Replikace MariaDB je jedním z nejoblíbenějších řešení s vysokou dostupností pro MariaDB a je široce používána předními společnostmi, jako je Booking.com a Google. Je velmi snadné jej nastavit, s určitými kompromisy v průběžné údržbě, jako jsou aktualizace softwaru, změny schématu, změny topologie, převzetí služeb při selhání a obnova, které byly vždy složité. Nicméně se správnou sadou nástrojů byste měli být schopni snadno zvládnout topologii. V tomto příspěvku na blogu se podíváme na několik tipů, jak efektivně monitorovat replikaci MariaDB pomocí ClusterControl.
Použití prohlížeče topologie
Nastavení replikace se skládá z několika rolí. Uzel v nastavení replikace může být:
- Mistr – hlavní autor/čtenář.
- Backup master – podřízená jednotka pouze pro čtení s polosynchronizovanou replikací, pouze pro hlavní redundanci.
- Zprostředkující master – replikuje se z hlavního, zatímco ostatní podřízení se replikují z tohoto uzlu.
- Binlog server – Shromažďujte a ukládejte pouze binární protokoly bez poskytování dat.
- Slave – replikace z hlavního serveru a běžně nastavená pouze pro čtení.
- Multi-source slave – replikace z více masterů.
Každá role má svou vlastní odpovědnost a omezení a při práci s databázovými uzly je třeba rozumět správné topologii. To platí i pro aplikaci, kde aplikace musí v daném okamžiku zapisovat pouze do hlavního uzlu. Proto je důležité mít přehled o tom, který uzel zastává jakou roli, abychom si nepokazili databázi.
V ClusterControl vám Topology Viewer může poskytnout přehled topologie replikace a jejího stavu, jak ukazuje následující snímek obrazovky:
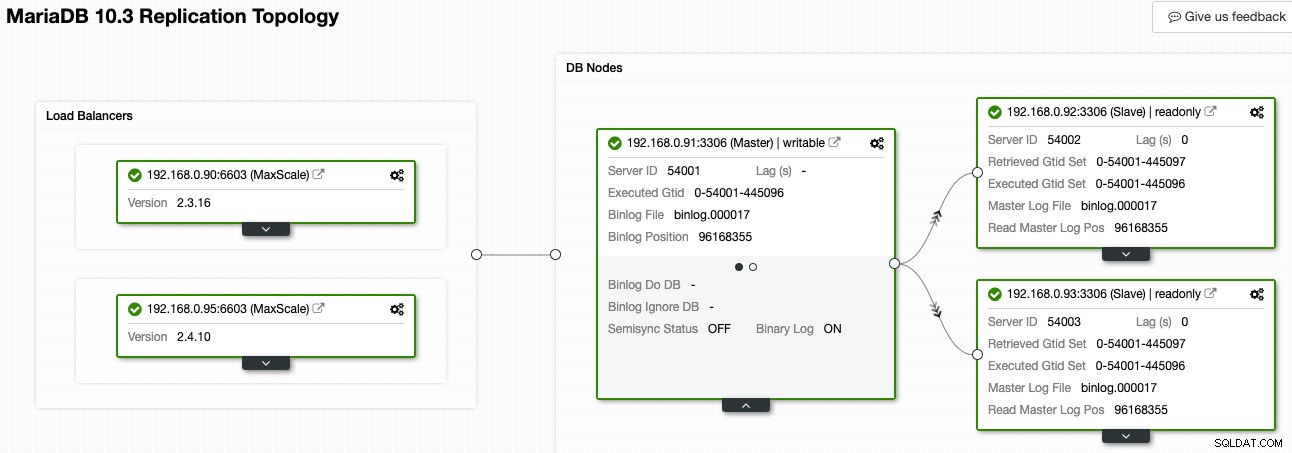
ClusterControl rozumí replikaci MariaDB a je schopen vizualizovat topologii se správným datovým tokem replikace, jak je znázorněno šipkami ukazujícími na podřízené uzly. V našem nastavení replikace můžeme snadno rozlišit, který uzel je master, slave a load balancers (MaxScale). Zelené pole označuje, že všechny důležité služby běží podle očekávání s přiřazenou rolí.
