Přehled
Oracle Data Mining (ODM) je součástí Oracle Advanced Analytics Database Option. ODM obsahuje sadu pokročilých algoritmů pro dolování dat, které jsou zabudovány do databáze, což vám umožňuje provádět pokročilou analýzu vašich dat.
Oracle Data Miner je rozšířením Oracle SQL Developer, grafického vývojového prostředí pro Oracle SQL. Oracle Data Miner využívá technologii dolování dat integrovanou v databázi Oracle k vytváření, provádění a správě pracovních postupů, které zahrnují operace dolování dat. Architektura ODM je znázorněna na obrázku 1.
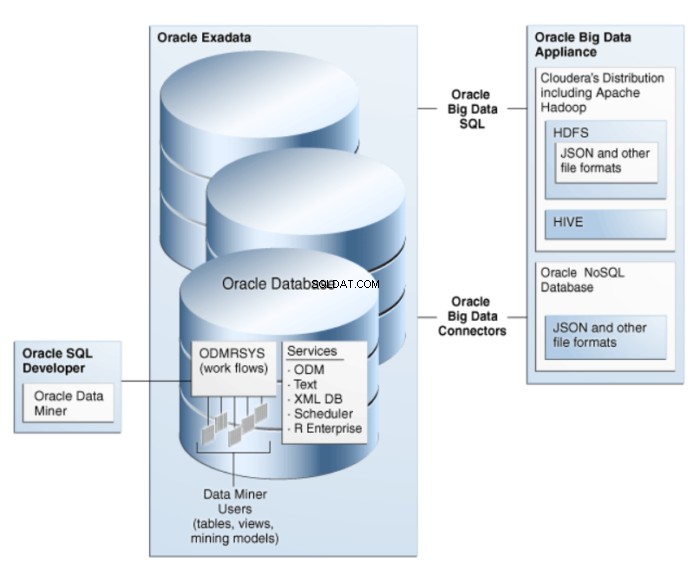
Obrázek 1:Architektura Oracle Data Mining Architecture pro velká data
Algoritmy jsou implementovány jako funkce SQL a využívají silné stránky databáze Oracle. Funkce dolování dat SQL mohou těžit transakční data, agregace, nestrukturovaná data, tj. datový typ CLOB (pomocí Oracle Text) a prostorová data.
Každá funkce dolování dat specifikuje třídu problémů, které lze modelovat a řešit. Funkce dolování dat obecně spadají do dvou kategorií:pod dohledem a bez dozoru.
Představy o učení pod dohledem a bez dozoru jsou odvozeny z vědy o strojovém učení, které se nazývá podoblastí umělé inteligence.
Učení pod dohledem je také známé jako řízené učení. Proces učení je řízen dříve známým závislým atributem nebo cílem. Řízené dolování dat se pokouší vysvětlit chování cíle jako funkci sady nezávislých atributů nebo prediktorů.
Učení bez dozoru je neřízené. Mezi závislými a nezávislými atributy není žádný rozdíl. Neexistuje žádný dříve známý výsledek, který by vedl algoritmus při sestavování modelu. Učení bez dozoru lze použít pro popisné účely.
