Zřetězení dvou nebo více datových sad se v T-SQL nejčastěji vyjadřuje pomocí UNION ALL doložka. Vzhledem k tomu, že optimalizátor SQL Server může často změnit pořadí věcí, jako jsou spojení a agregace, aby se zlepšil výkon, je docela rozumné očekávat, že SQL Server by také zvážil změnu pořadí vstupů zřetězení, kde by to poskytlo výhodu. Optimalizátor může například zvážit výhody přepsání A UNION ALL B jako B UNION ALL A .
Optimalizátor SQL Server ve skutečnosti nedělá Udělej tohle. Přesněji řečeno, existovala určitá omezená podpora pro změnu pořadí vstupu zřetězení ve verzích SQL Server až do 2008 R2, ale to bylo odstraněno v SQL Server 2012 a od té doby se znovu neobjevil.
SQL Server 2008 R2
Intuitivně na pořadí vstupů zřetězení záleží pouze v případě, že existuje cíl řádku . Ve výchozím nastavení SQL Server optimalizuje plány provádění na základě toho, že všechny kvalifikující řádky budou vráceny klientovi. Když je cíl řádku v platnosti, optimalizátor se pokusí najít plán provádění, který rychle vytvoří prvních několik řádků.
Cíle řádku lze nastavit mnoha způsoby, například pomocí TOP , FAST n nápovědu k dotazu nebo pomocí EXISTS (který ze své podstaty potřebuje najít maximálně jeden řádek). Tam, kde neexistuje žádný cíl řádku (tj. klient vyžaduje všechny řádky), obecně nezáleží na tom, v jakém pořadí jsou vstupy zřetězení čteny:Každý vstup bude nakonec v každém případě plně zpracován.
Omezená podpora ve verzích až do SQL Server 2008 R2 platí tam, kde je cílem přesně jeden řádek . Za těchto konkrétních okolností SQL Server změní pořadí vstupů zřetězení na základě očekávaných nákladů.
To se neprovádí během optimalizace na základě nákladů (jak by se dalo očekávat), ale spíše jako přepsání normálního výstupu optimalizátoru na poslední chvíli po optimalizaci. Toto uspořádání má výhodu v tom, že nezvětšuje prostor pro hledání plánu na základě nákladů (potenciálně jedna alternativa pro každou možnou změnu pořadí), zatímco stále vytváří plán, který je optimalizován tak, aby rychle vrátil první řádek.
Příklady
Následující příklady používají dvě tabulky s identickým obsahem:Milion řádků celých čísel od jednoho do milionu. Jedna tabulka je halda bez indexů bez klastrů; druhý má jedinečný seskupený index:
CREATE TABLE dbo.Expensive( Val bigint NOT NULL); CREATE TABLE dbo.Levné( Val bigint NOT NULL, CONSTRAINT [PK dbo.Levné Val] UNIQUE CLUSTERED (Val));GOINSERT dbo.Levné S (TABLOCKX) (Val)SELECT TOP (1000000) Val =ROW_NUMBER() OVER (ORDER) BY SV1.number)FROM master.dbo.spt_values JAKO SV1CROSS JOIN master.dbo.spt_values AS SV2ORDER BY ValOPTION (MAXDOP 1);GOINSERT dbo.Drahé S (TABLOCKX) (Val)SELECT C.ValFROM COPTIONMAXDe 1);
Žádný cílový řádek
Následující dotaz hledá stejné řádky v každé tabulce a vrací zřetězení těchto dvou sad:
VYBERTE E.Val OD dbo.Drahé JAKO E KDE E.Val MEZI 751000 A 751005 UNION VŠECHNY VYBERTE C.ValFROM dbo.Levné JAKO C KDE C.Val MEZI 751000 A 751005;
Plán provádění vytvořený optimalizátorem dotazů je:
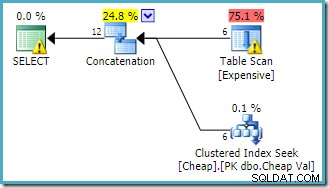
Varování v kořenovém adresáři SELECT operátor nás upozorňuje na zjevně chybějící index v tabulce haldy. Upozornění na operátora Table Scan přidává Sentry One Plan Explorer. Upozorňuje nás na I/O náklady zbytkového predikátu skrytého ve skenování.