Zvažte následující snímek obrazovky, kde má řada našich uzlů problémy:
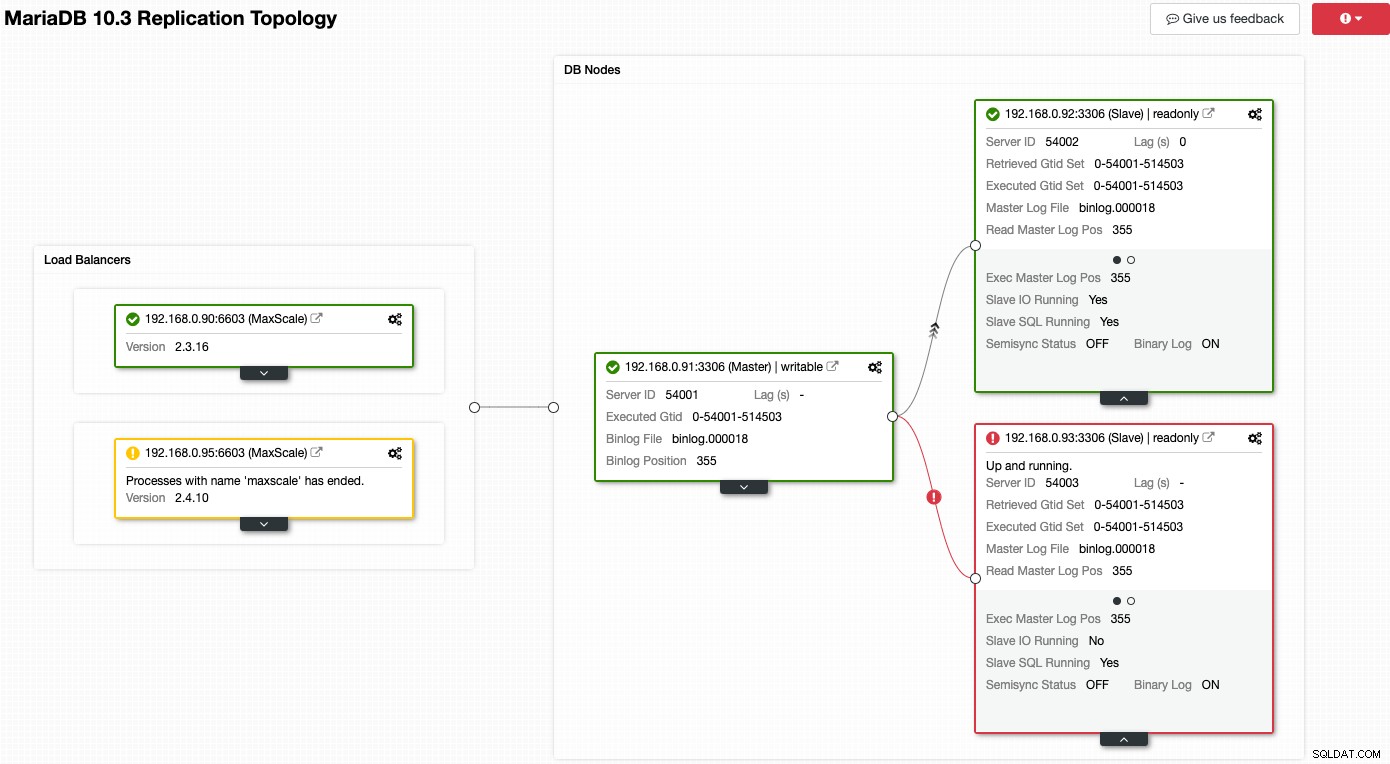
ClusterControl vám okamžitě řekne, co je s aktuální topologií špatně. Jeden z podřízených jednotek (červený rámeček) zobrazuje „Slave IO Running“ jako Ne, což znamená problém s připojením k replikaci z hlavní jednotky. Zatímco žluté pole ukazuje, že naše služba MaxScale není spuštěna. Můžeme také říci, že verze MaxScale nejsou identické pro oba uzly. Úlohy správy můžete také provádět přímo kliknutím na ikonu ozubeného kola (vpravo nahoře na každém poli), což snižuje riziko, že zachytíte nesprávný uzel.