Oracle Data Mining Supervised Algorithms
| Technika | Použitelnost | Algoritmy (stručný popis) |
|---|---|---|
Klasifikace | Nejčastěji používaná technika pro predikci konkrétního výsledku, například identifikace rakovinných nádorových buněk, analýza sentimentu, klasifikace léků, detekce spamu. | Zobecněné lineární modely Logistická regrese – klasická statistická technika dostupná v databázi Oracle ve vysoce výkonné, škálovatelné, paralizované implementaci (platí pro všechny algoritmy OAA ML). Podporuje textová a transakční data (platí pro téměř všechny algoritmy OAA ML) Naive Bayes – Rychlé, jednoduché, běžně použitelné. Podpora vektorového stroje – Algoritmus strojového učení, podporuje text a široká data. Strom rozhodnutí – Populární algoritmus ML pro interpretovatelnost. Poskytuje člověku čitelná „pravidla“. |
Regrese | Technika pro předpovídání kontinuálního numerického výsledku, jako je analýza astronomických dat, generování přehledů o chování spotřebitelů, ziskovosti a dalších obchodních faktorech, výpočet kauzálních vztahů mezi parametry v biologických systémech. | Zobecněné lineární modely Vícenásobná regrese – klasická statistická technika, která je nyní k dispozici v databázi Oracle jako vysoce výkonná, škálovatelná a paralyzovaná implementace. Podporuje ridge regresi, vytváření prvků a výběr prvků. Podporuje textová a transakční data. Podpora Vector Machine – Algoritmus strojového učení, podporuje textová a široká data. |
Atribut důležitost | Řadí atributy podle síly vztahu s cílovým atributem. Příklady použití zahrnují zjištění faktorů nejvíce spojených se zákazníky, kteří reagují na nabídku, faktorů nejvíce spojených se zdravými pacienty. | Minimální délka popisu – považuje každý atribut za jednoduchý prediktivní model cílové třídy a poskytuje relativní vliv. |
Oracle Data Mining Unsupervised Algorithms
| Technika | Použitelnost | Algoritmy |
|---|---|---|
Shlukování | Shlukování se používá k rozdělení záznamů databáze do podmnožin nebo shluků, kde prvky v clusteru sdílejí sadu společných vlastností. Příklady zahrnují hledání nových zákaznických segmentů a doporučení filmů. | K-Means – Podporuje dolování textu, hierarchické shlukování, založené na vzdálenosti. Shlukování ortogonálních oddílů – Hierarchické shlukování, založené na hustotě. Maximalizace očekávání – Technika shlukování, která dobře funguje při problémech s dolováním smíšených dat (hustých a řídkých). |
Detekce anomálií | Detekce anomálií identifikuje datové body, události a/nebo pozorování, které se odchylují od běžného chování datové sady. Mezi běžné příklady patří bankovní podvod, strukturální vada, zdravotní problémy nebo chyby v textu | Jednotřídní podpůrný vektorový stroj – trénuje neoznačená data a pokouší se určit, zda testovací bod patří do distribuce trénovacích dat. |
Výběr a extrakce funkcí | Vytváří nové atributy jako lineární kombinaci existujících atributů. Použitelné pro textová data, latentní sémantickou analýzu (LSA), kompresi dat, dekompozici a projekci dat a rozpoznávání vzorů. | Nezáporná maticová faktorizace – mapuje původní data do nové sady atributů Analýza hlavních komponent (PCA) – vytváří méně nových složených atributů, které představují všechny atributy. Singulární vektorová dekompozice – zavedená metoda extrakce rysů, která má širokou škálu aplikací. |
Asociace | Najde pravidla spojená s často se vyskytujícími položkami, která se používají pro analýzu tržního koše, křížový prodej a analýzu hlavních příčin. Užitečné pro sdružování produktů a analýzu vad. | Apriori – hashovaný strom za účelem shromažďování informací v databázi |
Povolení možnosti Oracle Data Mining
Od verze 12c Release 2 Oracle Advanced Analytics Volba zahrnuje funkce Data Mining a Oracle R.
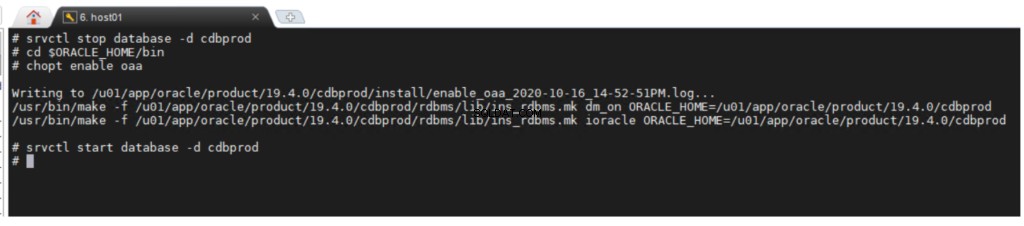
Možnost Oracle Advanced Analytics je standardně povolena během instalace Oracle Database Enterprise Edition. Pokud chcete povolit nebo zakázat možnost databáze, můžete použít nástroj příkazového řádku chopt .
