I když existují různé způsoby, jak obnovit databázi PostgreSQL, jeden z nejpohodlnějších přístupů k obnově dat z logické zálohy. Logické zálohy hrají významnou roli pro plánování po havárii a obnově (DRP). Logické zálohy jsou zálohy pořízené například pomocí pg_dump nebo pg_dumpall, které generují příkazy SQL pro získání všech dat tabulky, která jsou zapsána do binárního souboru.
Doporučujeme také spouštět pravidelné logické zálohy v případě, že vaše fyzické zálohy selžou nebo jsou nedostupné. Pro PostgreSQL může být obnovení problematické, pokud si nejste jisti, jaké nástroje použít. Zálohovací nástroj pg_dump je běžně spárován s obnovovacím nástrojem pg_restore.
pg_dump a pg_restore jednají v tandemu, pokud dojde ke katastrofě a potřebujete obnovit svá data. I když slouží primárnímu účelu výpisu a obnovy, vyžadují provedení některých dalších úkolů, když potřebujete obnovit cluster a provést převzetí služeb při selhání (pokud váš aktivní primární nebo hlavní server zemře kvůli selhání hardwaru nebo poškození systému VM). Nakonec najdete a využijete nástroje třetích stran, které zvládnou převzetí služeb při selhání nebo automatické obnovení clusteru.
V tomto blogu se podíváme na to, jak funguje pg_restore, a porovnáme to s tím, jak ClusterControl zpracovává zálohování a obnovu vašich dat v případě katastrofy.
Mechanismy pg_restore
pg_restore je užitečné při získávání následujících úloh:
- ve spojení s pg_dump pro generování SQL generovaných souborů obsahujících data, přístupové role, databáze a definice tabulek
- obnovte PostgreSQL databázi z archivu vytvořeného pg_dump v jednom z formátů, které nejsou prostým textem.
- Vydá příkazy potřebné k rekonstrukci databáze do stavu, ve kterém byla v době, kdy byla uložena.
- má schopnost vybrat nebo dokonce změnit pořadí položek před obnovením na základě archivního souboru
- Archivní soubory jsou navrženy tak, aby byly přenositelné mezi architekturami.
- pg_restore může fungovat ve dvou režimech.
- Pokud je zadán název databáze, pg_restore se připojí k této databázi a obnoví obsah archivu přímo do databáze.
- nebo se vytvoří skript obsahující příkazy SQL nezbytné k přestavbě databáze a zapíše se do souboru nebo na standardní výstup. Jeho výstup skriptu je ekvivalentní formátu generovanému pg_dump
- Některé možnosti ovládající výstup jsou proto analogické s možnostmi pg_dump.
Jakmile obnovíte data, je nejlepší a vhodné spustit ANALYZE u každé obnovené tabulky, aby měl optimalizátor užitečné statistiky. Ačkoli získává READ LOCK, možná jej budete muset spustit při nízkém provozu nebo během období údržby.
Výhody pg_restore
pg_dump a pg_restore v tandemu mají funkce, které jsou vhodné pro DBA.
- pg_dump a pg_restore mohou běžet paralelně zadáním volby -j. Použití -j/--jobs
vám umožňuje určit, kolik běžících úloh může běžet paralelně, zejména pro načítání dat, vytváření indexů nebo vytváření omezení pomocí více souběžných úloh. - Je to tiché a praktické použití, můžete selektivně vypsat nebo načíst konkrétní databázi nebo tabulky
- Umožňuje a poskytuje uživateli flexibilitu v tom, jakou konkrétní databázi, schéma nebo změnu pořadí procedur mají být provedeny na základě seznamu. Můžete dokonce generovat a načítat sekvenci SQL volně, jako zabránit ACL nebo oprávnění podle vašich potřeb. Existuje spousta možností, které vyhovují vašim potřebám.
- Poskytuje vám možnost generovat soubory SQL stejně jako pg_dump z archivu. To je velmi výhodné, pokud chcete načíst do jiné databáze nebo hostitele a zajistit samostatné prostředí.
- Je snadno pochopitelný na základě vygenerované sekvence SQL procedur.
- Je to pohodlný způsob načítání dat v prostředí replikace. Nepotřebujete, aby byla vaše replika přeformátována, protože příkazy jsou SQL, které byly replikovány až do pohotovostního režimu a uzlů obnovy.
Omezení pg_restore
U logických záloh je zřejmým omezením pg_restore spolu s pg_dump výkon a rychlost při použití nástrojů. Může být užitečné, když chcete zřídit testovací nebo vývojové databázové prostředí a načíst svá data, ale není použitelné, když je vaše datová sada obrovská. PostgreSQL musí vypsat vaše data jedno po druhém nebo spustit a aplikovat vaše data sekvenčně databázovým strojem. Ačkoli to můžete zrychlit, například zadáním -j nebo použitím --single-transaction, abyste se vyhnuli dopadu na vaši databázi, načítání pomocí SQL musí být stále analyzováno modulem.