Na pořadí vstupů do Zřetězení zde nezáleží, protože jsme nenastavili cíl řádku. Oba vstupy budou plně přečteny, aby se vrátily všechny řádky výsledků. Pro zajímavost (ač to není zaručeno) si všimněte, že pořadí vstupů odpovídá textovému pořadí původního dotazu. Všimněte si také, že není určeno ani pořadí řádků s konečným výsledkem, protože jsme nepoužili ORDER BY nejvyšší úrovně doložka. Budeme předpokládat, že je to záměrné a konečné pořadí je pro daný úkol nepodstatné.
Pokud obrátíme zapsané pořadí tabulek v dotazu takto:
VYBERTE C.ValFROM dbo.Levně JAKO C KDE C.Val MEZI 751000 A 751005 UNION VŠECHNY VYBERTE E.Val OD dbo.Drahé JAKO E KDE E.Val MEZI 751000 A 751005;
Prováděcí plán se řídí změnou, přičemž nejprve přistupuje k seskupené tabulce (opět to není zaručeno):
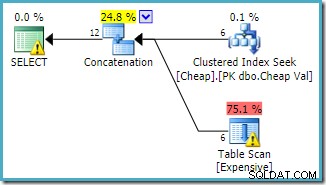
Lze očekávat, že oba dotazy budou mít stejné výkonnostní charakteristiky, protože provádějí stejné operace, jen v jiném pořadí.
S řádkovým cílem
Je zřejmé, že nedostatek indexování v tabulce haldy normálně zdraží hledání konkrétních řádků ve srovnání se stejnou operací v klastrované tabulce. Pokud požádáme optimalizátor o plán, který rychle vrátí první řádek, očekávali bychom, že SQL Server přeuspořádá vstupy zřetězení tak, aby byla nejprve konzultována levná klastrovaná tabulka.
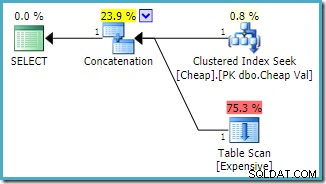
Použití dotazu, který nejprve zmiňuje tabulku haldy, a použití nápovědy k dotazu FAST 1 k určení cíle řádku:
VYBERTE E.Val OD dbo.Drahé JAKO E KDE E.Val MEZI 751000 A 751005 UNION VŠECHNY VYBERTE C.ValFROM dbo.Levné JAKO C WHERE C.Val MEZI 751000 A 751001OPTION);Odhadovaný plán provádění vytvořený na instanci SQL Server 2008 R2 je:
Všimněte si, že pořadí vstupů zřetězení bylo změněno, aby se snížily odhadované náklady na vrácení prvního řádku. Všimněte si také, že zmizela varování o chybějícím indexu a zbytkových I/O. Žádný problém není u tohoto tvaru plánu důležitý, když je cílem vrátit jeden řádek co nejrychleji.
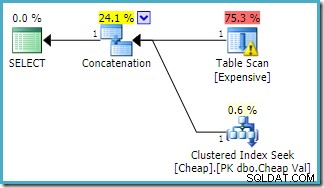
Stejný dotaz byl spuštěn na SQL Server 2016 (při použití jednoho z modelů odhadu mohutnosti) je:
SQL Server 2016 nezměnil pořadí vstupů zřetězení. Varování Plan Explorer I/O se vrátilo, ale bohužel optimalizátor tentokrát nevygeneroval varování o chybějícím indexu (ačkoli je relevantní).
