Možná jste již slyšeli o termínu „rozdělený mozek“. co to je Jak to ovlivní vaše klastry? V tomto příspěvku na blogu probereme, co to přesně je, jaké nebezpečí může představovat pro vaši databázi, jak tomu můžeme zabránit a pokud se vše pokazí, jak se z toho zotavit.
Dávno pryč jsou časy jednotlivých instancí, dnes téměř všechny databáze běží v replikačních skupinách nebo clusterech. To je skvělé pro vysokou dostupnost a škálovatelnost, ale distribuovaná databáze přináší nová nebezpečí a omezení. Jedním případem, který může být smrtelný, je rozdělení sítě. Představte si shluk více uzlů, který byl kvůli problémům se sítí rozdělen na dvě části. Ze zřejmých důvodů (konzistence dat) by obě části neměly zpracovávat provoz současně, protože jsou od sebe izolované a nelze mezi nimi přenášet data. Je to také špatně z aplikačního hlediska – i když by nakonec existoval způsob, jak data synchronizovat (ačkoli sladění 2 datových sad není triviální). Na chvíli by část aplikace nevěděla o změnách provedených jinými hostiteli aplikace, kteří přistupují k druhé části databázového clusteru. To může vést k vážným problémům.
Stav, kdy byl shluk rozdělen na dvě nebo více částí, které jsou ochotny přijímat zápisy, se nazývá „rozdělený mozek“.
Největší problém s rozděleným mozkem je datový drift, protože zápis probíhá na obou částech clusteru. Žádná z variant MySQL neposkytuje automatizované prostředky pro slučování datových sad, které se rozcházely. Takovou funkci nenajdete v replikaci MySQL, skupinové replikaci nebo Galeře. Jakmile se data rozcházejí, jedinou možností je buď použít jednu z částí clusteru jako zdroj pravdy a zahodit změny provedené na druhé části – pokud nemůžeme provést nějaký ruční proces ke sloučení dat.
Proto začneme tím, jak zabránit rozdělení mozku. Je to mnohem snazší než opravovat jakoukoli nesrovnalost v datech.
Jak zabránit rozdělení mozku
Přesné řešení závisí na typu databáze a nastavení prostředí. Podíváme se na některé z nejběžnějších případů pro Galera Cluster a MySQL Replication.
Galera Cluster
Galera má vestavěný „jistič“, který zvládne rozdělený mozek:spoléhá na mechanismus kvora. Pokud je v clusteru k dispozici většina (50 % + 1) uzlů, Galera bude fungovat normálně. Pokud nebude většina, Galera přestane obsluhovat provoz a přejde do tzv. „neprimárního“ stavu. To je v podstatě vše, co potřebujete k řešení situace rozděleného mozku při používání Galery. Jistě, existují manuální metody, jak přinutit Galeru do „primárního“ stavu, i když tam není většina. Jde o to, že pokud to neuděláte, měli byste být v bezpečí.
Způsob, jakým se počítá kvorum, má důležité důsledky – na úrovni jednoho datového centra chcete mít lichý počet uzlů. Tři uzly vám poskytují toleranci pro selhání jednoho uzlu (2 uzly splňují požadavek, aby bylo k dispozici více než 50 % uzlů v clusteru). Pět uzlů vám poskytne toleranci pro selhání dvou uzlů (5 - 2 =3, což je více než 50 % z 5 uzlů). Na druhou stranu použití čtyř uzlů nezlepší vaši toleranci oproti shluku tří uzlů. Stále by to zvládlo pouze selhání jednoho uzlu (4 - 1 =3, více než 50 % ze 4), zatímco selhání dvou uzlů způsobí, že cluster bude nepoužitelný (4 - 2 =2, pouze 50 %, ne více).