Dokumentace PostgreSQL navíc uvádí následující omezení s našimi dodatky, jak jsme pozorovali tyto nástroje (pg_dump a pg_restore):
- Při obnově dat do již existující tabulky a použití volby --disable-triggers, pg_restore vydá příkazy k deaktivaci spouštěčů v uživatelských tabulkách před vložením dat a poté vydá příkazy k jejich opětovné aktivaci po vložení údajů. Pokud se obnova uprostřed zastaví, systémové katalogy mohou zůstat ve špatném stavu.
- pg_restore nemůže selektivně obnovit velké objekty; například pouze ty pro konkrétní tabulku. Pokud archiv obsahuje velké objekty, budou obnoveny všechny velké objekty nebo žádný z nich, pokud jsou vyloučeny pomocí -L, -t nebo jiných voleb.
- Očekává se, že oba nástroje budou generovat obrovské množství velikosti (soubory, adresář nebo archiv tar), zejména pro obrovskou databázi.
- Pro pg_dump při vyhazování jedné tabulky nebo jako prostý text nezpracovává pg_dump velké objekty. Velké objekty musí být vypsány s celou databází pomocí některého z netextových archivních formátů.
- Pokud máte archivy tar generované těmito nástroji, mějte na paměti, že archivy tar jsou omezeny na velikost menší než 8 GB. Toto je přirozené omezení formátu souboru tar. Proto tento formát nelze použít, pokud textová reprezentace tabulky přesahuje tuto velikost. Celková velikost archivu tar a kteréhokoli z dalších výstupních formátů není omezena, možná s výjimkou operačního systému.
Použití pg_restore
Použití pg_restore je docela praktické a snadno použitelné. Protože je spárován v tandemu s pg_dump, oba tyto nástroje fungují dostatečně dobře, pokud cílový výstup vyhovuje druhému. Například následující pg_dump nebude užitečný pro pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Tento výsledek bude kompatibilní s psql, který vypadá následovně:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;To se ale pro pg_restore nezdaří, protože neexistuje žádný prostý formát, který by se dal následovat:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerNyní přejdeme k užitečnějším výrazům pro pg_restore.
pg_restore:Přetažení a obnovení
Zvažte jednoduché použití pg_restore, ze kterého jste odstranili databázi, např.
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Obnovení pomocí pg_restore je velmi jednoduché
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump Zde -C/--create uvádí, že vytvoří databázi, jakmile je nalezena v záhlaví. -d postgres ukazuje na postgres databázi, ale to neznamená, že vytvoří tabulky do postgres databáze. Vyžaduje, aby databáze existovala. Pokud není zadáno -C, tabulky a záznamy budou uloženy do databáze, na kterou odkazuje argument -d.
Selektivní obnovení podle tabulky
Obnovení tabulky pomocí pg_restore je snadné a jednoduché. Například máte dvě tabulky, jmenovitě tabulky "b" a "d". Řekněme, že spustíte následující příkaz pg_dump níže,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Kde bude obsah tohoto adresáře vypadat následovně,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Pokud chcete obnovit tabulku (v tomto příkladu konkrétně "d"),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Musím mít,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:Kopírování databázových tabulek do jiné databáze
Můžete dokonce zkopírovat obsah své stávající databáze a mít ji ve své cílové databázi. Mám například následující databáze,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)Paultest databáze je prázdná databáze, zatímco my se chystáme zkopírovat to, co je v databázi maxtest,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Chceme-li je zkopírovat, musíme vypsat data z databáze maxtest následovně,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Potom jej načtěte nebo obnovte následujícím způsobem
Nyní máme data z databáze paultest a tabulky byly podle toho uloženy.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Vygenerujte soubor SQL pomocí změny pořadí
Viděl jsem hodně využití s pg_restore, ale zdá se, že tato funkce není obvykle předváděna. Tento přístup mi připadal velmi zajímavý, protože vám umožňuje objednávat na základě toho, co nechcete zahrnout, a poté z objednávky, kterou chcete pokračovat, vygenerovat soubor SQL.
Například použijeme ukázkový pgdump_data.tar, který jsme vygenerovali dříve, a vytvoříme seznam. Chcete-li to provést, spusťte následující příkaz:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listToto vygeneruje soubor, jak je ukázáno níže:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresNyní to přeuspořádáme nebo řekněme, že jsem odstranil vytvoření SEQUENCE a také vytvoření omezení. To by vypadalo následovně,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresChcete-li vygenerovat soubor ve formátu SQL, postupujte takto:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Nyní bude soubor /tmp/selective_data.out soubor generovaný SQL a je čitelný, pokud používáte psql, ale ne pg_restore. Skvělé na tom je, že můžete vygenerovat soubor SQL podle vaší šablony, do kterého lze obnovit data pouze z existujícího archivu nebo zálohy pořízené pomocí pg_dump s pomocí pg_restore.