Obecná změna pořadí
Jak již bylo zmíněno, přepsání po optimalizaci, které mění pořadí vstupů zřetězení, je účinné pouze pro:
- SQL Server 2008 R2 a starší
- Cíl řádku s přesně jedním
Pokud skutečně chceme vrátit pouze jeden řádek, spíše než plán optimalizovaný pro rychlé vrácení prvního řádku (který ale nakonec stejně vrátí všechny řádky), můžeme použít TOP klauzule s odvozenou tabulkou nebo společným tabulkovým výrazem (CTE):
SELECT TOP (1) UA.ValFROM( SELECT E.Val FROM dbo.Drahé JAKO E WHERE E.Val MEZI 751000 A 751005 UNION VŠECHNY VYBERTE C.Val OD dbo.Levné JAKO C KDE C.Val MEZI 751000 A 751000 ) AS UA;
Na SQL Server 2008 R2 nebo starším to vytváří optimální plán se změněným pořadím vstupu:
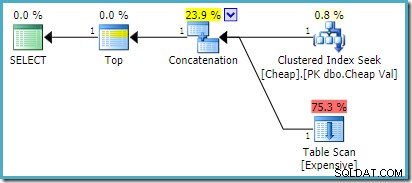
Na SQL Server 2012, 2014 a 2016 nedochází k žádné změně pořadí po optimalizaci:
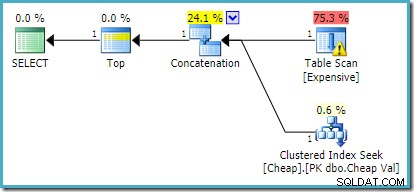
Pokud chceme vrátit více než jeden řádek, například pomocí TOP (2) , požadovaný přepis nebude použit na SQL Server 2008 R2, i když FAST 1 používá se také nápověda. V takové situaci se musíme uchýlit k trikům, jako je použití TOP s proměnnou a OPTIMIZE FOR nápověda:
DECLARE @TopRows bigint =2; -- Počet skutečně potřebných řádků SELECT TOP (@TopRows) UA.ValFROM( SELECT E.Val FROM dbo.Drahé JAKO E WHERE E.Val BETWEEN 751000 A 751005 UNION ALL SELECT C.Val FROM dbo.Levné JAKO C KDE C. Val MEZI 751000 A 751005) JAKO VOLITELNĚ (OPTIMOVAT PRO (@TopRows =1)); -- Jen nápověda
Nápověda dotazu je dostatečná k nastavení cíle řádku na jeden, zatímco hodnota proměnné za běhu zajišťuje, že se vrátí požadovaný počet řádků (2).
Skutečný plán provádění na serveru SQL Server 2008 R2 je:
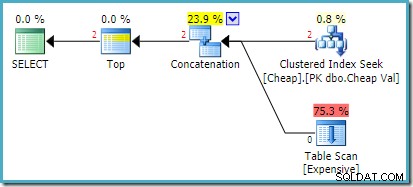
Oba vrácené řádky pocházejí ze vstupu se změněným pořadím vyhledávání a prohledávání tabulky se vůbec neprovede. Průzkumník plánu zobrazuje počty řádků červeně, protože odhad byl pro jeden řádek (kvůli nápovědě), zatímco za běhu byly zjištěny dva řádky.
Bez UNION ALL
Tento problém se také neomezuje na dotazy napsané explicitně pomocí UNION ALL . Jiné konstrukce jako EXISTS a OR může také vést k tomu, že optimalizátor zavede operátor zřetězení, který může trpět nedostatečným přeskupením vstupů. Na serveru Database Administrators Stack Exchange byl nedávno dotaz s přesně tímto problémem. Transformace dotazu z této otázky na použití našich vzorových tabulek:
VYBERTE PŘÍPAD, KDYŽ EXISTUJE ( VYBERTE 1 OD dbo. Drahé JAKO E KDE E.Val MEZI 751000 A 751005 ) NEBO EXISTUJE ( VYBERTE 1 OD dbo.Levné JAKO C KDE C.Val MEZI 7510005 A END;
Plán provádění na SQL Server 2016 má tabulku haldy na prvním vstupu:
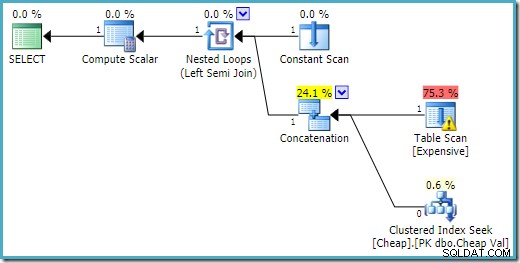
Na SQL Server 2008 R2 je pořadí vstupů optimalizováno tak, aby odráželo cíl jednoho řádku semi spojení:
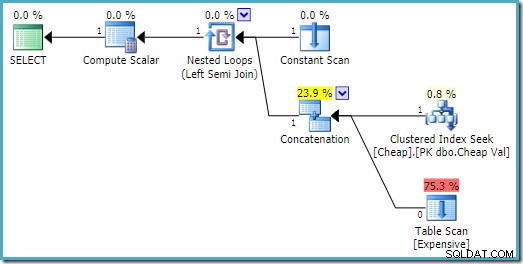
V optimálnějším plánu se skenování haldy nikdy neprovede.
