? Zkoumání takových věcí může dramaticky snížit I/O.
Ve svém prostředí jsem zjistil, že jsme denně ořezávali 48 tabulek s více než 120 miliony řádků každé ráno. Kromě toho jsme načítali 9,6 milionů řádků za hodinu. Dokážete si představit, kolik zbytečných I/O to vytvořilo. V mém případě byla implementace transakční replikace mým řešením. Po implementaci jsme měli mnohem méně stížností uživatelů na zpomalení během načítání, což bylo zpočátku připisováno pomalému úložišti.
Řadit podle a seskupovat podle
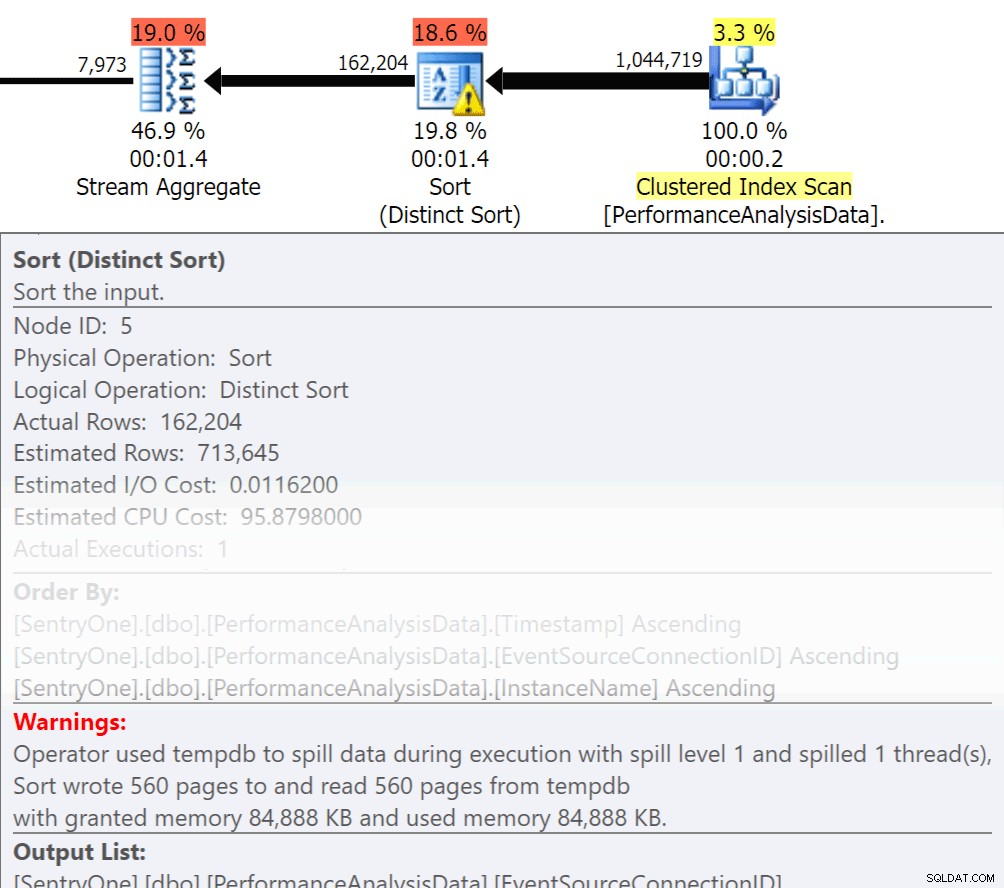 Zeptejte se sami sebe, musí se tato data vracet v pořádku? Opravdu potřebujeme seskupovat v postupu, nebo to můžeme zvládnout ve zprávě nebo aplikaci? Operace Řadit podle a Seskupit podle mohou způsobit přelití čtení na disk, což způsobí další diskové vstupy a výstupy. Pokud jsou tyto akce opodstatněné, ujistěte se, že máte podpůrné indexy a aktuální statistiky o sloupcích, které se třídí nebo seskupují. To pomůže optimalizátoru při vytváření plánu. Protože v dočasných tabulkách někdy používáme Order By a Group By. ujistěte se, že máte zapnuté automatické vytváření statistik pro TEMPDB a také vaše uživatelské databáze. Čím aktuálnější jsou statistiky, tím větší mohutnost může optimalizátor získat, což vede k lepším plánům, menšímu přelévání a menšímu počtu I/O.
Zeptejte se sami sebe, musí se tato data vracet v pořádku? Opravdu potřebujeme seskupovat v postupu, nebo to můžeme zvládnout ve zprávě nebo aplikaci? Operace Řadit podle a Seskupit podle mohou způsobit přelití čtení na disk, což způsobí další diskové vstupy a výstupy. Pokud jsou tyto akce opodstatněné, ujistěte se, že máte podpůrné indexy a aktuální statistiky o sloupcích, které se třídí nebo seskupují. To pomůže optimalizátoru při vytváření plánu. Protože v dočasných tabulkách někdy používáme Order By a Group By. ujistěte se, že máte zapnuté automatické vytváření statistik pro TEMPDB a také vaše uživatelské databáze. Čím aktuálnější jsou statistiky, tím větší mohutnost může optimalizátor získat, což vede k lepším plánům, menšímu přelévání a menšímu počtu I/O.
Nyní má Group By rozhodně své místo, pokud jde o agregaci dat namísto vracení tuny řádků. Klíčem je však snížení I/O, přidání agregace přidává I/O.
Shrnutí
Toto jsou jen špičky ledovce, ale je to skvělé místo, kde začít s omezením I/O. Než začnete obviňovat hardware z problémů s latencí, podívejte se, co můžete udělat, abyste minimalizovali tlak na disk.
O autorovi
 Monica Rathbun je v současnosti konzultantkou společnosti Denny Cherry &Associates Consulting a MVP pro datovou platformu společnosti Microsoft. Je Lone DBA již 15 let a pracuje se všemi aspekty SQL Serveru a Oracle. Cestuje a mluví na SQLSaturdays a pomáhá ostatním Lone DBA s technikami, jak lze dělat práci mnoha. Monica je vedoucí Hampton Roads SQL Server User Group a je regionální mentorkou pro středoatlantický průsmyk. Na Twitteru (@SQLEspresso) můžete Moniku vždy najít, jak svým sledujícím rozdává užitečné tipy a triky. Když není zaneprázdněná prací, najdete ji jako taxikářku pro své dvě dcery tam a zpět na taneční kurzy.
Monica Rathbun je v současnosti konzultantkou společnosti Denny Cherry &Associates Consulting a MVP pro datovou platformu společnosti Microsoft. Je Lone DBA již 15 let a pracuje se všemi aspekty SQL Serveru a Oracle. Cestuje a mluví na SQLSaturdays a pomáhá ostatním Lone DBA s technikami, jak lze dělat práci mnoha. Monica je vedoucí Hampton Roads SQL Server User Group a je regionální mentorkou pro středoatlantický průsmyk. Na Twitteru (@SQLEspresso) můžete Moniku vždy najít, jak svým sledujícím rozdává užitečné tipy a triky. Když není zaneprázdněná prací, najdete ji jako taxikářku pro své dvě dcery tam a zpět na taneční kurzy.