Prodleva replikace
Toto je nejdůležitější, pokud spoléháte na konzistenci replikace dat. Ke zpoždění replikace dochází, když podřízené jednotky nemohou držet krok s aktualizacemi probíhajícími na hlavním serveru. Nepoužité změny se hromadí v protokolech přenosu podřízených zařízení a verze databáze na podřízených zařízeních se stále více liší od hlavní.
V ClusterControl najdete histogram zpoždění replikace v části Overview -> Replication Lag, kde ClusterControl neustále vzorkuje hodnotu Seconds_Behind_Master z výstupu "SHOW SLAVE STATUS":
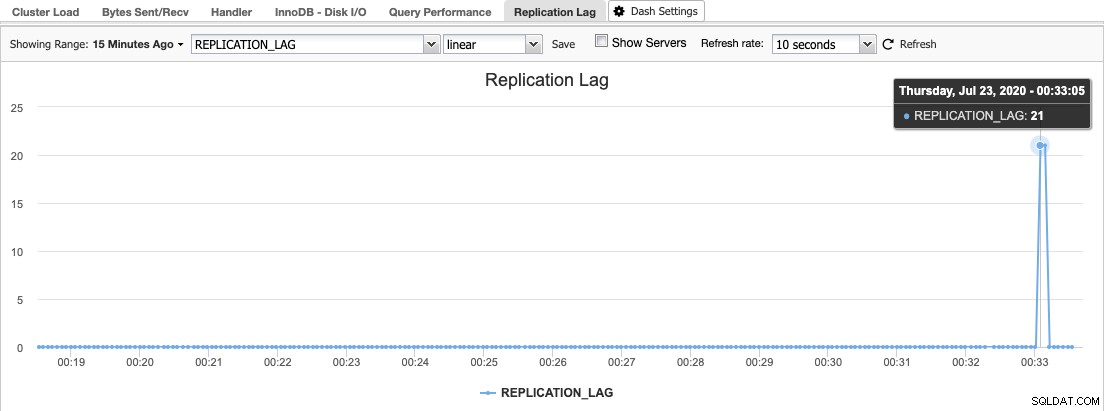
Zpoždění replikace nastane, když I/O vlákno nebo SQL vlákno nedokáže zvládnout požadavky, které jsou na něj kladeny. Pokud I/O vlákno trpí, znamená to, že síťové připojení mezi master a jeho slave je pomalé nebo má problémy. Můžete zvážit povolení slave_compressed_protocol pro komprimaci síťového provozu nebo hlášení správci sítě.
Pokud se jedná o vlákno SQL, pak je problém pravděpodobně způsoben špatně optimalizovanými dotazy, jejichž použití podřízenému zařízení trvá příliš dlouho. Mohou existovat dlouhotrvající transakce nebo příliš mnoho I/O aktivity. Neexistence primárního klíče na podřízených tabulkách při použití formátu replikace ROW nebo MIXED je také běžnou příčinou zpoždění v tomto vláknu. Zkontrolujte, zda verze master a slave tabulek mají primární klíč.
Některé další tipy a triky jsou obsaženy v tomto příspěvku na blogu Jak snížit zpoždění replikace v multi-cloudových nasazeních.
Velikost binárního/přenosového protokolu
Je důležité sledovat velikost disku binárních a přenosových protokolů, protože by to mohlo spotřebovat značné množství úložiště na každém uzlu v replikačním clusteru. Obvykle by se systémová proměnná expire_logs_days nastavila tak, aby vypršela platnost binárních souborů protokolu automaticky po daném počtu dní, například expire_logs_days=7. Velikost binárních protokolů je zcela závislá na počtu vytvořených binárních událostí (příchozích zápisů) a málo víme, kolik místa na disku by to spotřebovalo, než protokoly vyprší MariaDB. Mějte na paměti, že pokud povolíte log_slave_updates na podřízených zařízeních, velikost protokolů se téměř zdvojnásobí, protože na stejném serveru existují binární i přenosové protokoly.