Řešení
V některých případech bude autorovi dotazu zřejmé, že jeden ze vstupů zřetězení bude vždy levnější než ostatní. Pokud je to pravda, je docela rozumné přepsat dotaz tak, aby se levnější vstupy zřetězení objevily jako první v písemném pořadí. To samozřejmě znamená, že autor dotazů si musí být vědom tohoto omezení optimalizátoru a musí být připraven spoléhat se na nezdokumentované chování.
Obtížnější problém nastává, když se cena vstupů zřetězení liší podle okolností, možná v závislosti na hodnotách parametrů. Pomocí OPTION (RECOMPILE) nepomůže na SQL Server 2012 nebo novějších. Tato možnost může pomoci na serveru SQL Server 2008 R2 nebo starším, ale pouze v případě, že je splněn i cílový požadavek na jeden řádek.
Pokud existují obavy ze spoléhání se na pozorované chování (vstupy zřetězení plánu dotazu odpovídající textovému pořadí dotazu), lze k vynucení tvaru plánu použít průvodce plánem. Tam, kde jsou různé vstupní příkazy optimální pro různé okolnosti, lze použít více plánovacích vodítek, kde lze podmínky předem přesně zakódovat. To však není ideální.
Poslední myšlenky
Optimalizátor dotazů SQL Server ve skutečnosti obsahuje nákladově založené pravidlo průzkumu, UNIAReorderInputs , který je schopen generovat varianty vstupního pořadí zřetězení a zkoumat alternativy během optimalizace založené na nákladech (nikoli jako jednorázový přepis po optimalizaci).
Toto pravidlo není aktuálně povoleno pro obecné použití. Pokud mohu říci, aktivuje se pouze při průvodci plánem nebo USE PLAN nápověda je přítomna. To umožňuje modulu úspěšně vynutit plán, který byl vygenerován pro dotaz, který se kvalifikoval pro přepsání změny pořadí vstupu, i když aktuální dotaz nesplňuje požadavky.
Mám pocit, že toto pravidlo průzkumu je záměrně omezeno na toto použití, protože dotazy, kterým by prospělo přeuspořádání vstupu zřetězení v rámci optimalizace založené na nákladech, nejsou považovány za dostatečně běžné, nebo možná proto, že existuje obava, že by se dodatečné úsilí nevyplatilo. vypnuto. Můj vlastní názor je, že změna pořadí vstupu operátora zřetězení by měla být vždy prozkoumána, když je splněn cíl řádku.
Je také škoda, že (omezenější) přepis po optimalizaci není účinný v SQL Server 2012 nebo novějších. Mohlo to být způsobeno drobnou chybou, ale o tom jsem nic nenašel v dokumentaci, znalostní bázi ani na Connect. Sem jsem přidal novou položku Connect.
Aktualizace z 9. srpna 2017 :Toto je nyní opraveno pod příznakem trasování 4199 pro SQL Server 2014 a 2016, viz KB 4023419:
OPRAVA:Dotaz s UNION ALL a cílem řádku může běžet pomaleji v SQL Server 2014 nebo novějších verzích ve srovnání s SQL Server 2008 R2