Tento příspěvek je součástí série článků o cílech řádků. První díl najdete zde:
- Část 1:Stanovení a identifikace cílů řady
Je poměrně známé, že pomocí TOP nebo FAST n query hint může nastavit cíl řádku v plánu provádění (viz Nastavení a identifikace cílů řádků v plánech provádění, pokud si potřebujete osvěžit cíle řádku a jejich příčiny). Poněkud méně běžně se uznává, že poloviční spojení (a anti spojení) mohou také zavést cíl řádku, i když je to poněkud méně pravděpodobné než v případě TOP , RYCHLE a SET ROWCOUNT .
Tento článek vám pomůže pochopit, kdy a proč semi spojení vyvolá logiku cíle optimalizátoru.
Semi se připojuje
Částečné spojení vrátí řádek z jednoho vstupu spojení (A), pokud existuje alespoň jeden odpovídající řádek na druhém vstupu spojení (B).
Základní rozdíly mezi semi spojením a normálním spojením jsou:
- Poločné spojení buď vrátí každý řádek ze vstupu A, nebo ne. Nemůže dojít k duplikaci řádků.
- Běžné spojení duplikuje řádky, pokud existuje více shod v predikátu spojení.
- Poloje spojení je definováno tak, aby vracelo pouze sloupce ze vstupu A.
- Pravidelné spojení může vrátit sloupce z jednoho (nebo obou) vstupů spojení.
T-SQL v současné době postrádá podporu pro přímou syntaxi jako FROM A SEMI JOIN B ON A.x =B.y , takže musíme použít nepřímé formy jako EXISTS , NĚKTERÉ/JAKÉKOLI (včetně ekvivalentní zkratky IN pro porovnání rovnosti) a nastavte INTERSEC> .
Výše uvedený popis polovičního spojení přirozeně naznačuje použití cíle řádku, protože nás zajímá najít jakýkoli odpovídající řádek v B, nikoli všechny takové řádky . Nicméně logické semi-spojení vyjádřené v T-SQL nemusí vést k prováděcímu plánu využívajícímu cíl řádku z několika důvodů, které rozbalíme dále.
Transformace a zjednodušení
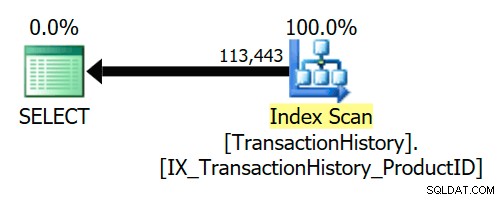
Logické semi spojení může být během kompilace a optimalizace dotazu zjednodušeno nebo nahrazeno něčím jiným. Níže uvedený příklad AdventureWorks ukazuje, že semi spojení je zcela odstraněno kvůli vztahu důvěryhodného cizího klíče:
SELECT TH.ProductID FROM Production.TransactionHistory AS THWHERE TH.ProductID IN( SELECT P.ProductID FROM Production.Product AS P);
Cizí klíč zajišťuje, že Produkt řádky budou vždy existovat pro každý řádek historie. V důsledku toho prováděcí plán přistupuje pouze k TransactionHistory tabulka:
Běžnější příklad je vidět, když semi spojení může být transformováno na vnitřní spojení. Například:
SELECT P.ProductID FROM Production.Product AS P WHERE EXISTS( SELECT * FROM Production.ProductInventory AS INV WHERE INV.ProductID =P.ProductID);
Plán provádění ukazuje, že optimalizátor zavedl agregaci (seskupení podle INV.ProductID ), abyste zajistili, že vnitřní spojení může vrátit pouze Produkt řádky jednou nebo vůbec (jak je požadováno pro zachování sémantiky semi join):
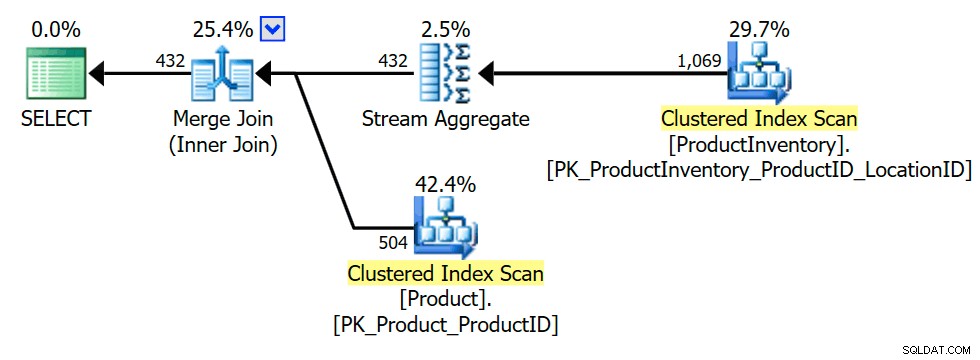
Transformace na vnitřní spojení je prozkoumána brzy, protože optimalizátor zná více triků pro vnitřní ekvijoiny než pro semi spojení, což potenciálně vede k větším příležitostem k optimalizaci. Přirozeně, konečný výběr plánu je stále rozhodnutí založené na nákladech mezi prozkoumanými alternativami.