chopt [ enable | disable ] oaa
Chcete-li povolit možnost Oracle Advanced Analytics:
Vytvoření tabulkového prostoru schématu ODM
Všichni uživatelé vyžadují stálý tabulkový prostor a dočasný tabulkový prostor, ve kterém mohou vykonávat svou práci. Může být velmi užitečné mít v databázi samostatnou oblast, kde můžete vytvářet všechny své objekty pro dolování dat.
usr_dm_01 schéma bude obsahovat všechna vaše díla dolování dat.
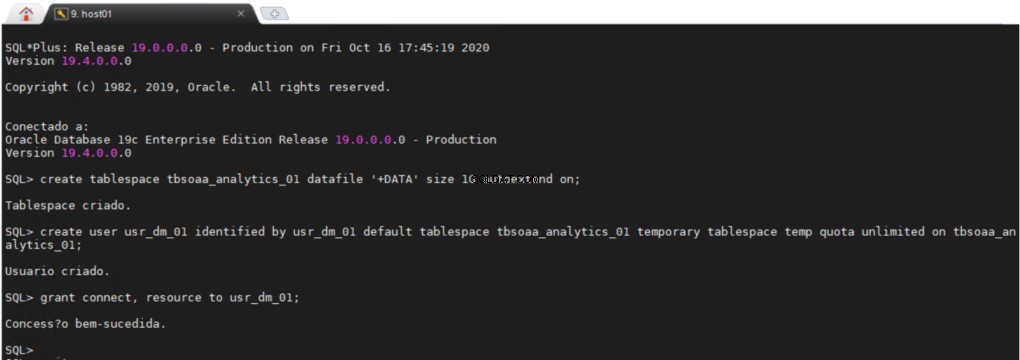
Vytvoření úložiště ODM
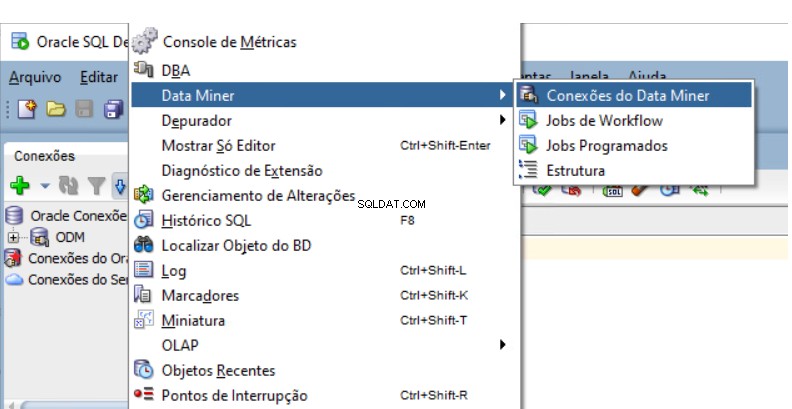
Musíte vytvořit Úložiště dolování dat Oracle v databázi. Přejděte na Data Miner Navigator v SQL Developer.
