Plánování kapacit pomocí údajů o výkonu
Odhadovaný počet řádků ke čtení
Komprese a její vliv na výkon
Výkonnostní překvapení a předpoklady:GROUP BY vs. DISTINCT
Jeden způsob, jak získat hledání indexu pro vedoucí % zástupný znak
Následný krok č. 1 při hledání vedoucích zástupných znaků
Minimalizace dopadu rozšíření sloupce IDENTITY – část 4
Rozšíření použití DBCC CLONEDATABASE
Pattern Matching:Více zábavy, když jsem byl dítě
Webinář Plan Explorer 3.0 – ukázky a otázky a odpovědi
Druh, který se rozlije na úroveň 15 000
SQL Sentry je nyní SentryOne
Implementace vlastního řazení
Migrace databází do Azure SQL Database
Mohou komentáře bránit výkonu uložené procedury?
Trendy databázového hardwaru a infrastruktury
Je vyhledávání RID rychlejší než vyhledávání klíčů?
Vnitřnosti WITH ENCRYPTION
Vylepšená podpora pro paralelní statistické přestavby
Varování Počet přečtených řádků / Skutečné přečtení řádků v Průzkumníku plánů
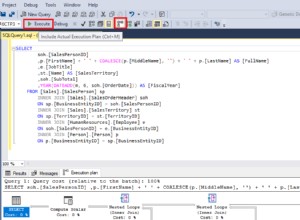
Porovnejte prováděcí plány na serveru SQL Server
Sqlserver
Co je to vztah jeden k mnoha v databázi? Vysvětlení s příklady
Database
Optimalizace dotazů SQL — Jak zjistit, kdy a zda je to potřeba
Sqlserver
Vyrovnávací paměti (kruh) v PostGIS
PostgreSQL
Nenačtení seznamu schémat ze zdroje při migraci z MSSQL do MySQL pomocí Workbench
Mysql
jak zajistit, aby vývojář sql zobrazoval neanglické znaky správně namísto zobrazování čtverců?
Oracle