Při nasazování clusteru Galera v jediném datovém centru mějte na paměti, že v ideálním případě byste chtěli distribuovat uzly do více zón dostupnosti (samostatný zdroj napájení, síť atd.) – pokud existují ve vašem datovém centru, tzn. . Jednoduché nastavení může vypadat takto:
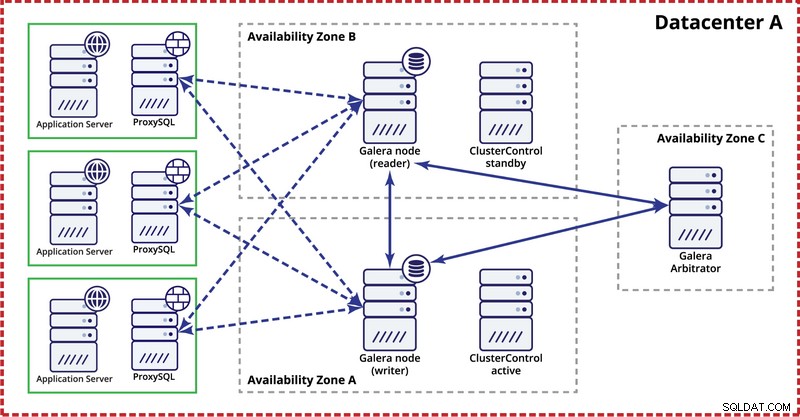
Na úrovni více datových center jsou tyto úvahy také použitelné. Pokud chcete, aby cluster Galera automaticky zpracovával selhání datových center, měli byste použít lichý počet datových center. Pro snížení nákladů můžete místo databázového uzlu použít v jednom z nich arbitrátor Galera. Galera arbitrator (garbd) je proces, který se účastní výpočtu kvora, ale neobsahuje žádná data. Díky tomu je možné jej používat i na velmi malých instancích, protože není náročný na zdroje – i když síťové připojení musí být dobré, protože „vidí“ veškerý provoz replikace. Příklad nastavení může vypadat na obrázku níže:
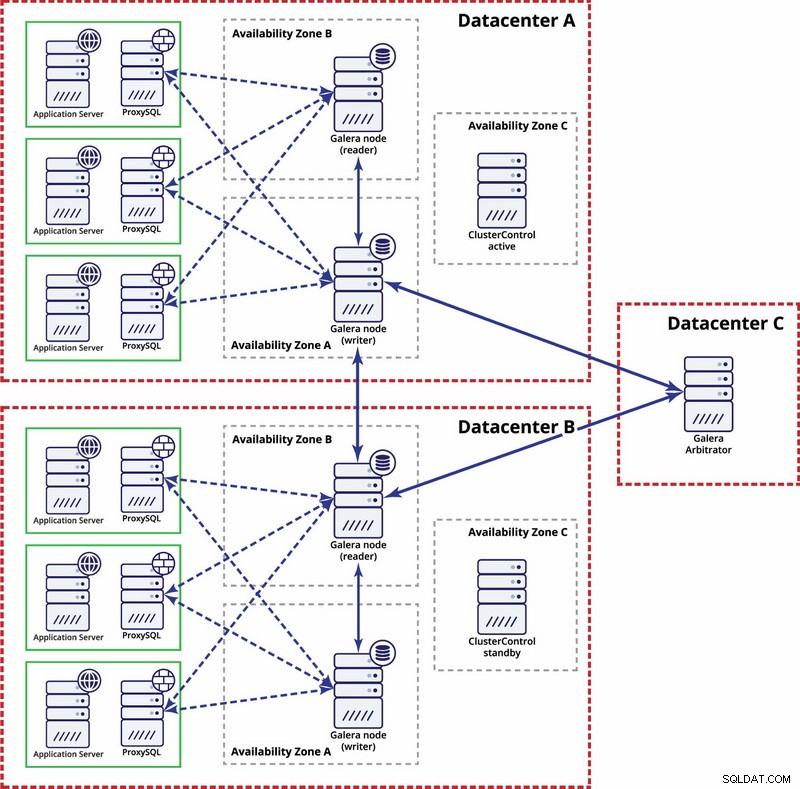
Replikace MySQL
U replikace MySQL je největším problémem to, že není vestavěn žádný mechanismus kvora, jako je tomu v clusteru Galera. Proto je zapotřebí více kroků, abyste zajistili, že vaše nastavení nebude ovlivněno rozděleným mozkem.