Pro ClusterControl můžeme nastavit práh využití místa na disku pod ClusterControl -> Nastavení -> Prahové hodnoty, abychom dostali varování a kritická upozornění, jak je uvedeno níže:
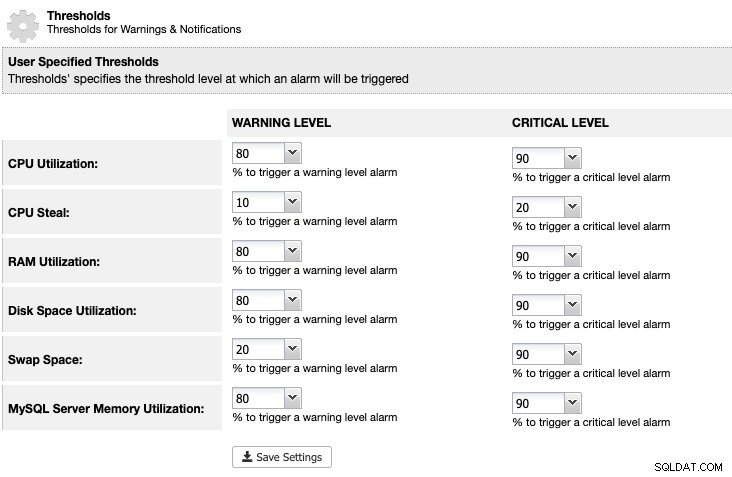
ClusterControl monitoruje veškerý diskový prostor související se službami MariaDB, jako je umístění dat MariaDB adresář, adresář binárních protokolů a také kořenový oddíl. Pokud jste dosáhli prahové hodnoty, zvažte ruční čištění binárních protokolů pomocí příkazu PURGE BINARY LOGS, jak je vysvětleno a diskutováno v tomto článku.
Povolit řídicí panely monitorování
ClusterControl poskytuje dvě možnosti monitorování pro vzorkování uzlů databáze – bez agenta nebo založené na agentovi. Výchozí hodnota je bez agenta, kde vzorkování probíhá prostřednictvím SSH v mechanismu pouze pro stahování. Monitorování založené na agentech vyžaduje, aby byl spuštěn server Prometheus a všechny monitorované uzly byly nakonfigurovány s alespoň třemi exportéry:
- Vývozce procesů (port 9011)
- Exportér metrik uzlů/systému (port 9100)
- Exportér MySQL/MariaDB (port 9104)
Chcete-li povolit řídicí panel monitorování založeného na agentech, musíte přejít do ClusterControl -> Dashboards -> Enable Agent Based Monitoring. Po aktivaci uvidíte sadu řídicích panelů nakonfigurovaných pro naši replikaci MariaDB, což nám poskytuje mnohem lepší přehled o našem nastavení replikace. Následující snímek obrazovky ukazuje, co byste viděli pro hlavní uzel:
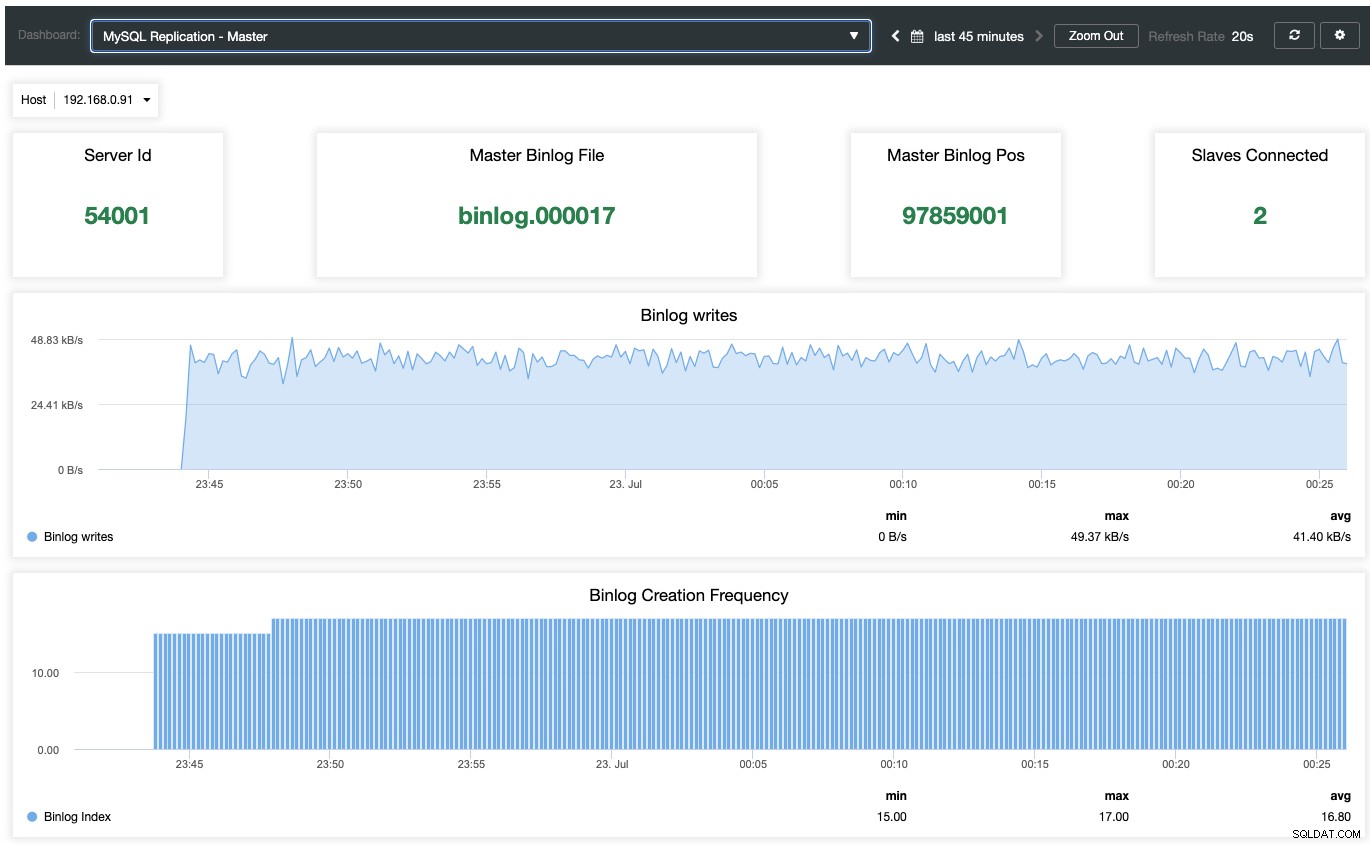
Kromě standardních monitorovacích panelů MariaDB, jako jsou obecné, mezipaměti a metriky InnoDB, budou prezentovány s řídicím panelem replikace. Pro hlavní uzel můžeme získat mnoho užitečných informací týkajících se stavu hlavního uzlu, propustnosti zápisu a frekvence vytváření binlogů.
