Parametry připojovacího řetězce pro zdroje textových souborů
V předchozím článku jsem se zabýval parametry připojovacího řetězce pro zdroje dat Excel. Nyní se zaměříme na textové soubory. Existují různé metody pro popis schématu textových souborů a použití informací během otevírání nebo propojování v Accessu. Zatímco tabulky Excelu měly určitou podobnost struktury, neplatí to pro textové soubory. Musíme odpovědět na několik otázek o struktuře textového souboru, včetně:
- Je šířka ohraničená nebo pevná?
- Jak poznáme, kdy jeden sloupec končí a druhý začíná?
- Je text citován nebo ne?
- Jak bychom měli analyzovat data a časy?
- A co částky v měně? Jak by měly být formátovány?
a možná i více. I když se na první pohled může zdát, že CSV je dobře definovaný, ale když se v něm prohrabete, je ve skutečnosti definován velmi volně. Neexistuje žádná univerzální dohoda o tom, zda by měl být text citován, jak by měla být formátována data. Ze všech těchto důvodů použití textových souborů obvykle vyžaduje použití určitého druhu informací o schématu k popisu struktury textového souboru. Existují tři způsoby, jak uložit informace o schématu:
- A
schema.inisoubor uložený v adresáři - Přístup k
MSysIMEXaMSysIMEXColumnstabulky - Získejte přístup k souboru
ImportExportSpecification.XMLvlastnictví.
Abychom to zkomplikovali, existuje několik různých metod, které můžeme použít k práci s textovými soubory, ale ne všechny metody mohou používat všechny 3 různé způsoby získání informací o schématu. Například DoCmd.TransferText pracuje se systémovými tabulkami, ale ne uloženými importy/exporty. Na druhé straně DoCmd.RunSavedImportExport pracuje s ImportExportSpecification objekt. Nicméně ImportExportSpecification se nepoužívá jako součást propojení. Takže pro naši diskusi máme ve skutečnosti k dispozici pouze 2 metody v kontextu otevření nebo propojení s textovým souborem. Je důležité si uvědomit rozdíl mezi uložením specifikace do MSysIMEXSpecs &MSysIMEXColumns tabulky vs. uložení importu/exportu, který se stane ImportExportSpecification objekt. Tyto 2 metody prozkoumáme v dalších článcích.
Připojovací řetězec pro textový soubor
Měli bychom zvážit, jak bude Access vnímat textový soubor. V předchozím článku jsme viděli, že každý list nebo pojmenovaný rozsah byl reprezentován jako „tabulka“ v „databázi tabulkového procesoru Excel“. Ale textový soubor žádnou takovou konstrukci nemá. Co tedy tvoří „databázi“? Odpověď zní, že složka představuje „databázi“, a proto všechny textové soubory ve složce jsou „tabulky“. Z tohoto důvodu je možné mít více informací o schématu pro stejnou složku, pokud tato složka obsahuje více než jeden možný formát pro jakékoli textové soubory uložené ve složce. Později uvidíte, že když vytvoříme připojovací řetězec, propojíme se se složkou a poté přistoupíme k jednotlivému souboru jako k tabulce.
Proto použijte toto nastavení, jak je uvedeno:
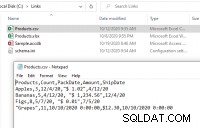
Potom můžeme otevřít textový soubor pomocí tohoto kódu VBA:
Dim db As DAO.Database
Set db = DBEngine.OpenDatabase(vbNullString, False, False, "Text;DATABASE=C:\Links")
Dim tdf As DAO.TableDef
For Each tdf In db.TableDefs
Debug.Print tdf.Name
Dim fld As DAO.Field
For Each fld In tdf.Fields
Debug.Print fld.Name,
Next
Debug.Print
Dim rs As DAO.Recordset
Set rs = tdf.OpenRecordset
Do Until rs.EOF
For Each fld In rs.Fields
Debug.Print fld.Value,
Next
Debug.Print
rs.MoveNext
Loop
Debug.Print
Next Výsledkem by měl být výstup:
Products#csv Products Count PackDate Amount ShipDate Apples 3 12/4/2020 $ 1.02 4/12/2020 Bananas 5 4/12/2020 $ 1,234.56 12/4/2020 Figs 8 5/7/2020 $ 0.01 7/5/2020 Grapes 11 10/10/2020 $12.30 10/10/2020
Vezměte na vědomí následující věci:
- V našem připojovacím řetězci jsme nezadali textový soubor. Místo toho jsme použili složku.
- Názvy „tabulek“ byly změněny, protože tečka v názvu není platný znak. Tedy
products.csvse stalyproducts#csv. - Ve srovnání s aplikací Excel neexistují žádné povinné parametry kromě určení ovladače textového souboru a cesty ke složce.
V dalším článku se dozvíte více o popisu schématu textových souborů. Pro samotný připojovací řetězec jsou však rozpoznána následující klíčová slova.
FMT parametr:Označuje formát textového souboru.
Delimited :Soubor je oddělen znakem. Použitý znak je určen informací o schématu.
Fixed :Soubor má pevnou šířku sloupců. Opět platí, že konkrétní šířka(y) sloupce je určena informacemi o schématu.
HDR parametr:řádek záhlaví
YES :První řádek je záhlaví a měl by se stát názvy sloupců pro „table“/“recordset“
NO :S prvním řádkem se nezachází jinak a je to pouze údaj. Všechny názvy sloupců budou pojmenovány „FN“, kde „N“ je číslo začínající 1
IMEX parametr:Import/Export Behavior
To určuje, jak by měly být definovány datové typy sloupců na základě obsahu:
1 :Pokud sloupec obsahuje různé datové typy, zacházejte s ním jako s řetězcem. V opačném případě přiřaďte sloupec nejlepšímu datovému typu.