Jednou z metod je vyhnout se automatizovaným převzetím služeb při selhání napříč datovými centry. Své řešení převzetí služeb při selhání (může to být prostřednictvím ClusterControl nebo MHA nebo Orchestrator) můžete nakonfigurovat na převzetí služeb při selhání pouze v rámci jednoho datového centra. Pokud by došlo k úplnému výpadku datového centra, bylo by na správci, aby rozhodl, jak provést převzetí služeb při selhání a jak zajistit, že servery v datovém centru, které selhalo, nebudou použity.
Existují možnosti, jak to zautomatizovat. Pomocí Consul můžete uložit data o uzlech v nastavení replikace a o tom, který z nich je hlavní. Pak bude na adminovi (nebo pomocí nějakého skriptování), aby aktualizoval tento záznam a přesunul zápisy do druhého datacentra. Můžete těžit z nastavení Orchestrator/Raft, kde mohou být uzly Orchestrator distribuovány do více datových center a detekovat rozdělený mozek. Na základě toho můžete podniknout různé akce, jako, jak jsme již zmínili, aktualizovat záznamy v našem konzulovi nebo atd. Jde o to, že toto je mnohem složitější prostředí pro nastavení a automatizaci než cluster Galera. Níže naleznete příklad nastavení více datových center pro replikaci MySQL.
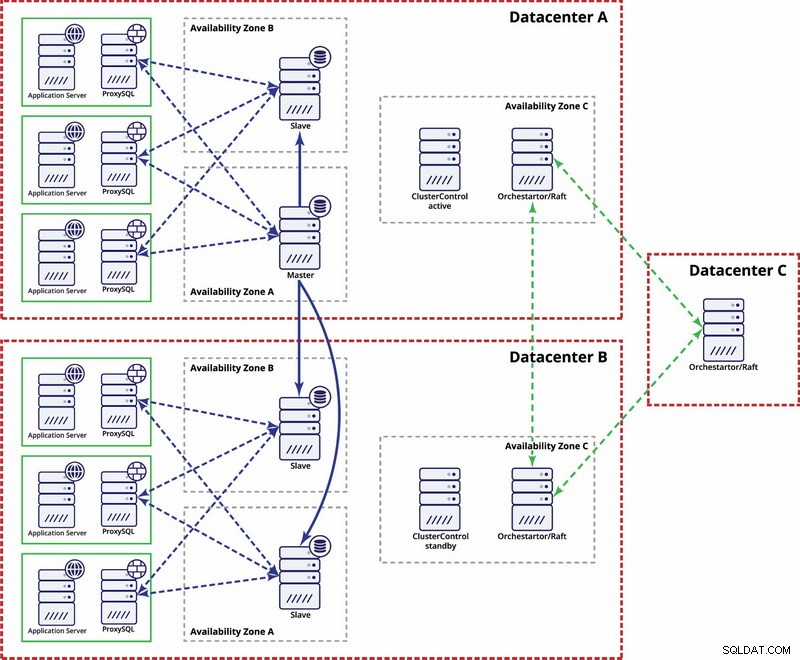
Mějte prosím na paměti, že stále musíte vytvářet skripty, aby to fungovalo, tj. monitorovat uzly Orchestrator pro rozdělený mozek a podniknout nezbytné kroky k implementaci STONITH a zajistit, že master v datovém centru A nebude použit, jakmile dojde ke konvergování sítě a konektivitě. být obnoven.
Došlo k rozdělení mozku – co dělat dál?
Nastal nejhorší možný scénář a dochází k posunu dat. Pokusíme se vám dát několik tipů, co se zde dá dělat. Bohužel přesné kroky budou záviset většinou na vašem návrhu schématu, takže nebude možné napsat přesný návod.
Musíte mít na paměti, že konečným cílem bude zkopírovat data z jednoho hlavního serveru do druhého a znovu vytvořit všechny vztahy mezi tabulkami.