Vyberte View -> Data Miner -> Data Miner Connections:
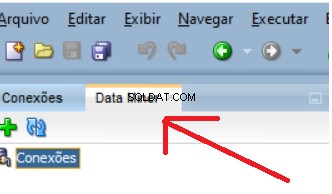
Vedle vaší stávající karty Připojení se otevře nová karta:
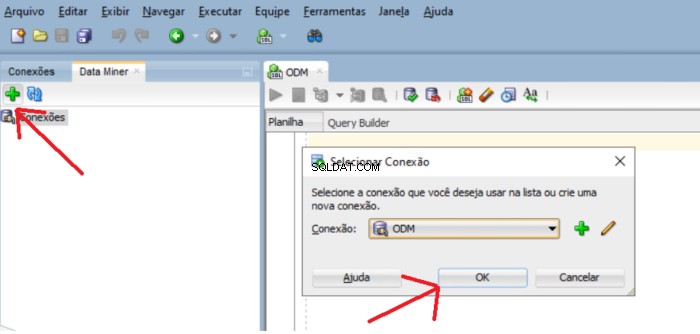
Chcete-li přidat usr_dm_01 schéma do tohoto seznamu, klikněte na zelené plus a OK
Pokud úložiště neexistuje, zobrazí se zpráva s dotazem, zda chcete úložiště nainstalovat. Klikněte na tlačítko Ano pokračujte v instalaci.
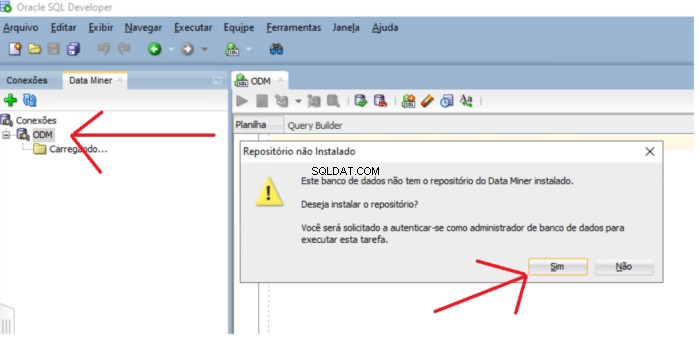
Musíte zadat heslo SYS
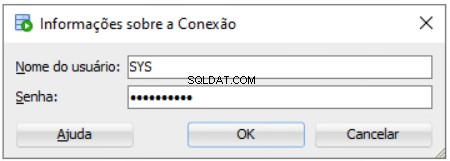
Nastavení instalace úložiště
Okno průběhu instalace Data Miner Repository
Úloha byla úspěšně dokončena
Soubor protokolu
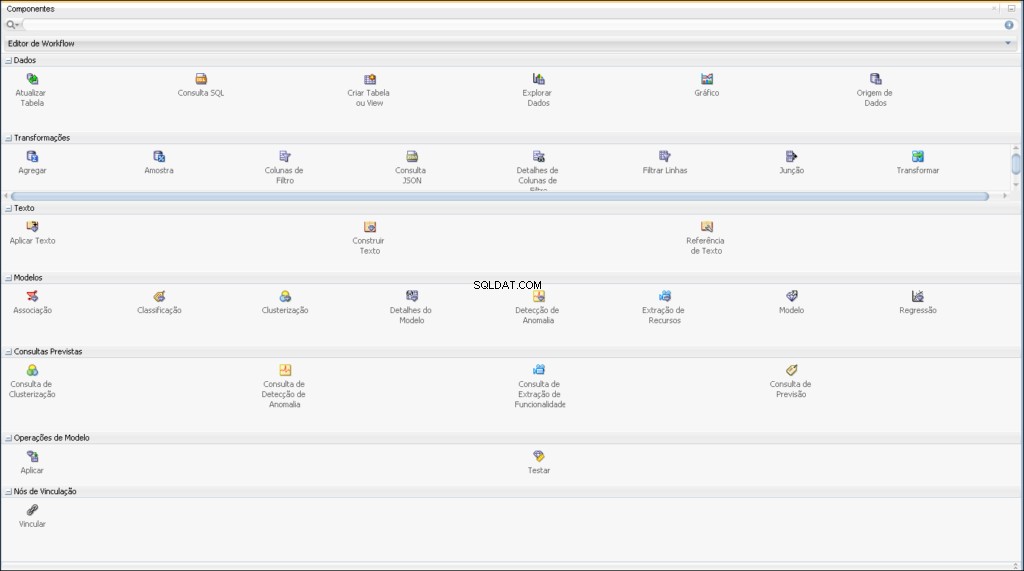
Komponenty pro dolování dat Oracle
Pracovní postup vám umožňuje vytvořit řadu uzlů, které provádějí všechna požadovaná zpracování vašich dat.
