Jak jste si možná všimli z mého předchozího blogu, posledních pár měsíců bylo zaneprázdněných aktualizací Postgres-XL s nejnovější verzí PostgreSQL 9.5. Jakmile jsme měli přiměřeně stabilní verzi Postgres-XL 9.5, přesunuli jsme naši pozornost na měření výkonu této zcela nové verze Postgres-XL. Náš výběr benchmarku je do značné míry ovlivněn pokračující prací na projektu AXLE, financovaném Evropskou unií na základě grantové smlouvy 318633. Vzhledem k tomu, že používáme TPC BENCHMARK™ H k měření výkonu veškeré další práce provedené v rámci tohoto projektu, rozhodli jsme se použijte stejný benchmark pro hodnocení Postgres-XL. Vyhovuje také Postgres-XL, protože TPC-H se snaží měřit zátěž OLAP, což by Postgres-XL mělo dělat dobře.
1. Nastavení clusteru Postgres-XL
Jakmile bylo rozhodnuto o benchmarku, další velkou výzvou bylo najít správné zdroje pro testování. Neměli jsme přístup k velkému shluku fyzických strojů. Takže jsme udělali to, co by udělala většina. Rozhodli jsme se použít Amazon AWS pro nastavení clusteru Postgres-XL. AWS nabízí širokou škálu instancí, přičemž každý typ instance nabízí jiný výpočetní nebo IO výkon.
Tato stránka na AWS zobrazuje různé dostupné typy instancí, dostupné zdroje a jejich ceny pro různé oblasti. Je třeba poznamenat, že ceny a dostupnost se mohou lišit region od regionu, takže je důležité, abyste si prohlédli všechny regiony. Protože Postgres-XL vyžaduje nízkou latenci a vysokou propustnost mezi svými komponentami, je také důležité vytvořit instanci všech instancí ve stejné oblasti. Pro naše 3TB TPC-H jsme se rozhodli použít 16-datanode cluster instancí i2.xlarge AWS. Tyto instance mají 4 vCPU, 30 GB RAM a 800 GB SSD každý, dostatečné úložiště pro uchování všech distribuovaných tabulek, replikované tabulky (které zabírají více místa s rostoucí velikostí clusteru), indexy na nich a stále dostatek volného místa. v dočasném tabulkovém prostoru pro CREATE INDEX a další dotazy.
2. Nastavení benchmarku
2.1 TPC Benchmark™ H