Obnovení PostgreSQL pomocí ClusterControl
ClusterControl nevyužívá pg_restore nebo pg_dump jako součást své sady funkcí. Pro generování logických záloh používáme pg_dumpall a výstup bohužel není kompatibilní s pg_restore.
Existuje několik dalších způsobů, jak vytvořit zálohu v PostgreSQL, jak je uvedeno níže.
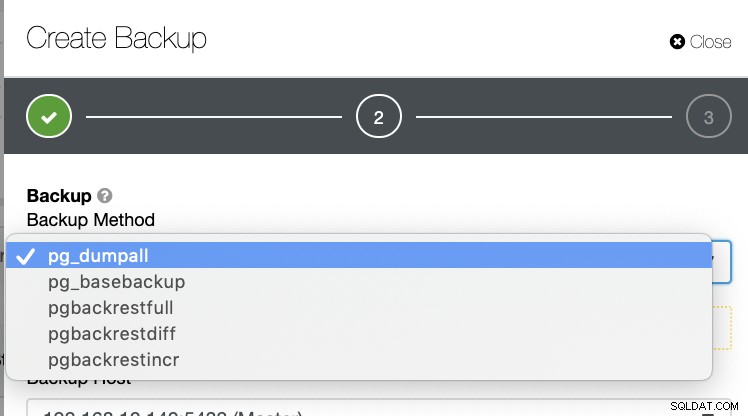
Neexistuje žádný takový mechanismus, kde byste mohli selektivně ukládat tabulku, databázi, nebo zkopírujte z jedné databáze do jiné databáze.
ClusterControl podporuje Point-in-Time Recovery (PITR), ale to vám neumožňuje spravovat obnovu dat tak flexibilně jako u pg_restore. Pro celý seznam metod zálohování, pouze pg_basebackup a pgbackrest jsou schopné PITR.
Jak ClusterControl zpracovává obnovu spočívá v tom, že má schopnost obnovit neúspěšný cluster, pokud je povoleno automatické obnovení, jak je uvedeno níže.

Jakmile selže hlavní server, může podřízený cluster automaticky obnovit během provádění ClusterControl převzetí služeb při selhání (které se provádí automaticky). Pokud jde o část obnovy dat, vaší jedinou možností je mít obnovu v celém clusteru, což znamená, že pochází z úplné zálohy. Neexistuje žádná možnost selektivní