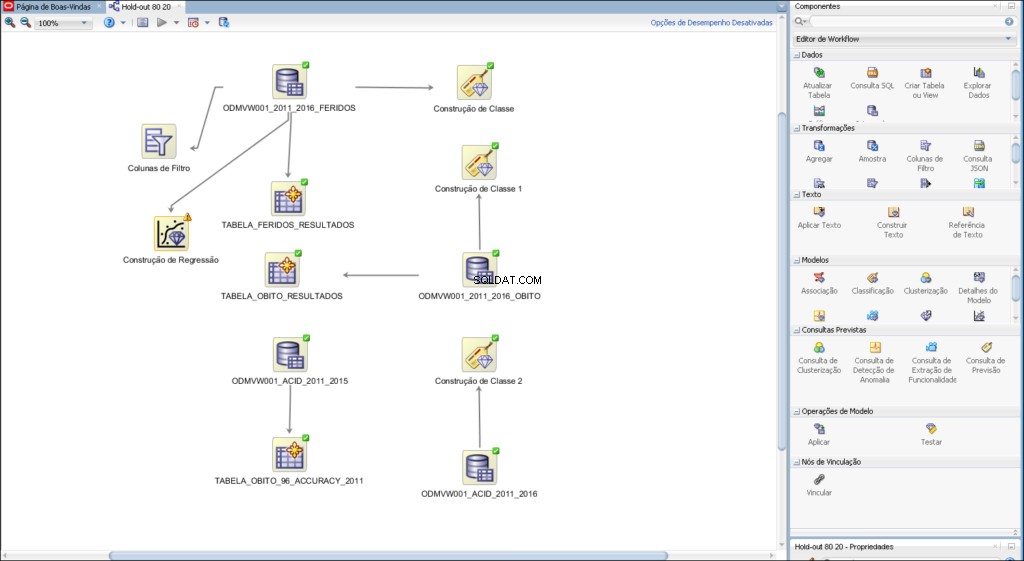
Příklad pracovního postupu vyvinutého pro prediktivní analytiku
Zobrazení datového slovníku ODM
Informace o modelech těžby můžete získat z datového slovníku.
Zobrazení datového slovníku dolování dat jsou shrnuta takto:
Poznámka:* lze nahradit ALL_, USER_, DBA_ a CDB_
*_MINING_MODELS :Informace o modelech těžby, které byly vytvořeny.