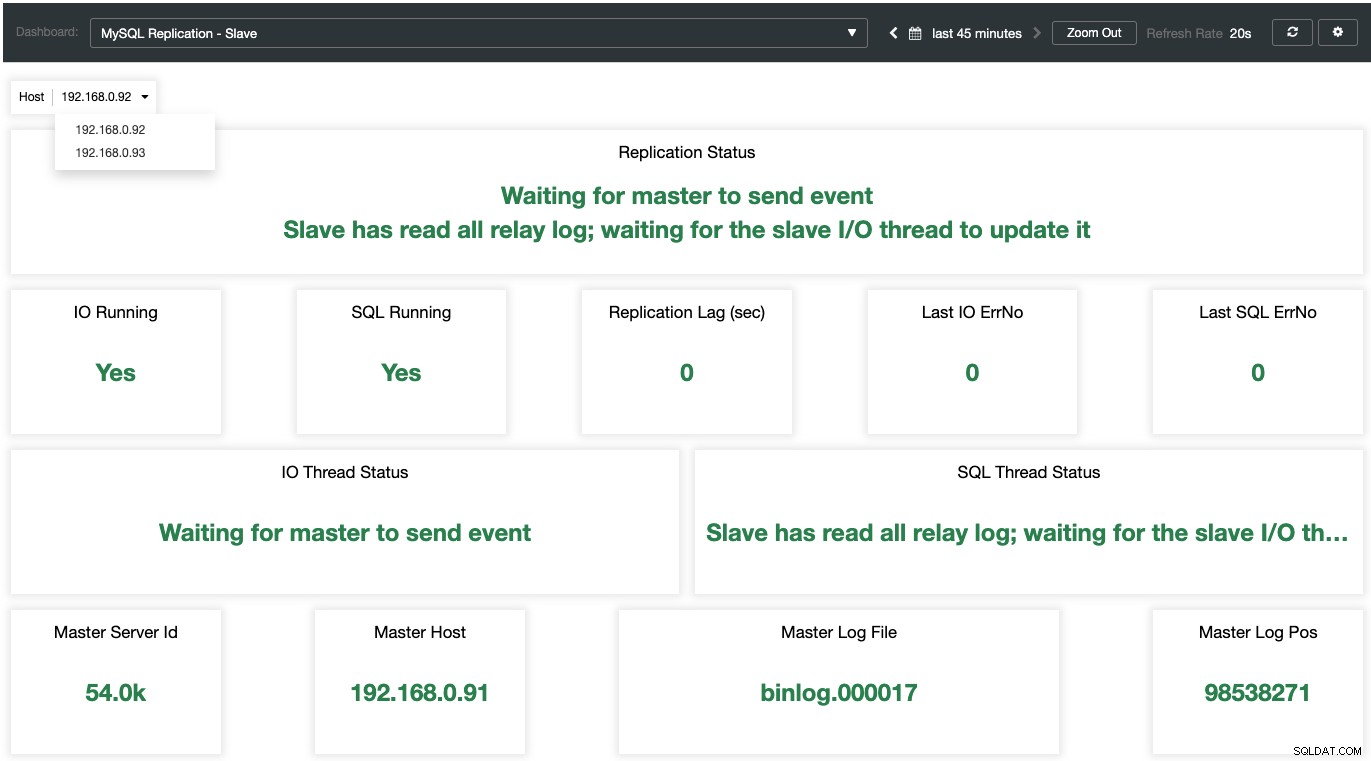
Zatímco u otroků jsou všechny důležité stavy ukázány a shrnuty jako následující snímek obrazovky. pokud je vše zelené, jste v dobrých rukou:
Porozumění protokolu chyb MariaDB
MariaDB zaznamenává své důležité události do protokolu chyb, což je užitečné pro pochopení toho, co se dělo se serverem, zejména před, během a po změně topologie. ClusterControl poskytuje centralizovaný pohled na chybové protokoly pod ClusterControl -> Protokoly -> Systémové protokoly jejich stahováním z každého databázového uzlu. Kliknutím na "Obnovit protokoly" spustíte úlohu pro stažení nejnovějších protokolů ze serveru.