Včasné optimalizace
Ačkoli T-SQL postrádá přímé SEMI JOIN syntaxe, optimalizátor ví vše o semi-spojení nativně a může s nimi přímo manipulovat. Syntaxe semi spojení běžného řešení jsou transformovány na „skutečné“ interní semi spojení brzy v procesu kompilace dotazu (dostatek předtím, než je zvažován triviální plán).
Dvě hlavní skupiny syntaxe pro řešení jsou EXISTS/INTERSEC> a JAKÝKOLI/NĚKTERÝ/V . EXISTUJE a INTERECT případy se liší pouze tím, že druhý přichází s implicitním DISTINCT (seskupení na všech projektovaných sloupcích). Oba EXISTUJE a INTERECT jsou analyzovány jako EXISTUJE s korelovaným poddotazem. ANY/SOME/IN reprezentace jsou všechny interpretovány jako NĚJAKÉ operace. Tuto aktivitu optimalizace můžeme brzy prozkoumat pomocí několika nezdokumentovaných příznaků trasování, které odesílají informace o aktivitě optimalizátoru na kartu zpráv SSMS.
Například semi spojení, které jsme dosud používali, lze také napsat pomocí IN :
VYBERTE P.ProductIDFROM Production.Product AS PWHERE P.ProductID IN /* or =ANY/SOME */( SELECT TH.ProductID FROM Production.TransactionHistory AS TH)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON);<8621); /před>Vstupní strom optimalizátoru je následující:
Skalární operátor ScaOp_SomeComp je
NĚKTERÉsrovnání uvedené výše. 2 je kód pro test rovnosti, protožeINje ekvivalentní=SOME. Pokud vás to zajímá, existují kódy od 1 do 6 představující (<, =, <=,>, !=,>=) operátory porovnání.Návrat do
EXISTSsyntaxi, kterou nejraději používám k nepřímému vyjádření semi spojení:SELECT P.ProductIDFROM Production.Product AS PWHERE EXISTS( SELECT * FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621););Vstupní strom optimalizátoru je:
Tento strom je docela přímý překlad textu dotazu; všimněte si však, že
SELECT *již byla nahrazena projekcí konstantní celočíselné hodnoty 1 (viz předposlední řádek textu).Další věc, kterou optimalizátor udělá, je zrušení vnoření poddotazu v relačním výběru (=filtr) pomocí pravidla RemoveSubqInSel . Optimalizátor to dělá vždy, protože nemůže pracovat přímo s poddotazy. Výsledkem je přihláška (také znám jako korelované nebo laterální spojení):
(Stejné pravidlo pro odstranění poddotazu vytváří stejný výstup pro
SOMEvstupní strom také).Dalším krokem je přepsat použití jako běžné spojení pomocí ApplyHandler vládnoucí rodina. O to se optimalizátor vždy snaží, protože má více pravidel prozkoumávání pro spojení než pro použití. Ne každou žádost lze přepsat jako spojení, ale aktuální příklad je přímočarý a úspěšný:
Všimněte si, že typ spojení je vlevo semi. Ve skutečnosti je to přesně stejný strom, jaký bychom okamžitě získali, kdyby T-SQL podporovalo syntaxi jako:
VYBERTE P.ProductID Z Production.Product AS P VLEVO SEMI JOIN Production.TransactionHistory AS TH ON TH.ProductID =P.ProductID;Bylo by hezké mít možnost takto přímoji vyjadřovat dotazy. V každém případě se doporučuje čtenářům, kteří mají zájem, aby prozkoumali výše uvedené zjednodušující aktivity s jinými logicky ekvivalentními způsoby zápisu tohoto semispojení v T-SQL.
Důležité v této fázi je, že optimalizátor vždy odstraní poddotazy , nahrazující je aplikací. Poté se pokusí přepsat žádost jako běžné spojení, aby se maximalizovaly šance na nalezení dobrého plánu. Pamatujte, že vše předchozí se odehraje ještě předtím, než se vezme v úvahu triviální plán. Během optimalizace založené na nákladech může optimalizátor zvážit také transformaci spojení zpět do aplikace.