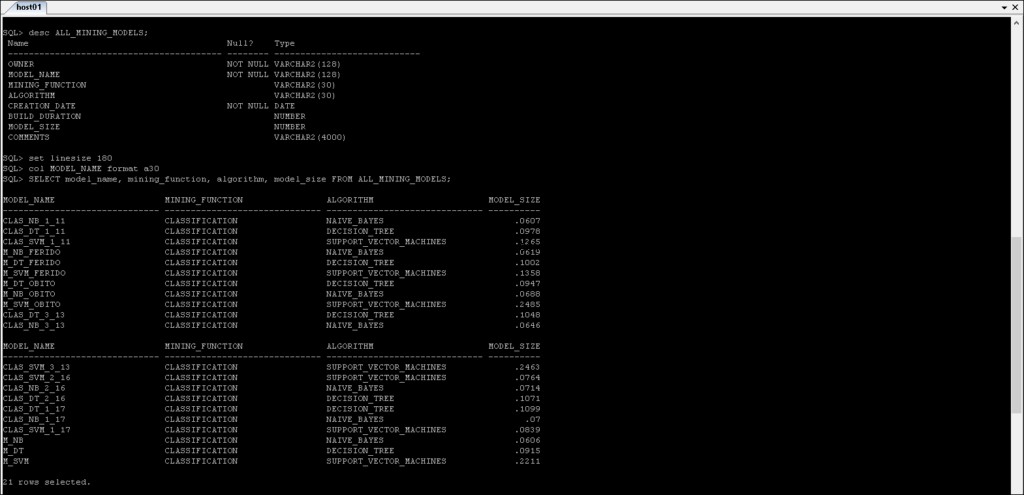
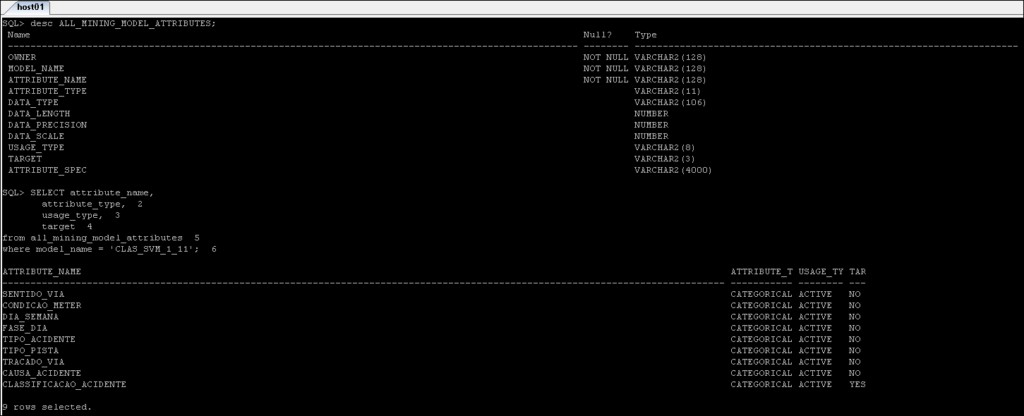
*_MINING_MODEL_ATTRIBUTES :Obsahuje podrobnosti o atributech, které byly použity k vytvoření modelu Oracle Data Mining.
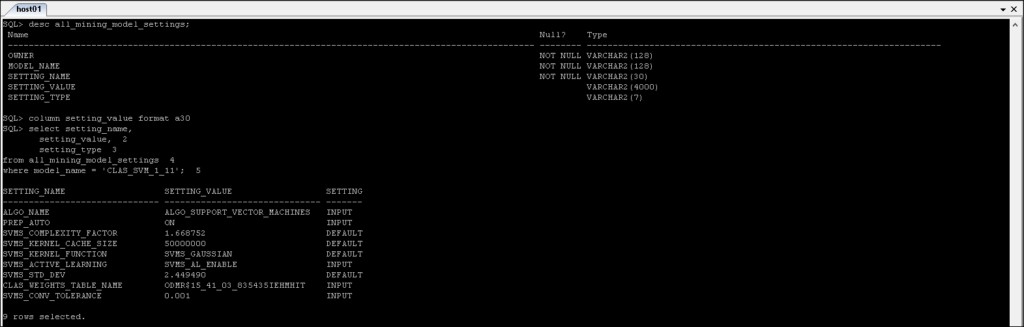
*_MINING_MODEL_SETTINGS :Vrátí informace o nastavení těžebních modelů, ke kterým máte přístup.
Odkazy
Uživatelská příručka Oracle Data Mining. Dostupné na:https://docs.oracle.com/en/database/oracle/oracle-database/19/dmprg/lot.html
Oracle Data Mining – škálovatelná prediktivní analytika v databázi. Dostupné na:https://www.oracle.com/database/technologies/advanced-analytics/odm.html
Přehled systému Oracle Data Miner. Dostupné na:https://docs.oracle.com/database/sql-developer-17.4/DMRIG/oracle-data-miner-overview.htm#DMRIG124