obnovy v cílové databázi nebo tabulce, kterou jste chtěli pouze obnovit. Pokud to chcete udělat, obnovte úplnou zálohu, je to snadné pomocí ClusterControl. Můžete přejít na karty Zálohování, jak je uvedeno níže,
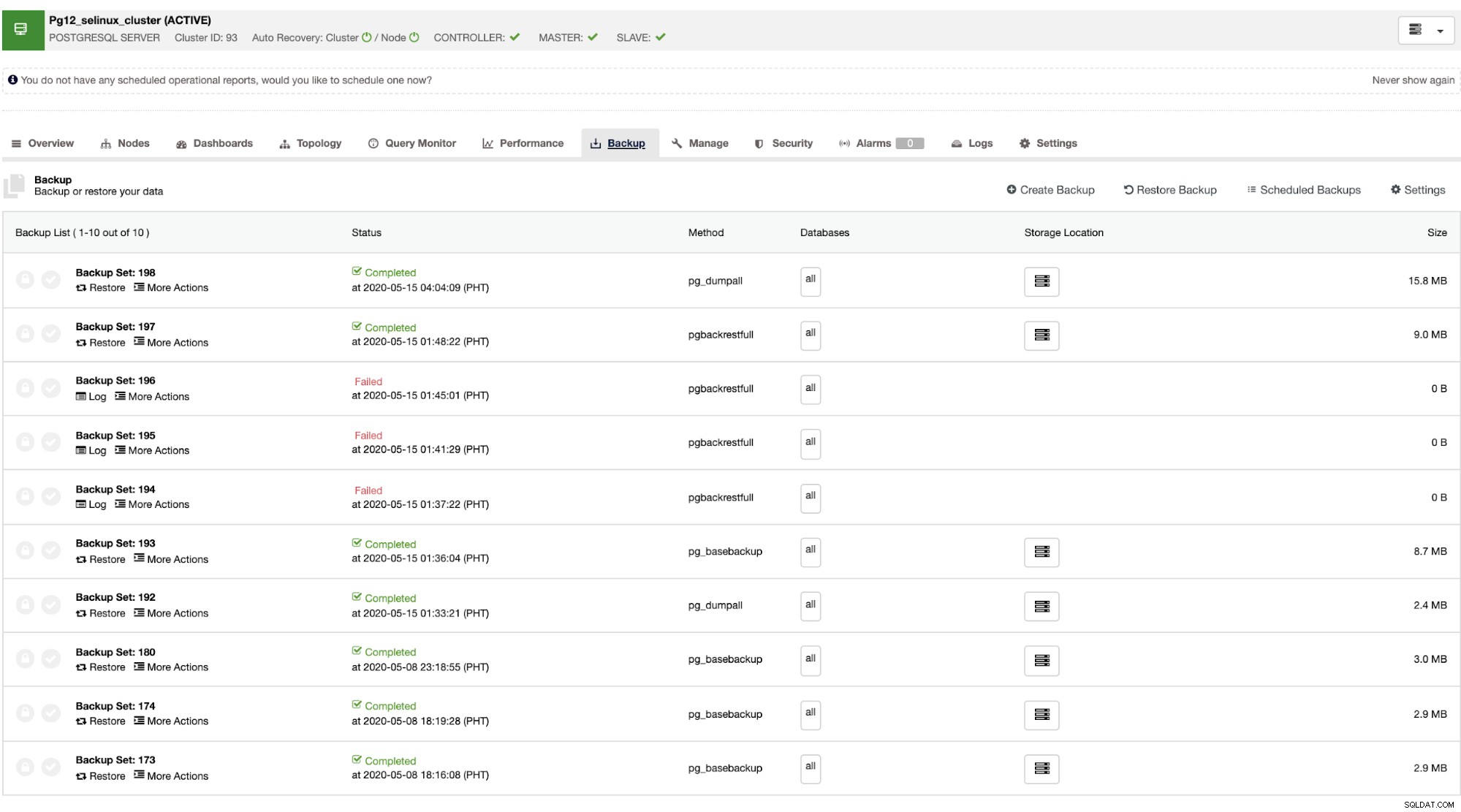
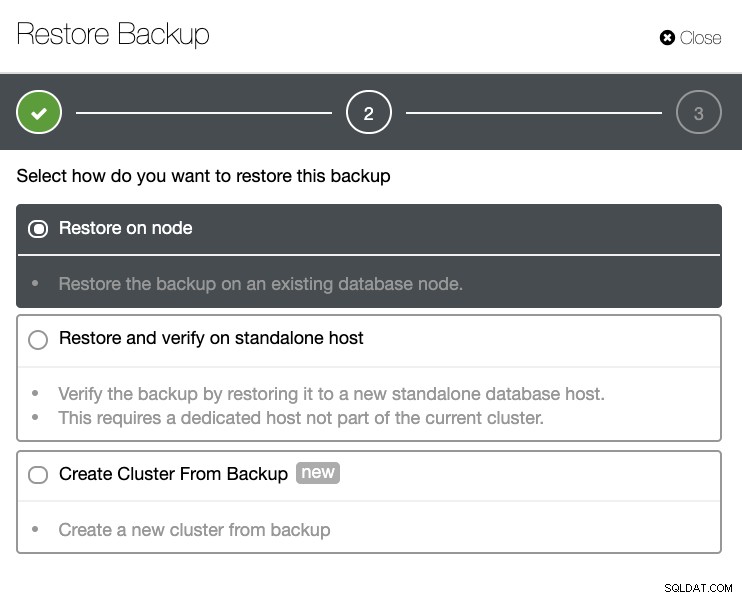
Budete mít úplný seznam úspěšných a neúspěšných záloh. Poté jej lze obnovit výběrem cílové zálohy a kliknutím na tlačítko „Obnovit“. To vám umožní obnovit na existujícím uzlu registrovaném v ClusterControl nebo ověřit na samostatném uzlu nebo vytvořit cluster ze zálohy.
Závěr
Použití pg_dump a pg_restore zjednodušuje přístup k zálohování/výpisu a obnově. V prostředí rozsáhlých databází to však nemusí být ideální komponenta pro obnovu po havárii. Pro minimální výběr a proceduru obnovy vám kombinace pg_dump a pg_restore poskytuje výkon pro výpis a načítání dat podle vašich potřeb.
Pro produkční prostředí (zejména pro podnikové architektury) můžete použít přístup ClusterControl k vytvoření zálohy a obnovení s automatickým obnovením.
Dobrým přístupem je také kombinace přístupů. To vám pomůže snížit vaše RTO a RPO a zároveň využít nejflexibilnější způsob obnovy dat v případě potřeby.