Hash a Merge Semi Join
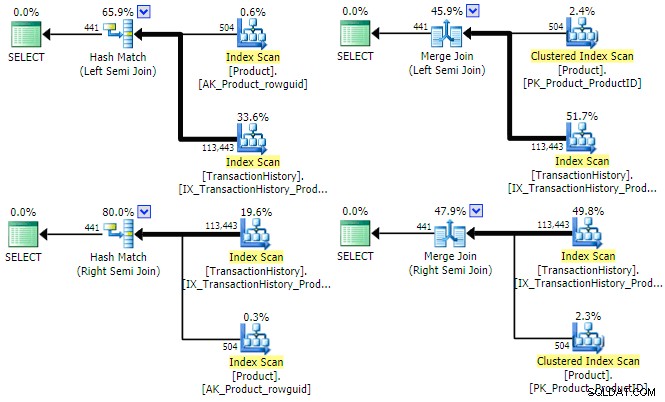
SQL Server má tři hlavní možnosti fyzických implementací pro logické semi spojení. Dokud je přítomen predikát equijoin, jsou k dispozici hash a merge join; oba mohou pracovat v režimu levého a pravého polovičního spojení. Spojení vnořených smyček podporuje pouze levé (nikoli pravé) semi spojení, ale nevyžaduje predikát ekvijoin. Podívejme se na fyzické možnosti hash a sloučení pro náš vzorový dotaz (tentokrát napsaný jako protínající se sada):
SELECT P.ProductID FROM Production.Product AS PINTERSECTSELECT TH.ProductID FROM Production.TransactionHistory AS TH;Optimalizátor může pro tento dotaz najít plán pro všechny čtyři kombinace (vlevo/vpravo) a (hash/merge) semi spojení:
Stojí za to stručně zmínit, proč může optimalizátor zvážit levá i pravá poloviční spojení pro každý typ spojení. U hašovacího semi spojení je hlavním faktorem nákladů odhadovaná velikost hašovací tabulky, která je zpočátku vždy levým (horním) vstupem. U semi spojení sloučení určují vlastnosti každého vstupu, zda bude použito sloučení typu one-to-many nebo méně efektivní mnoho-to-many s pracovní tabulkou.
Z výše uvedených prováděcích plánů může být zřejmé, že ani hash, ani sloučení semi spojení by nemělo prospěch z nastavení cíle řádku . Oba typy spojení vždy testují predikát spojení na samotném spojení a jejich cílem je spotřebovat všechny řádky z obou vstupů, aby se vrátila úplná sada výsledků. To neznamená, že pro hash a slučovací spojení obecně neexistují optimalizace výkonu – oba mohou například využívat bitmapy ke snížení počtu řádků, které se dostanou do spojení. Jde spíše o to, že cíl řádku na žádném vstupu by nezefektivnil hash nebo sloučení semi spojení.
Vnořené smyčky a použití semi spojení
Zbývajícím typem fyzického spojení jsou vnořené smyčky, které jsou k dispozici ve dvou variantách:běžné (nekorelované) vnořené smyčky a použít vnořené smyčky (někdy také označované jako korelované nebo boční připojit se).
Běžné spojení vnořených smyček je podobné spojení hash a merge v tom, že predikát spojení je vyhodnocen při spojení. Stejně jako dříve to znamená, že nemá cenu nastavovat cíl řádku na žádném vstupu. Levý (horní) vstup bude nakonec vždy plně spotřebován a vnitřní vstup nemá žádný způsob, jak určit, který řádek (řádky) by měl mít prioritu, protože nemůžeme vědět, zda se řádek spojí nebo ne, dokud nebude predikát testován při spojení. .
Naproti tomu spojení s vnořenými smyčkami aplikace má jednu nebo více vnějších referencí (korelované parametry) ve spojení s predikátem spojení posunutým dolů vnitřní (spodní) strana spoje. To vytváří příležitost pro užitečnou aplikaci řadového cíle. Připomeňme, že poloviční spojení vyžaduje pouze kontrolu existence řádku na vstupu spojení B, který odpovídá aktuálnímu řádku na vstupu spojení A (nyní myslíme pouze na strategie spojení vnořených smyček).