Benchmark obsahuje 22 dotazů s cílem zkoumat velké objemy dat, provádět dotazy s vysokou mírou složitosti a poskytovat odpovědi na kritické obchodní otázky. Rádi bychom poznamenali, že kompletní specifikace TPC Benchmark™ H se zabývá řadou testů, jako je zátěž, výkon a propustnost testy. Pro naše testování jsme spustili pouze jednotlivé dotazy, nikoli kompletní testovací sadu. TPC Benchmark™ H se skládá ze sady obchodních dotazů navržených k uplatnění systémových funkcí způsobem reprezentujícím komplexní aplikace pro obchodní analýzu. Tyto dotazy dostaly realistický kontext, zobrazující činnost velkoobchodního dodavatele, aby pomohl čtenáři intuitivně se orientovat ve složkách benchmarku.
2.2 Databázové entity, vztahy a charakteristiky
Komponenty databáze TPC-H jsou definovány tak, že se skládají z osmi samostatných a samostatných tabulek (základních tabulek). Vztahy mezi sloupci těchto tabulek jsou znázorněny v následujícím diagramu. 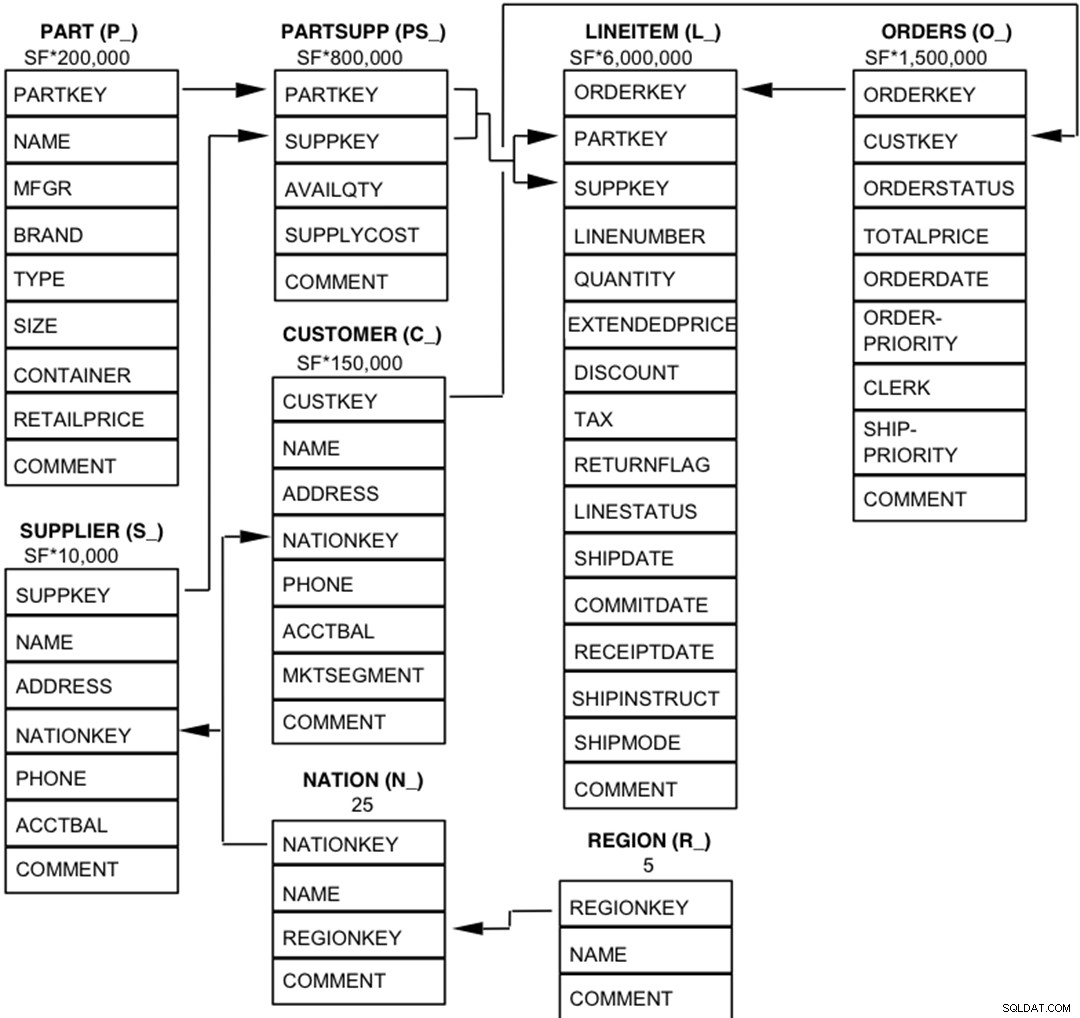 Legenda :
Legenda :
- Závorky za každým názvem tabulky obsahují předponu názvů sloupců pro danou tabulku;
- Šipky ukazují ve směru vztahů jedna k mnoha mezi tabulkami
- Číslo/vzorec pod každým názvem tabulky představuje mohutnost (počet řádků) tabulky. Některé jsou faktorizovány pomocí SF, měřítka, aby se získala zvolená velikost databáze. Mohutnost tabulky LINEITEM je přibližná
2.3 Distribuce dat pro Postgres-XL
Analyzovali jsme všech 22 dotazů v benchmarku a přišli s následující strategií distribuce dat pro různé tabulky v benchmarku.
| Název tabulky | Strategie distribuce |
| LINEITEM | HASH (l_orderkey) |
| OBJEDNÁVKY | HASH (o_orderkey) |
| ČÁST | HASH (p_partkey) |
| PARTSUPP | HASH (ps_partkey) |
| ZÁKAZNÍK | REPLIKOVANÉ |
| DODAVATEL | REPLIKOVANÉ |
| NÁROD | REPLIKOVANÉ |
| REGION | REPLIKOVANÉ |
Všimněte si, že LINEITEM a ORDERS, které jsou největšími tabulkami v benchmarku, jsou často spojeny v ORDERKEY. Je tedy velmi smysluplné tyto tabulky uspořádat do klíče ORDERKEY. Podobně jsou PART a PARTSUPP často spojeny na PARTKEY, a proto jsou umístěny ve sloupci PARTKEY. Zbytek tabulek je replikován, aby bylo zajištěno, že je lze v případě potřeby místně spojit.
3. Výsledky srovnání
3.1 Test zátěže
Porovnali jsme výsledky získané spuštěním 3TB zátěžového testu TPC-H na PostgreSQL 9.6 s 16uzlovým clusterem Postgres-XL. Následující grafy ukazují výkonnostní charakteristiky Postgres-XL.