Shromážděné soubory jsou zastoupeny v navigační stromové struktuře a textové oblasti se zvýrazněním syntaxe pro lepší čitelnost:
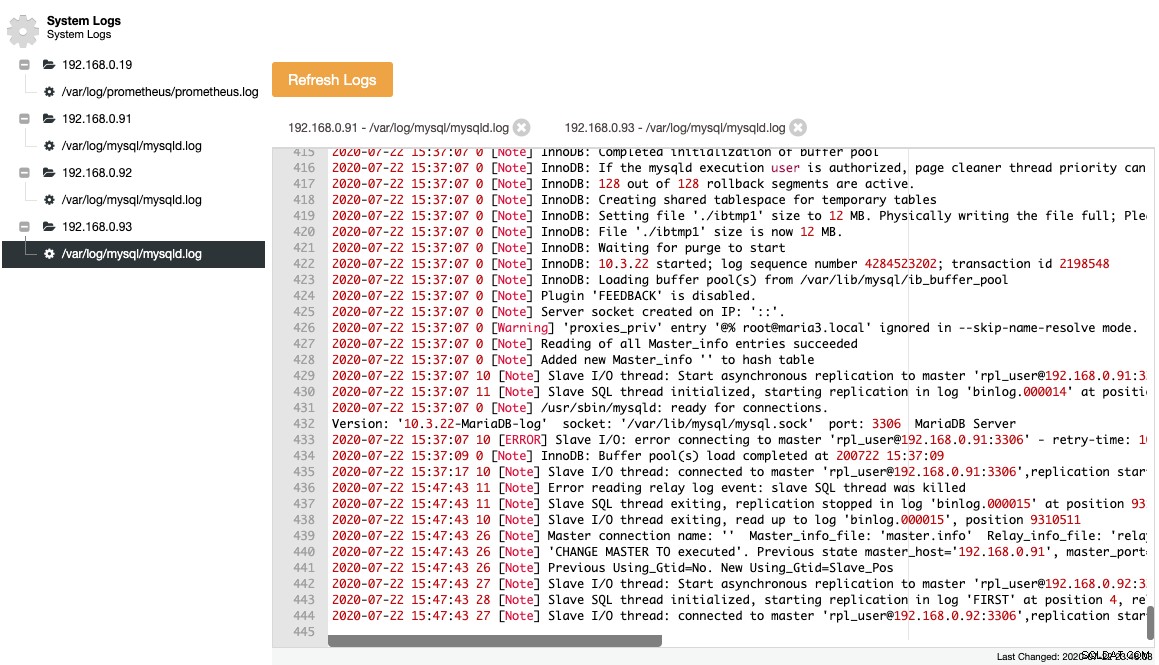
Z výše uvedeného snímku obrazovky můžeme pochopit sekvenci událostí a to, co se stalo s tímto uzlem během události změny topologie. Z posledních 12 řádků výše uvedeného chybového protokolu došlo k chybě podřízeného zařízení po připojení k hlavnímu zařízení a poslední binární soubor protokolu a pozice byly zaznamenány do protokolu před zastavením. Poté byl proveden novější příkaz CHANGE MASTER s informacemi GTID, jak je znázorněno na řádku "Předchozí Using_Gtid=No. New Using_Gtid=Slave_Pos" a poté se replikace obnoví tak, jak jsme chtěli.
Upozornění a oznámení MariaDB
Monitorování je bez upozornění a oznámení neúplné. Všechny události a alarmy generované ClusterControl lze odeslat e-mailem nebo jakýmkoli jiným podporovaným nástrojům třetích stran. U e-mailových upozornění lze nakonfigurovat, zda budou typy událostí doručeny okamžitě, ignorovány nebo zpracovány (denní souhrnný přehled):

U všech kritických událostí závažnosti se doporučuje nastavit vše na „Doručit“, abyste oznámení dostali co nejdříve. Nastavte „Digest“ na varovné události, abyste si byli dobře vědomi stavu a stavu clusteru.
Své preferované nástroje pro komunikaci a zasílání zpráv můžete integrovat do ClusterControl pomocí funkce Správa oznámení v části ClusterControl -> Integrace -> Oznámení třetích stran. ClusterControl může posílat alarmy a události do PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow nebo do jakéhokoli uživatelem registrovaného webhooku.
Následující snímek obrazovky ukazuje, že všechny kritické události budou odeslány do nakonfigurovaného kanálu telegramů pro náš cluster replikace MariaDB 10.3:

ClusterControl také podporuje integraci chatbota, kde můžete komunikovat se službou kontroléru prostřednictvím klienta s9s přímo z vašeho nástroje pro zasílání zpráv, jak je znázorněno v tomto příspěvku na blogu Automatizace vaší databáze pomocí CCBot:ClusterControl Hubot Integration.
Závěr
ClusterControl nabízí kompletní sadu proaktivních monitorovacích nástrojů pro vaše databázové clustery. Ke sledování nastavení replikace MariaDB používejte ClusterControl, protože většina monitorovacích funkcí je v komunitní edici k dispozici zdarma. Nenechte si je ujít!