Jinými slovy, při každé iteraci aplikace se můžeme přestat dívat na vstup B, jakmile je nalezena první shoda, pomocí odsunutého predikátu spojení. To je přesně ten druh věcí, pro které je cíl řádku dobrý:generování části plánu optimalizovaného tak, aby rychle vrátilo prvních n odpovídajících řádků (kde
n =1zde).Samozřejmě, že gól z řady může být dobrý nebo ne, v závislosti na okolnostech. V tomto ohledu není na cíli semi join row nic zvláštního. Zvažte situaci, kdy je vnitřní strana semi spojení složitější než jednoduchý přístup k tabulce, možná spojení s více tabulkami. Nastavení cíle řádku může pomoci optimalizátoru vybrat účinnou navigační strategii pouze pro tento konkrétní podstrom , nalezení prvního shodného řádku, který uspokojí semi spojení prostřednictvím spojení vnořených smyček a hledání indexu. Bez cíle řádku může optimalizátor přirozeně zvolit hash nebo sloučení spojení s řazením, aby minimalizoval očekávané náklady na vrácení všech možných řádků. Všimněte si, že zde existuje předpoklad, a sice, že lidé obvykle píší poloviční spojení s očekáváním, že řádek odpovídající vyhledávací podmínce ve skutečnosti existuje. Zdá se mi to jako dostačující předpoklad.
Bez ohledu na to je v této fázi důležitý bod:Pouze požádat spojení vnořených smyček má cíl řádku aplikovaný optimalizátorem (nezapomeňte však, že cíl řádku pro spojení vnořených smyček aplikace se přidá pouze v případě, že je cíl řádku menší než odhad bez něj). Podíváme se na několik zpracovaných příkladů, abychom to příště snad objasnili.
Příklady semi spojení vnořených smyček
Následující skript vytvoří dvě dočasné tabulky haldy. První má čísla od 1 do 20 včetně; druhý má 10 kopií každého čísla v první tabulce:
PUSTIT TABULKU, POKUD EXISTUJE #E1, #E2; CREATE TABLE #E1 (c1 integer NULL);CREATE TABLE #E2 (c1 integer NULL); INSERT #E1 (c1)SELECT SV.numberFROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' AND SV.number>=1 AND SV.number <=20; INSERT #E2 (c1)SELECT (SV.number % 20) + 1FROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' AND SV.number>=1 AND SV.number <=200;Bez indexů a relativně malého počtu řádků optimalizátor zvolí implementaci vnořených smyček (spíše než hash nebo sloučení) pro následující polospojovací dotaz). Nedokumentované příznaky trasování nám umožňují zobrazit výstupní strom optimalizátoru a informace o cíli řádku:
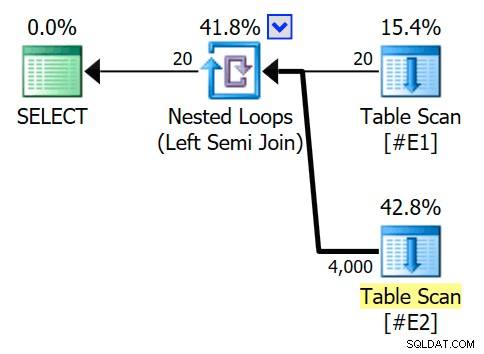
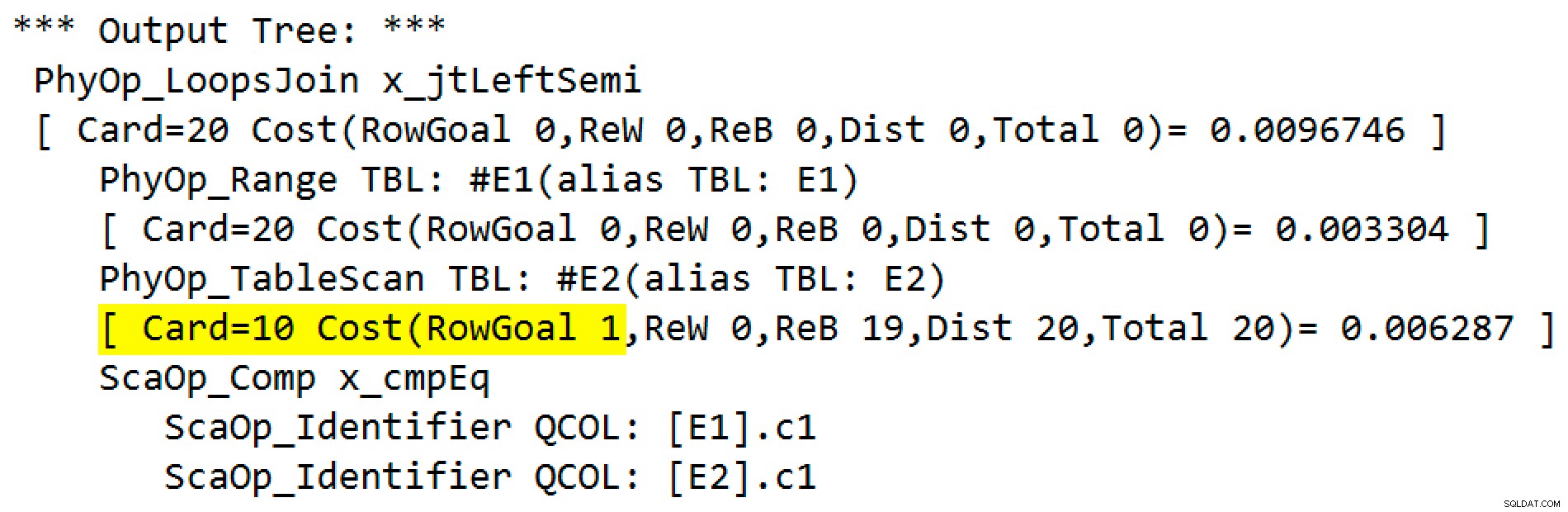
VOLBA SELECT E1.c1 FROM #E1 AS E1WHERE E1.c1 IN (SELECT E2.c1 FROM #E2 AS E2) (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);Odhadovaný plán provádění obsahuje polospojování vnořených smyček s 200 řádky na úplné skenování tabulky
#E2. 20 iterací cyklu dává celkový odhad 4 000 řádků:
Vlastnosti operátoru vnořených smyček ukazují, že predikát je aplikován na spojení což znamená, že se jedná o nekorelované spojení vnořených smyček :
Výstup příznaku trasování (na kartě Zprávy SSMS) zobrazuje polospojení vnořených smyček a žádný cíl řádku (RowGoal 0):
Všimněte si, že plán po provedení pro tento dotaz na hračky neukáže celkem 4 000 řádků přečtených z tabulky #E2. Polospojení vnořených smyček (korelované nebo ne) přestane hledat další řádky na vnitřní straně (na iteraci), jakmile je nalezena první shoda pro aktuální vnější řádek. Nyní je pořadí řádků zjištěných při skenování haldy #E2 v každé iteraci nedeterministické (a může se v každé iteraci lišit), takže v zásadě téměř všechny řádky bylo možné otestovat v každé iteraci v případě, že se na odpovídající řádek narazí co nejpozději (nebo v případě žádného shodného řádku vůbec ne).