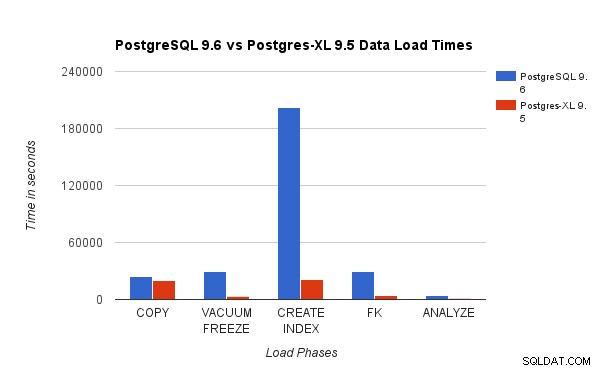 Výše uvedený graf ukazuje čas potřebný k dokončení různých fází zátěžového testu s PostgreSQL a Postgres-XL. Jak je vidět, Postgres-XL funguje o něco lépe pro COPY a mnohem lépe pro všechny ostatní případy. Poznámka :Zjistili jsme, že koordinátor vyžaduje během fáze COPY hodně výpočetního výkonu, zvláště když současně běží více než jeden stream COPY. Aby se to vyřešilo, byl koordinátor spuštěn na výpočetně optimalizované instanci AWS s 16 vCPU. Alternativně jsme také mohli spustit více koordinátorů a rozdělit mezi ně výpočetní zátěž.
Výše uvedený graf ukazuje čas potřebný k dokončení různých fází zátěžového testu s PostgreSQL a Postgres-XL. Jak je vidět, Postgres-XL funguje o něco lépe pro COPY a mnohem lépe pro všechny ostatní případy. Poznámka :Zjistili jsme, že koordinátor vyžaduje během fáze COPY hodně výpočetního výkonu, zvláště když současně běží více než jeden stream COPY. Aby se to vyřešilo, byl koordinátor spuštěn na výpočetně optimalizované instanci AWS s 16 vCPU. Alternativně jsme také mohli spustit více koordinátorů a rozdělit mezi ně výpočetní zátěž.
3.2 Test napájení
Porovnali jsme také doby běhu dotazu pro benchmark 3 TB na PostgreSQL 9.6 a Postgres-XL 9.5. Následující graf ukazuje výkonnostní charakteristiky provádění dotazu ve dvou nastaveních.
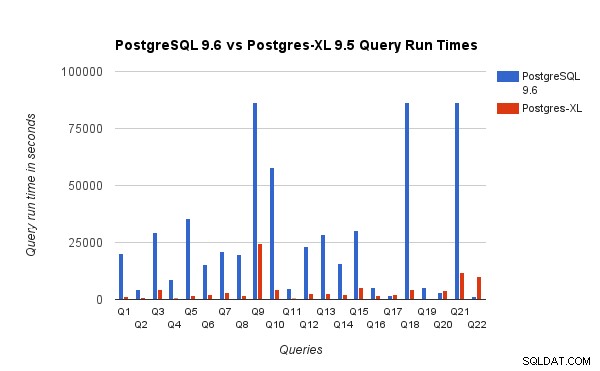 Zjistili jsme, že dotazy běžely v Postgres-XL v průměru asi 6,4krát rychleji a alespoň 25 % dotazů ukázaly téměř lineární zlepšení výkonu, jinými slovy, na tomto 16uzlovém clusteru Postgres-XL fungovaly téměř 16krát rychleji. Navíc nejméně 50 % dotazů vykazovalo 10násobné zlepšení výkonu. Dále jsme analyzovali výkon dotazů a došli jsme k závěru, že dotazy, které jsou dobře rozděleny mezi všechny dostupné datové uzly, takže mezi uzly dochází k minimální výměně dat a bez opakovaných vzdálených volání, se v Postgres-XL velmi dobře škálují. Takové dotazy mají obvykle nahoře uzel Remote Subquery Scan a podstrom pod uzlem se provádí na jednom nebo více uzlech paralelně. Je také běžné, že nad uzlem Remote Subquery Scan jsou některé další uzly, jako je uzel Limit nebo Aggregate. I takové dotazy fungují na Postgres-XL velmi dobře. Dotaz Q1 je příkladem dotazu, který by se měl velmi dobře škálovat s Postgres-XL. Na druhou stranu, dotazy, které vyžadují spoustu výměn n-tic mezi datanode-datanode a/nebo koordinátor-datanode, nemusí v Postgres-XL fungovat dobře. Podobně také dotazy, které vyžadují mnoho připojení mezi uzly, mohou vykazovat špatný výkon. Například si všimnete, že výkon Q22 je špatný ve srovnání s jednouzlovým PostgreSQL serverem. Když jsme analyzovali plán dotazů pro Q22, zjistili jsme, že v plánu dotazů jsou tři úrovně vnořených uzlů vzdáleného skenování poddotazů, kde každý uzel otevírá stejný počet připojení k datovým uzlům. Nest Loop Anti Join má dále vnitřní vztah s uzlem Remote Subquery Scan nejvyšší úrovně, a proto musí pro každou n-tici vnějšího vztahu provést vzdálený dílčí dotaz. To má za následek slabý výkon provádění dotazu.