Nejprve musíte určit, který uzel bude nadále poskytovat data jako hlavní. Jedná se o datovou sadu, do které sloučíte data uložená v jiné „hlavní“ instanci. Jakmile to uděláte, musíte identifikovat data ze starého masteru, která na aktuálním masteru chybí. To bude ruční práce. Pokud máte v tabulkách časová razítka, můžete je využít k přesnému určení chybějících dat. V konečném důsledku budou binární protokoly obsahovat všechny úpravy dat, takže se na ně můžete spolehnout. Možná se také budete muset spolehnout na své znalosti datové struktury a vztahů mezi tabulkami. Pokud jsou vaše data normalizována, jeden záznam v jedné tabulce by mohl souviset se záznamy v jiných tabulkách. Vaše aplikace může například vkládat data do tabulky „user“, která souvisí s tabulkou „address“ pomocí user_id. Budete muset najít všechny související řádky a extrahovat je.
Dalším krokem bude načtení těchto dat do nového masteru. Zde přichází ta záludná část – pokud jste si nastavení připravili předem, mohlo by to být jednoduše otázkou spuštění několika vložek. Pokud ne, může to být poměrně složité. Je to všechno o primárním klíči a jedinečných hodnotách indexu. Pokud jsou hodnoty vašeho primárního klíče generovány jako jedinečné na každém serveru pomocí nějakého generátoru UUID nebo pomocí nastavení auto_increment_increment a auto_increment_offset v MySQL, můžete si být jisti, že data ze starého hlavního klíče, která musíte vložit, nezpůsobí primární klíč ani jedinečný. klíč je v konfliktu s daty na novém masteru. V opačném případě budete možná muset ručně upravit data ze starého vzoru, abyste se ujistili, že je lze vložit správně. Zní to složitě, takže se podívejme na příklad.
Představme si, že vkládáme řádky pomocí auto_increment na uzel A, který je hlavní. Pro jednoduchost se zaměříme pouze na jeden řádek. Jsou zde sloupce 'id' a 'value'.
Pokud jej vložíme bez konkrétního nastavení, uvidíme záznamy jako níže:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Ty se replikují na slave (B). Pokud dojde k rozdělení mozku a zápisy budou provedeny na starém i novém masteru, skončíme s následující situací:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Jak vidíte, neexistuje způsob, jak jednoduše vypsat záznamy s ID 1004, 1005 a 1006 z uzlu A a uložit je do uzlu B, protože skončíme s duplicitními položkami primárního klíče. Co je třeba udělat, je změnit hodnoty sloupce id v řádcích, které budou vloženy, na hodnotu větší, než je maximální hodnota sloupce id z tabulky. To je vše, co je potřeba pro jednotlivé řádky. U složitějších vztahů, kde se jedná o více tabulek, budete možná muset provést změny na více místech.
Na druhou stranu, kdybychom tento potenciální problém předvídali a konfigurovali naše uzly tak, aby ukládaly lichá id v uzlu A a sudá id v uzlu B, bylo by řešení problému mnohem snazší.
Uzel A byl nakonfigurován s auto_increment_offset =1 a auto_increment_increment =2
Uzel B byl nakonfigurován s auto_increment_offset =2 a auto_increment_increment =2
Takto by data vypadala na uzlu A před rozděleným mozkem:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Když dojde k rozdělení mozku, bude to vypadat jako níže.
Uzel A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Uzel B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Nyní můžeme snadno zkopírovat chybějící data z uzlu A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’A načtěte jej do uzlu B, čímž skončíte s následujícím souborem dat:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Jistě, řádky nejsou v původním pořadí, ale mělo by to být v pořádku. V nejhorším případě budete muset v dotazech seřadit podle sloupce „hodnota“ a možná do něj přidat index, aby se řazení urychlilo.
Nyní si představte stovky nebo tisíce řádků a vysoce normalizovanou strukturu tabulky – obnovení jednoho řádku může znamenat, že budete muset obnovit několik z nich v dalších tabulkách. S potřebou změnit ID (protože jste neměli nastavená ochranná nastavení) ve všech souvisejících řádcích a toto všechno je ruční práce, dokážete si představit, že to není ta nejlepší situace. Trvá čas, než se zotavíte a je to proces náchylný k chybám. Naštěstí, jak jsme diskutovali na začátku, existují prostředky, jak minimalizovat šance, že rozdělený mozek ovlivní váš systém, nebo jak snížit práci, kterou je třeba udělat pro zpětnou synchronizaci vašich uzlů. Ujistěte se, že je používáte, a buďte připraveni.