2 :Vždy přiřaďte sloupec k určitému datovému typu na základě vzorku. To může způsobit chybu při čtení, když čteme řádek obsahující data, která neodpovídají očekávanému datovému typu.
ACCDB parametr:Označuje, že Access používá formát souboru ACCDB?
Ve výchozím nastavení je toto vždy nastaveno na ACCDB=YES ve formátu souboru accdb. Zdá se však, že jeho vynechání nebo nastavení na NE nic neudělá. Je to trochu záhada. Pokud se někdo může podělit o vliv tohoto parametru, napište do komentáře a já aktualizuji blog.
DATABASE parametr:Cesta ke složce, která obsahuje textové soubory
Parametr by měl obsahovat plně kvalifikovanou cestu. Neměl by obsahovat názvy textových souborů.
CharacterSet Parametr:Identifikuje kódování znaků, které se má použít pro čtení textových souborů.
O tom bude podrobněji pojednáno v dalším článku. To lze také popsat v informacích o schématu.
DSN Parametr:Identifikuje informace o schématu, které se mají použít s textovým souborem.
Název musí odpovídat MSysIMEXSpec , který bude analyzován v dalším článku. Toto funguje pouze s MSysIMEX*** tabulky. Pokud chcete použít schema.ini , jednoduše nezahrnete žádné DSN ve vašich připojovacích řetězcích.
Je důležité si uvědomit, že ovladač textového souboru bude brát v úvahu pouze parametry uvedené výše. Není možné vložit jiná klíčová slova a nechat je analyzovat ovladačem textového souboru. Z tohoto důvodu nebudete moci zadat všechny podrobnosti o textovém souboru pouze z připojovacího řetězce.
Výchozí schéma pro textové soubory
Teoreticky můžete otevřít nebo propojit textový soubor bez jakýchkoli informací o schématu, ale to bude fungovat jen zřídka. V této situaci Access jednoduše převezme výchozí hodnoty pro různé možnosti. Pokud textový soubor vyhovuje všem aktuálním výchozím hodnotám, Access uspěje při čtení souboru. Ještě důležitější je, že absence chyb při otevírání nebo odkazování na textový soubor neznamená, že jsou data reprezentována smysluplně. Částky ve speciálně formátované měně mohou být například interpretovány jako text, nikoli jako měna, a neoddělený text s čárkami v textu může být špatně analyzován a mohou přidávat nežádoucí sloupce. Výchozí hodnoty jsou určeny na dvou možných místech:
- Access se podívá na nastavení registru. Pro instalaci Office 365 může být registr umístěn na adrese:
Computer\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office\ClickToRun\REGISTRY\MACHINE\Software\Microsoft\Office\16.0\Access Connectivity Engine\Engines\Text. Toto umístění budeme v dalších článcích označovat jako „Klíče textového registru“. - Nastavení, která uvidíte v
Regionappletu v ovládacím panelu Windows. Toto umístění budeme nazývat „Nastavení systému Windows“.

Poznámka ke kódování pro textové soubory
Správné kódování je povinné bez ohledu na to, jaké metody můžete použít pro přístup k textovým souborům. Když je obsah vašeho textového souboru omezen pouze na znaky v rámci spodní poloviny ASCII bodů (např. 0-127), nezáleží na tom, jaké kódování pro textové soubory zvolíte. Výchozí nastavení je obvykle dostačující. Pokud však vaše textové soubory mohou obsahovat jakýkoli kód Unicode nebo jakékoli znaky větší než 127, pak je na vás, vývojáři, abyste znali kódování. Pokud je zadáno nesprávné kódování, text se nemusí importovat podle očekávání a nevyvolá žádné chyby. Pro chaotické podrobnosti vás v této záležitosti odkážu na Joela Spolského.
Výběr mezi schema.ini a MSysIMEX*** tabulky
Jak uvidíte v dalších článcích, obě metody mají poměrně velký přesah ve schopnostech. Proto můžete zjistit, že máte na výběr z obou. Hlavní rozdíl spočívá v tom, zda chcete, aby bylo schéma uloženo ve vaší aplikaci nebo ve složce, kde se očekává, že budou textové soubory. Když použijete schema.ini soubor, předpokládáte, že textové soubory budou přítomny v určité složce a budou mít určité jméno.
Pomocí MSysIMEX*** , můžete zpracovávat libovolné textové soubory odkudkoli jednoduše odkazem na definovanou specifikaci. Upravit specifikaci mimo Access však není snadné. Dokonce ani v rámci Accessu není snadné vyladit specifikace pomocí uživatelského rozhraní. Soubor schema.ini má některé další funkce, které nejsou přímo dostupné s MSysIMEX*** tabulky.
Nicméně otázka, kam specifikaci uložit, bude pravděpodobně nejdůležitějším faktorem při rozhodování, kterou použít.
Závěr
Důrazně se doporučuje, abyste měli definované informace o schématu pro všechny textové soubory, které obsahují data nebo částky v měně. Data a částky v měně jsou citlivé na místní nastavení, což může narušit správnou analýzu dat. Protože máme dva různé systémy s různou dostupnou sadou možností, musíme každý zvážit v dalších článcích. Máte na výběr, zda použijete jeden (nebo dokonce oba mezi různými textovými soubory). Nyní se podíváme na schema.ini v dalším článku. Později se podíváme na MSysIMEX*** tabulky v následujícím článku.