Pokud například předpokládáme implementaci za běhu, kde jsou řádky pokaždé skenovány ve stejném pořadí (např. „objednávka vložení“), celkový počet řádků naskenovaných v tomto příkladu hračky bude 20 řádků v první iteraci, 1 řádek při druhé iteraci, 2 řádky ve třetí iteraci a tak dále, celkem 20 + 1 + 2 + (…) + 19 =210 řádků. Je docela pravděpodobné, že budete pozorovat tento celkový počet, který vypovídá více o omezeních jednoduchého demonstračního kódu než o čemkoli jiném. Nelze spoléhat na pořadí řádků vrácených z neuspořádané přístupové metody o nic víc, než se lze spolehnout na zdánlivě uspořádaný výstup z dotazu bez
ORDER BYnejvyšší úrovně doložka.Použít poloviční připojení
Nyní vytvoříme index bez klastrů na větší tabulce (abychom optimalizátora povzbudili, aby zvolil použití semi spojení) a spustíme dotaz znovu:
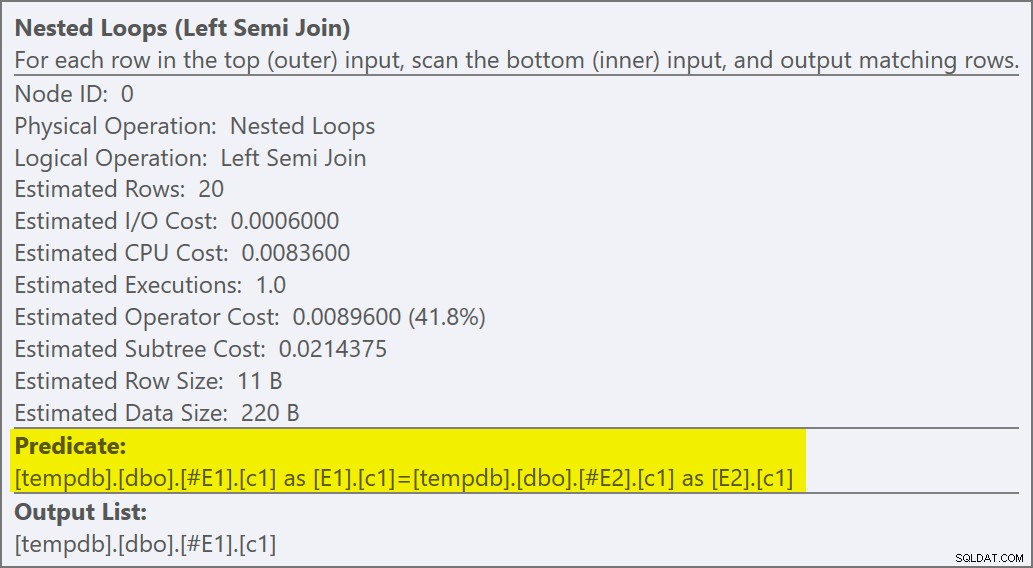
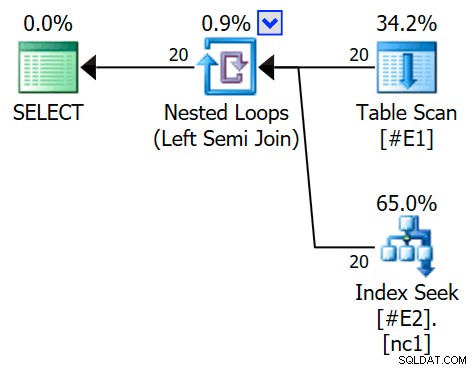
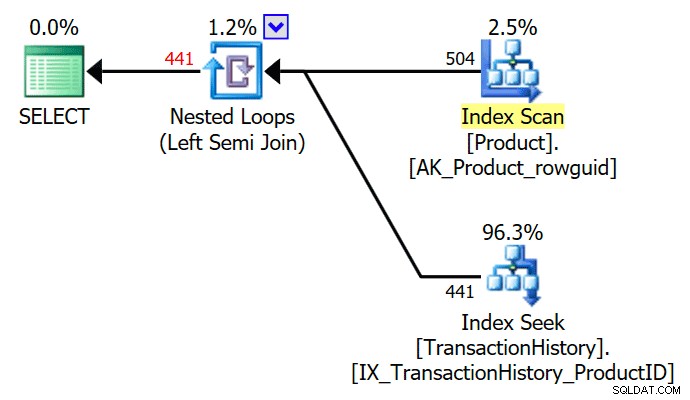
VYTVOŘIT NENEZAHRNUTÝ INDEX nc1 NA #E2 (c1); SELECT E1.c1 FROM #E1 AS E1WHERE E1.c1 IN (SELECT E2.c1 FROM #E2 AS E2)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);Plán provádění nyní obsahuje použití semi spojení s 1 řádkem na hledání indexu (a 20 iteracemi jako dříve):
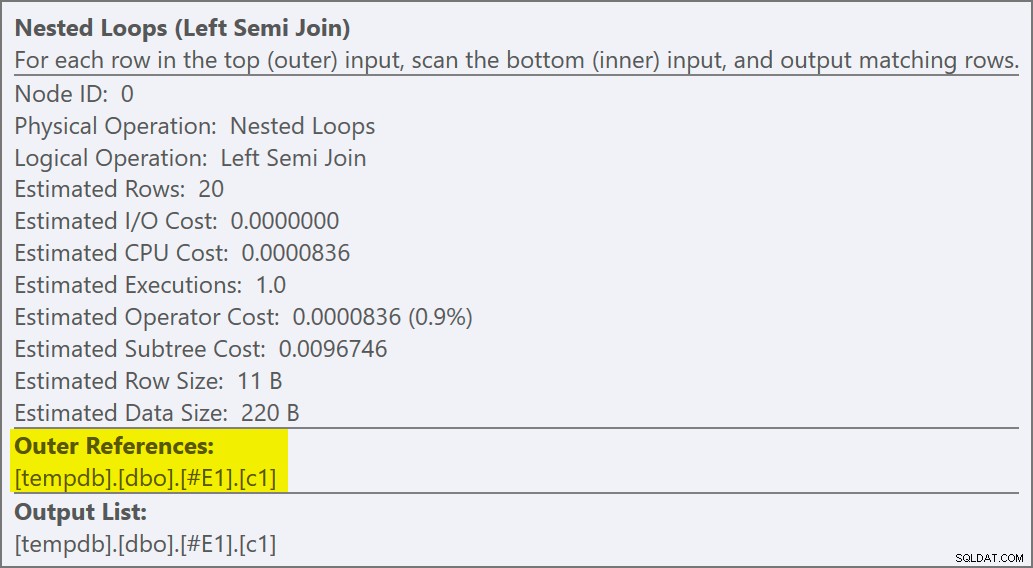
Můžeme říci, že jde o použít semi připojení protože vlastnosti spojení zobrazují vnější odkaz spíše než predikát spojení:
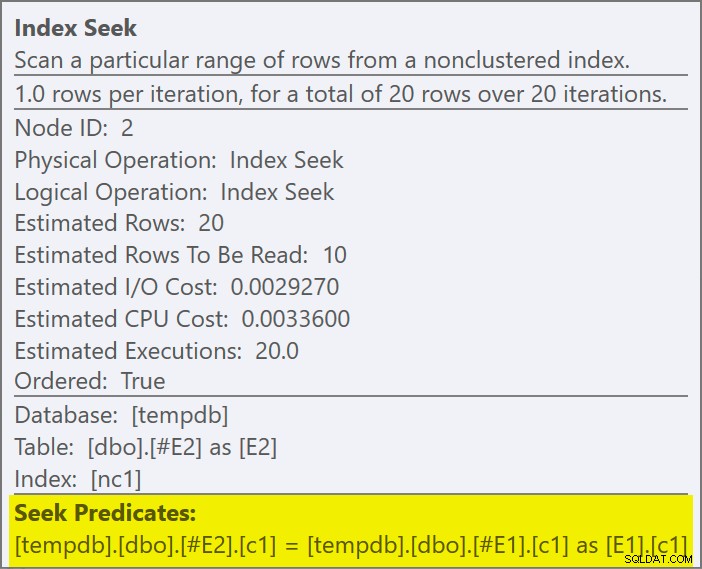
Predikát spojení byl odsunut vnitřní strana aplikace a odpovídající novému indexu:
Očekává se, že každé hledání vrátí 1 řádek, a to navzdory skutečnosti, že každá hodnota je v této tabulce 10krát duplikována; toto je účinek cíle řádku . Cíl řádku bude snazší identifikovat na SQL Server sestavení, která odhalují EstimateRowsWithoutRowGoal atribut plan (SQL Server 2017 CU3 v době psaní). V nadcházející verzi Průzkumníka plánu to bude také uvedeno v popisech pro příslušné operátory:
