Za prvé, „toxi“ není standardní termín. Vždy definujte své podmínky! Nebo alespoň poskytněte relevantní odkazy.
A teď k samotné otázce...
Ne, budete mít 3 stoly.
Jste do značné míry na správné cestě, s tou výjimkou, že ke „sloučení“ mnoha z těchto kroků můžete použít povahu SQL založenou na množinách. Například označení položky 1 značkami:'tag1', 'tag2' a 'tag3' lze provést takto...
INSERT IGNORE INTO tagmap (item_id, tag_id)
SELECT 1, tag_id FROM tags WHERE tag_text IN ('tag1', 'tag2', 'tag3');
IGNORE umožňuje, aby to bylo úspěšné, i když je položka již připojena k některým z těchto značek.
To předpokládá, že všechny požadované značky jsou již v tags . Za předpokladu tag.tag_id je automatické zvýšení, můžete udělat něco takového, abyste zajistili, že jsou:
INSERT IGNORE INTO tags (tag_text) VALUES ('tag1'), ('tag2'), ('tag3');
Neexistuje žádná magie. Pokud je „položka připojena ke konkrétní značce“ je znalost, kterou chcete zaznamenat, pak bude mít mít v databázi nějakou fyzickou reprezentaci.
Myslíte přeznačkování položek (neupravování samotných značek)?
Chcete-li odstranit všechny značky, které nejsou v seznamu, proveďte něco takového:
DELETE FROM tagmap
WHERE
item_id = 1
AND tag_id NOT IN (
SELECT tag_id FROM tags
WHERE tag_text IN ('tag1', 'tag3')
);
Toto odpojí položku od všech značek kromě 'tag1' a 'tag3'. Proveďte INSERT výše a toto DELETE jeden po druhém, abyste „pokryli“ přidávání i odebírání značek.
S tím vším si můžete hrát v SQL Fiddle .
Opravit. Podřízený koncový bod FK nespustí referenční akci (např. ON DELETE CASCADE), pouze nadřazený.
BTW, toto schéma používáte, protože chcete další pole v tags (vedle tag_text ), že jo? Pokud tak učiníte, neztratit tato dodatečná data jen proto, že všechna připojení jsou pryč, je žádoucí chování.
Ale pokud jste jen chtěli tag_text , použili byste jednodušší schéma, kde by smazání všech připojení bylo stejné jako smazání samotné značky:
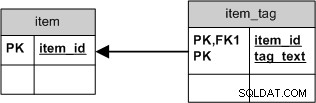
To by nejen zjednodušilo SQL, ale také by to poskytlo lepší shlukování .
Na první pohled může „toxi“ vypadat, že šetří místo, ale v praxi tomu tak nemusí být, protože vyžaduje další tabulky a indexy (a značky bývají krátké).
Než se k něčemu takovému rozhodnete, změřte se. Můj SQL Fiddle zmíněný výše používá velmi záměrné pořadí polí v tagmap PK, takže data jsou seskupena způsobem, který je pro tento druh počítání velmi přátelský (pamatujte:Tabulky InnoDB jsou seskupené
). Než se z toho stane problém, museli byste mít opravdu obrovské množství položek (nebo vyžadovat neobvykle vysoký výkon).
V každém případě měřte na realistickém množství dat!