Zjistili jsme, že dotazy běžely v Postgres-XL v průměru asi 6,4krát rychleji a alespoň 25 % dotazů ukázaly téměř lineární zlepšení výkonu, jinými slovy, na tomto 16uzlovém clusteru Postgres-XL fungovaly téměř 16krát rychleji. Navíc nejméně 50 % dotazů vykazovalo 10násobné zlepšení výkonu. Dále jsme analyzovali výkon dotazů a došli jsme k závěru, že dotazy, které jsou dobře rozděleny mezi všechny dostupné datové uzly, takže mezi uzly dochází k minimální výměně dat a bez opakovaných vzdálených volání, se v Postgres-XL velmi dobře škálují. Takové dotazy mají obvykle nahoře uzel Remote Subquery Scan a podstrom pod uzlem se provádí na jednom nebo více uzlech paralelně. Je také běžné, že nad uzlem Remote Subquery Scan jsou některé další uzly, jako je uzel Limit nebo Aggregate. I takové dotazy fungují na Postgres-XL velmi dobře. Dotaz Q1 je příkladem dotazu, který by se měl velmi dobře škálovat s Postgres-XL. Na druhou stranu, dotazy, které vyžadují spoustu výměn n-tic mezi datanode-datanode a/nebo koordinátor-datanode, nemusí v Postgres-XL fungovat dobře. Podobně také dotazy, které vyžadují mnoho připojení mezi uzly, mohou vykazovat špatný výkon. Například si všimnete, že výkon Q22 je špatný ve srovnání s jednouzlovým PostgreSQL serverem. Když jsme analyzovali plán dotazů pro Q22, zjistili jsme, že v plánu dotazů jsou tři úrovně vnořených uzlů vzdáleného skenování poddotazů, kde každý uzel otevírá stejný počet připojení k datovým uzlům. Nest Loop Anti Join má dále vnitřní vztah s uzlem Remote Subquery Scan nejvyšší úrovně, a proto musí pro každou n-tici vnějšího vztahu provést vzdálený dílčí dotaz. To má za následek slabý výkon provádění dotazu.
4. Několik lekcí AWS
Při srovnávání Postgres-XL jsme se naučili několik lekcí o používání AWS. Mysleli jsme si, že budou užitečné pro každého, kdo chce používat/testovat Postgres-XL na AWS.
- AWS nabízí několik různých typů instancí. Před výběrem konkrétního typu instance musíte pečlivě vyhodnotit své pracovní zatížení a množství požadovaného úložiště.
- Většina instancí optimalizovaných pro úložiště má připojené dočasné disky. Za tyto disky nemusíte platit nic navíc, jsou připojeny k instanci a často fungují lépe než EBS. Ale musíte je explicitně připojit, abyste je mohli používat. Mějte však na paměti, že data uložená na těchto discích nejsou trvalá a při zastavení instance budou vymazána. Ujistěte se tedy, že jste připraveni tuto situaci zvládnout. Protože jsme AWS používali převážně pro benchmarking, rozhodli jsme se použít tyto pomíjivé disky.
- Pokud používáte EBS, ujistěte se, že jste zvolili vhodné Provisioned IOPS. Příliš nízká hodnota způsobí velmi pomalé IO, ale velmi vysoká hodnota může výrazně zvýšit váš účet za AWS, zejména při práci s velkým počtem uzlů.
- Ujistěte se, že spouštíte instance ve stejné zóně, abyste snížili latenci a zlepšili propustnost spojení mezi nimi.
- Ujistěte se, že nakonfigurujete instance tak, aby ke vzájemné komunikaci využívaly privátní síť.
- Podívejte se na konkrétní případy. Jsou relativně levnější. Protože AWS může libovolně ukončit spotové instance, například pokud okamžitá cena překročí vaši maximální nabídkovou cenu, buďte na to připraveni. Postgres-XL se může stát částečně nebo úplně nepoužitelným v závislosti na tom, které uzly jsou ukončeny. AWS podporuje koncept launch_group. Pokud je více instancí seskupeno do stejné spouštěcí_skupiny, pokud se AWS rozhodne ukončit jednu instanci, budou ukončeny všechny instance.
5. Závěr
Prostřednictvím různých benchmarků jsme schopni prokázat, že Postgres-XL dokáže opravdu dobře škálovat pro velkou sadu komplexních dotazů v reálném světě. Tyto benchmarky nám pomáhají demonstrovat schopnost Postgres-XL jako efektivní řešení pro pracovní zátěže OLAP. Naše experimenty také ukazují, že s Postgres-XL existují určité problémy s výkonem, zejména u velmi velkých clusterů a když plánovač zvolí plán špatně. Také jsme pozorovali, že když existuje velký počet souběžných připojení k datovému uzlu, výkon se zhoršuje. Na těchto problémech s výkonem budeme nadále pracovat. Rádi bychom také otestovali schopnost Postgres-XL jako řešení OLTP pomocí vhodných pracovních zátěží.