Výstup příznaku trasování je:
Fyzický operátor se změnil ze spojení smyček na aplikaci spuštěnou v režimu levého polovičního spojení. Přístup k tabulce
#E2získal cíl řady 1 (kardinalita bez cíle řady je zobrazena jako 10). Cíl řádku není v tomto případě velký problém, protože náklady na získání přibližně deseti řádků na hledání nejsou o mnoho vyšší než na jeden řádek. Deaktivace cílů řádku pro tento dotaz (pomocí příznaku trasování 4138 neboDISABLE_OPTIMIZER_ROWGOALquery hint) nezmění tvar plánu.Nicméně u realističtějších dotazů může snížení nákladů v důsledku cíle vnitřního řádku znamenat rozdíl mezi konkurenčními možnostmi implementace. Například deaktivace cíle řádku může způsobit, že optimalizátor místo toho zvolí hash nebo sloučené semi spojení nebo kteroukoli z mnoha dalších možností, které jsou pro dotaz zvažovány. Pokud nic jiného, cíl řádku zde přesně odráží skutečnost, že aplikované semi spojení přestane prohledávat vnitřní stranu, jakmile je nalezena první shoda, a přesune se na další řádek vnější strany.
Všimněte si, že duplikáty byly vytvořeny v tabulce
#E2takže cíl použít semi spojení řádku (1) by byl nižší než normální odhad (10, z informací o hustotě statistiky). Pokud nebyly žádné duplikáty, odhad řádku pro každé hledání do#E2by byl také 1 řádek, takže cíl řádku 1 by nebyl použit (pamatujte na obecné pravidlo!)Cíle v řadě versus nahoře
Vzhledem k tomu, že prováděcí plány před SQL Serverem 2017 CU3 vůbec nenaznačují přítomnost cíle řádku, někdo by si mohl myslet, že by bylo jasnější implementovat tuto optimalizaci pomocí explicitního operátoru Top, spíše než skryté vlastnosti, jako je cíl řádku. Záměrem by bylo jednoduše umístit horní (1) operátor na vnitřní stranu aplikovaného semi/anti spojení namísto nastavení cíle řádku u samotného spojení.
Použití operátoru Top tímto způsobem by nebylo zcela bez precedentu. Například již existuje speciální verze Top známá jako nejvyšší počet řádků zobrazená v plánech provádění úprav dat, když je nenulová hodnota
SET ROWCOUNTje v platnosti (všimněte si, že toto konkrétní použití bylo od roku 2005 zastaralé, ačkoli je stále povoleno v SQL Server 2017). Implementace nejvyššího počtu řádků je trochu neohrabaná v tom, že nejvyšší operátor je v plánu provádění vždy zobrazen jako horní (0) bez ohledu na skutečný platný limit počtu řádků.Neexistuje žádný pádný důvod, proč by cíl použít semi spojení řádku nemohl být nahrazen explicitním operátorem Top (1). Existuje však několik důvodů, proč upřednostňovat nedělat to:






- Přidání explicitního vrcholu (1) vyžaduje větší úsilí a testování optimalizátoru při kódování než přidání cíle řádku (který se již používá pro jiné věci).
- Top není relační operátor; optimalizátor má malou podporu pro uvažování o tom. To by mohlo negativně ovlivnit kvalitu plánu omezením schopnosti optimalizátoru transformovat části plánu dotazů, např. přesouváním agregátů, sjednocení, filtrů a spojení.
- Zavedlo by to těsné spojení mezi aplikovanou implementací semi spojení a horní částí. Speciální případy a těsné propojení jsou skvělé způsoby, jak zavést chyby a učinit budoucí změny obtížnějšími a náchylnějšími k chybám.
- Nejvyšší (1) by byl logicky nadbytečný a přítomen pouze kvůli vedlejšímu efektu cíle na řádek.
Tento poslední bod stojí za to rozšířit o příklad:
VYBERTE P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID);
TOP (1) v poddotazu exists je optimalizátorem zjednodušen a poskytuje jednoduchý plán provádění semi-connect:
Optimalizátor může také odstranit nadbytečný DISTINCT nebo GROUP BY v poddotazu. Následující všechny vytvářejí stejný plán jako výše:
-- Redundantní DISTINCTSELECT P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT DISTINCT TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID ); -- Redundantní GROUP BYSELECT P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID GROUP BY TH.ProductID); -- Redundantní DISTINCT TOP (1) SELECT P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT DISTINCT TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID);
Shrnutí a závěrečné myšlenky
Pouze použít vnořené smyčky semi join mohou mít cíl řádku nastavený optimalizátorem. Toto je jediný typ spojení, který posune predikát(y) spojení dolů ze spojení, což umožňuje včas provést testování na existenci shody . Nekorelované vnořené smyčky se částečně spojují téměř nikdy* nastavuje cíl řádku a nespojí se ani hash nebo slučovací semi. Použití vnořených smyček lze odlišit od nekorelovaných spojení vnořených smyček přítomností vnějších odkazů (místo predikátu) na operátoru spojení vnořených smyček pro aplikaci.
Pravděpodobnost, že se v konečném prováděcím plánu objeví aplikované semi spojení, do jisté míry závisí na včasné optimalizační aktivitě. Protože chybí přímá syntaxe T-SQL, musíme semi spojení vyjádřit nepřímým způsobem. Ty jsou analyzovány do logického stromu obsahujícího poddotaz, který časná aktivita optimalizátoru transformuje na aplikaci a poté na nekorelované semi-spojení, kde je to možné.
Tato aktivita zjednodušení určuje, zda je logické semi spojení prezentováno optimalizátoru založenému na nákladech jako použití nebo běžné semi spojení. Když je prezentováno jako logická použít semi join, CBO je téměř jisté, že vytvoří konečný prováděcí plán obsahující vnořené smyčky fyzické aplikace (a tedy stanovení cíle řádku). Když se zobrazí nekorelované semi spojení, CBO může zvážit transformaci na aplikaci (nebo nemusí). Konečný výběr plánu je jako obvykle série rozhodnutí založených na nákladech.
Stejně jako všechny cíle v řadě může být cíl pro semi-spojení řady pro výkon dobrou nebo špatnou věcí. Vědět, že aplikované semi spojení nastavuje cíl řádku, alespoň pomůže lidem rozpoznat a řešit příčinu, pokud by nastal problém. Řešením nebude vždy (nebo dokonce obvykle) deaktivace cílů řádku pro dotaz. Vylepšení v indexování (a/nebo dotazu) lze často provést tak, aby poskytlo efektivní způsob, jak najít první odpovídající řádek.
Anti semi spojům se budu věnovat v samostatném článku, který bude pokračovat v sérii cílů.
* Výjimkou je nekorelované polospojení vnořených smyček bez predikátu spojení (neobvyklý pohled). Tím je nastaven cíl řádku.